
Was sind eigentlich relationale Datenbanken?
")
(Foto: Shutterstock.com)
Relationale Datenbanken: Die Idee dahinter
Eine relationale Datenbank besteht aus beliebig vielen Tabellen, in denen logisch zusammenhängende Objekte – Daten wie Stammdaten oder Prozessdaten – gespeichert werden. Ein Datenbank-Management-System dient zur Verwaltung und Nutzung der in der Datenbank gespeicherten Daten.
Relationale Datenbanken haben den Vorteil, dass Redundanzen, also die mehrfache Speicherung gleicher Daten, und Inkonsistenzen, Probleme bei der Aktualisierung mehrfach gespeicherter Datensätze, verhindert werden.
Anforderungen an relationale Datenbanken
Eine Datenbank muss konsistent und redundanzfrei sein. Das bedeutet, jeder Datensatz muss eindeutig identifizierbar sein und alle Daten werden nur ein mal erfasst und gespeichert. Um das du erreichen, werden Datensätze auf mehrere Tabellen verteilt – hierbei werden Normalformen unterschieden. Was Normalformen sind und wie eine Normalisierung erfolgt, wird später erklärt – vorerst einige Grundbegriffe.
Grundbegriffe
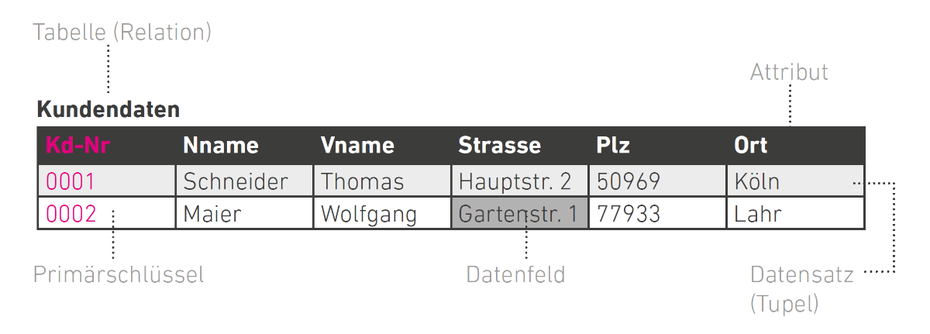
Relationale Datenbanken: Aufbau und Beschreibung des Prinzips. (Grafik: t3n)
Der Begriff relationale Datenbank steht für eine der wichtigsten Untergruppen von Datenbanken. Sie besteht aus mindestens einer – meist aber mehreren – Tabellen, das sind Relationen. Andere Datenbanken unterscheiden sich, indem sie entweder hierarchisch oder objektorientiert sind.
Ein ganzer Datensatz wird als Tupel bezeichnet und besteht aus mehreren Datenfeldern wie zum Beispiel dem Vornamen, Nachnamen oder der E-Mail Adresse. Jeder Datensatz muss über einen Schlüssel eindeutig identifizierbar sein – zum Beispiel mit einer Kundennummer.
Alle einzelnen Datenfelder sind einer Kategorie zugeordnet, diese nennt man Attribute. Ein Attribut kann die Kundennummer, der Vorname, der Nachname oder die Straße sein.
Weiter oben haben wir schon den „Schlüssel“ erwähnt. Er dient zur eindeutigen Identifizierung eines Datensatzes. Daher wird in jeder Tabelle mindestens ein Schlüssel benötigt. Man unterscheidet zwischen zwei gängigen Schlüsseln:
Primärschlüssel
Er kann innerhalb einer Tabelle nur ein mal verwendet werden und dient zur Identifikation der Tupel. Dieser Schlüssel sollte so gewählt sein, dass seine Werte sich nicht ändern. Das kann zum Beispiel die Straße – sie darf aber nur ein mal vorkommen – verbunden mit der Hausnummer sein.
Ein Primärschlüssel muss stabil sein, das bedeutet: Während der Lebenszeit der Relation (Tabelle), dürfen sich die Schlüsselwerte nicht ändern – weil das Folgen bei den zugehörigen Fremdschlüsselwerten hätte.
Fremdschlüssel
Ein Fremdschlüssel ist ein Verweis auf einen Primärschlüssel einer anderen Tabelle oder innerhalb der selben Tabelle.
Angenommen, in Tabelle A gibt es ein Attribut mit eindeutigen Kundennummern und in Tabelle B ebenfalls ein Attribut mit Kundennummern, dann wäre diese Beziehung ein Fremdschlüssel. Innerhalb der Tabelle B kann unter dem Attribut Kundennummer ein Primärschlüssel bestehen – und auf den Vornamen, Nachnamen und die Straße verweisen.
Relationale Datenbanken: Das Entity-Relationship-Modell
Dieses Modell ist ein Entwurfsverfahren, um schon beim Datenbankentwurf dafür zu sorgen, dass sich eine konsistente und redundanzfreie Datenbank ergibt – es wird zwischen drei verschiedenen Modell-Typen unterschieden:
- 1:1-Beziehung: Jede Entität ist höchstens einer anderen zugeordnet
- 1:n-Beziehung: Einer Entität stehen keine, eine oder mehrere Entitäten gegenüber
- m:n-Beziehung: Auf beiden Seiten stehen mehrere Entitäten in Beziehung zueinander
Das Prinzip der Normalisierung
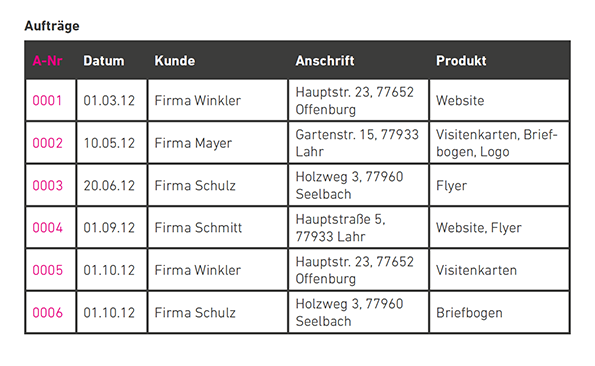
Durch die ganze Anschrift in einem Datenfeld ist eine Sortierung nach der Postleitzahl nicht möglich. (Grafik: t3n)
Bevor Schlüssel vergeben werden, müssen Tabellen in die Normalform gebracht werden. Das bedeutet, um Konsistenz und Redundanzfreiheit zu erreichen, werden Datensätze auf mehrere Tabellen verteilt. Es wird zwischen fünf Normalformen unterschieden – relevant sind nur drei:
1. Normalform
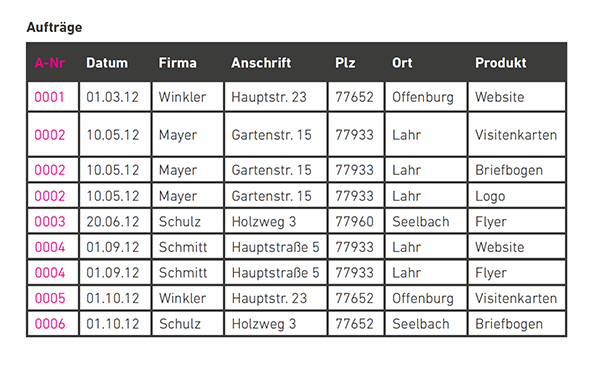
Jedes Datenfeld enthält einen eigenen Eintrag. (Grafik: t3n)
Eine Tabelle befindet sich in der ersten Normalform, wenn jedes Datenfeld nur einen Eintrag enthält.
2. Normalform
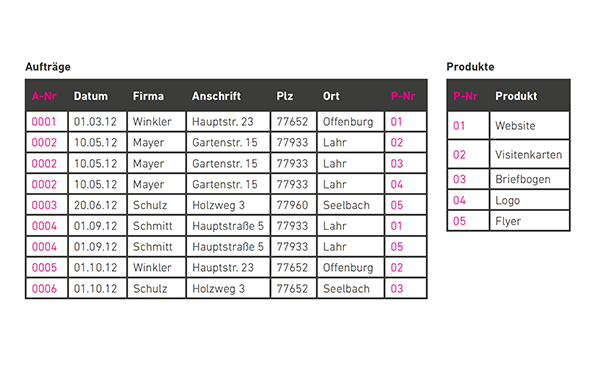
A-Nr und P-Nr stellen keine funktionale Abhängigkeit her – erst durch die zweite Tabelle. Aufgrund doppelter Namen ist die Tabelle noch nicht redundanzfrei. (Grafik: t3n)
Eine Tabelle befindet sich in der zweiten Normalform, wenn sie sich in der ersten Normalform befindet und alle Datenfelder von einem (zusammengesetzten) Schlüssel funktional abhängig sind.
Die Tabelle „Produkte“ besitzt einen Schlüssel (P-Nr), von dem das Attribut „Produkt“ funktional abhängig ist. Sprich: Zu jeder Produktnummer gibt es genau ein Produkt.
3. Normalform
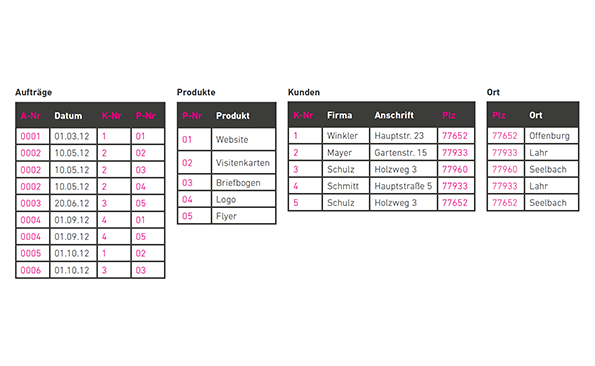
Durch abhängige Schlüssel sind alle Datenfelder eindeutig identifizierbar – redundanzfrei und konsistent. (Grafik: t3n)
Eine Tabelle befindet sich in der dritten Normalform, wenn sie sich in der zweiten Normalform befindet und alle Datenfelder, die keine Schlüssel sind, nicht funktional abhängig sind.
In der zweiten Normalform sind die Kundenangaben funktional abhängig – in der dritten Normalform ist das nicht erlaubt. Es könnte vorkommen, dass ein Kunde mit dem selben Nachnamen etwas bestellt, dann würde der eindeutige Schlüssel nicht mehr funktionieren. Daher wird eine weitere Tabelle mit einem neu definierten Schlüssel erstellt.
Viele Tabellen bringen aber auch einen Nachteil – es entsteht eine verschlechterte Lesbarkeit mit jeder neuen Tabelle. Für solche Fälle werden Datenbank-Management-Systeme benötigt, die sich um die Verwaltung und Orientierung kümmern.
Letztes Update des Artikels: 18. August 2017

Bitte beachte unsere Community-Richtlinien
Wir freuen uns über kontroverse Diskussionen, die gerne auch mal hitzig geführt werden dürfen. Beleidigende, grob anstößige, rassistische und strafrechtlich relevante Äußerungen und Beiträge tolerieren wir nicht. Bitte achte darauf, dass du keine Texte veröffentlichst, für die du keine ausdrückliche Erlaubnis des Urhebers hast. Ebenfalls nicht erlaubt ist der Missbrauch der Webangebote unter t3n.de als Werbeplattform. Die Nennung von Produktnamen, Herstellern, Dienstleistern und Websites ist nur dann zulässig, wenn damit nicht vorrangig der Zweck der Werbung verfolgt wird. Wir behalten uns vor, Beiträge, die diese Regeln verletzen, zu löschen und Accounts zeitweilig oder auf Dauer zu sperren.
Trotz all dieser notwendigen Regeln: Diskutiere kontrovers, sage anderen deine Meinung, trage mit weiterführenden Informationen zum Wissensaustausch bei, aber bleibe dabei fair und respektiere die Meinung anderer. Wir wünschen Dir viel Spaß mit den Webangeboten von t3n und freuen uns auf spannende Beiträge.
Dein t3n-Team
Korrektur: „Tupel“, nicht „Tulpel“.
(Kommentar kann gerne wieder gelöscht werden)
Ai! Danke für den Hinweis – wurde geändert.
Hallo,
müsste die Orts-Tabelle in der 3. Normalform nicht auch eindeutige Werte enthalten? Die Tupel von Lahr und Seelbach sind dort dublett.
… sind dort dublett xD
Hi,
man darf sich durch den gleichen Text nicht beirren lassen (die Spalte ist weder ein PK-Feld noch „Unique“).
Formal sind zwei verschiedene Orte die zufällig gleich heißen könnten.
Genau so wie Taufkirchen oder Neunkirchen.
Das finde ich kann man guten Gewissens so lassen.
Grüße!
Zu der ersten Normalform gehört auch die Atomisierung. Deswegen könnte es Sinn machen die Straße von der Hausnummer zu trennen.