

Was ist KI und was „echt“? Große Sprachmodelle, sogenannte LLM, kommen dem Menschen immer näher. Hier dient der beliebte, aber umstrittene Turing-Test als Benchmark. In dem Test müssen die Sprachmodelle Teilnehmende erfolgreich täuschen, ein Mensch zu sein.
In einem Preprint-Forschungspapier mit dem Titel „Does GPT-4 Pass the Turing Test?“ haben zwei Forscher der UC San Diego das KI-Sprachmodell GPT-4 gegen menschliche Teilnehmer, GPT-3.5 und Eliza antreten lassen. Gewonnen hat zwar immer noch der Mensch, doch die neue Sprach-KI von OpenAI konnte sehr viele Menschen täuschen.
Besonders verblüffend ist allerdings ein anderes Ergebnis: Der Chatbot Eliza, der im Jahr 1966 entwickelt wurde, schaffte es, mehr Leute von seiner Menschlichkeit zu überzeugen als GPT 3.5.
Das ist der Turing-Test
Mithilfe des Turing-Tests wollten die Forscher herausfinden, wie menschlich die Chatbots wirken. Benannt ist der Test nach dessen Erfinder Alan Turing, der 1950 eine Idee hatte, wie wie man feststellen könne, ob ein Computer ein dem Menschen gleichwertiges Denkvermögen hat. Turing nannte diesen Test ursprünglich Imitation Game.
In der Version, die die Forscher verwendet haben, wurden den Proband:innen zwei Rollen zugewiesen: Entweder sollten sie als Ermittler herausfinden, ob sie mit einer KI oder einem Menschen chatten, oder als Zeuge ihr Gegenüber von ihrer Menschlichkeit überzeugen.
Neben menschlichen Zeugen gab es 25 LLM-Zeugen, die sich nicht nur vom Modell her, sondern auch durch unterschiedliche Prompts unterschieden. Wer ermittelt, konnte neben der Einschätzung, ob das Gegenüber ein Mensch ist, auch noch eine Begründung und die Sicherheit der Antwort angeben. Insgesamt absolvierten 652 Teilnehmende insgesamt 1.810 „Imitationsspiele“.
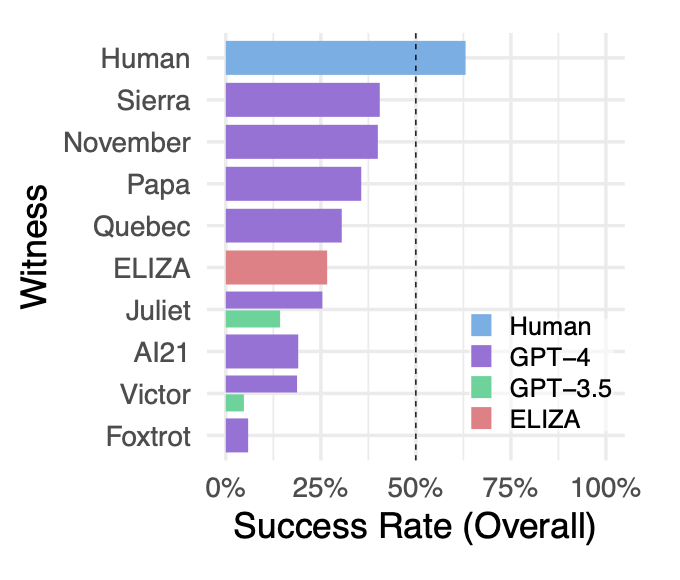
Besonders gut haben die GPT-4-Chatbots mit den Namen Sierra und November abgeschnitten. An einen Menschen kommt bislang noch keine KI ran. (Screenshot: UC San Diego/t3n)
Überraschenderweise schnitt Eliza, ein Sprachmodell aus den 1960ern, in der Studie relativ gut ab und erreichte eine bessere Erfolgsquote als GPT-3.5 – unabhängig vom Prompt. Laut Princeton-Informatikprofessor Arvind Narayanan sagen die Ergebnisse nicht viel aus. Seiner Meinung nach fehle es an Kontext in der Studie. Auf X schreibt er: „ChatGPT ist so abgestimmt, dass es einen formalen Ton hat, keine Meinungen ausdrückt usw., was es weniger menschlich macht. Die Autoren haben versucht, dies mit den Prompts zu ändern, diese haben aber ihre Grenzen. Der beste Weg, einen menschlichen Chat vorzutäuschen, ist eine Feinabstimmung auf menschliche Chatprotokolle.“
Letztendlich erfüllt auch GPT-4 wegen der Erfolgsquote von unter 50 Prozent nicht die Erfolgskriterien des Turing-Tests. Trotzdem denken die Forscher, dass GPT-4 oder ähnliche Modelle mit dem richtigen Prompt-Design den Turing-Test schließlich bestehen könnten. Manche Expert:innen rechnen damit, dass ab GPT-5 eine sogenannte künstliche allgemeine Intelligenz (Artifical General Intelligence, AGI) werden könnte, die einem menschlichen Gehirn zum Verwechseln ähnlich wäre.

Bitte beachte unsere Community-Richtlinien
Wir freuen uns über kontroverse Diskussionen, die gerne auch mal hitzig geführt werden dürfen. Beleidigende, grob anstößige, rassistische und strafrechtlich relevante Äußerungen und Beiträge tolerieren wir nicht. Bitte achte darauf, dass du keine Texte veröffentlichst, für die du keine ausdrückliche Erlaubnis des Urhebers hast. Ebenfalls nicht erlaubt ist der Missbrauch der Webangebote unter t3n.de als Werbeplattform. Die Nennung von Produktnamen, Herstellern, Dienstleistern und Websites ist nur dann zulässig, wenn damit nicht vorrangig der Zweck der Werbung verfolgt wird. Wir behalten uns vor, Beiträge, die diese Regeln verletzen, zu löschen und Accounts zeitweilig oder auf Dauer zu sperren.
Trotz all dieser notwendigen Regeln: Diskutiere kontrovers, sage anderen deine Meinung, trage mit weiterführenden Informationen zum Wissensaustausch bei, aber bleibe dabei fair und respektiere die Meinung anderer. Wir wünschen Dir viel Spaß mit den Webangeboten von t3n und freuen uns auf spannende Beiträge.
Dein t3n-Team
Liegt vielleicht auch daran, dass die Probanden zwar GPT kennen und dessen typische Ausdrucksweise aber ELIZA, die zwar sehr schlechte aber sehr menschlich wirkende Antworten gibt (was damals der Fokus war), nicht kennen.