





Logfile-Analysen im SEO: Wie verhalten sich Crawler wirklich auf meiner Website? (Teil 2)
")
(Foto: Shutterstock / Dominik Bruhn)
Nach der grundsätzlichen Einleitung in den Hintergrund, Nutzen und die Aufbereitung von Logfiles für Logfile-Analysen im SEO geht es im zweiten Teil dieses Beitrages um die Analyse selbst. Die dargestellten Punkte sollen als grundsätzliche Ausgangsauswertungen angesehen werden. Je nach Website oder gefundenen Erkenntnissen empfiehlt es sich, tiefergehende Analysen zu erstellen. Trotzdem sind diese Punkte wichtige Eckpfeiler, die bei jeder Website betrachtet werden sollten und oftmals bereits wesentliche Einblicke über Crawling-Verhalten und Potenziale bilden können.
HTTP-Statuscodes in einer Logfile-Analyse
Statuscodes sind mitunter das Erste, was ein Crawler bei Abruf einer Seite als Antwort erhält. Dabei wird durch den Statuscode mitgeteilt, ob eine URL erreichbar ist, auf eine andere URL weiterleitet oder nicht mehr erreichbar ist. Die Auswertung der Statuscodes gibt dabei einen Überblick, ob potenzielle strukturelle Probleme bestehen, weil übermäßig viele URL mit einem anderen Statuscode als 200 aufgerufen werden oder auf den ersten Blick soweit alles in Ordnung ist.
Generell lautet das Ziel: Möglichst viele oder im Bestfall alle URL antworten mit einem Statuscode 200. Dieser besagt, dass der Aufruf erfolgreich bearbeitet wurde und die Antwort übertragen werden konnte. Da sich Webseiten aber verändern, Seiten entfernt oder auch weitergeleitet werden, ist das grundsätzlich absolut normal, wenn URL auch mit einem anderen Statuscode als 200 antworten. Jedoch ist die relative Menge der anders antwortenden URL von Bedeutung und kann Aufschluss über Probleme geben.
Der Statuscode 301 besagt, dass die aufgerufene URL permanent auf eine andere URL weitergeleitet wurde. Dieses Vorgehen ist üblich, wenn eine Webseite umgezogen wird oder einzelne Kategorien beziehungsweise Seiten auf neue Adressen weitergeleitet werden. Dabei ist es jedoch wichtig zu verstehen, dass jeder Aufruf einer weiterleitenden URL und der folgende Aufruf auf die eigentliche Ziel-URL, die mit 200 antwortet, in zwei einzelnen Aufrufen resultiert – der ersten URL mit 301 und der zweiten mit 200. Das Crawlbudget ist aber pro Webseite begrenzt. Das bedeutet, dass für den Aufruf einer URL zwei Zugriffe notwendig sind und sich das somit negativ auf das Crawlbudget niederschlagen kann. Manche Weiterleitungen lassen sich nicht umgehen und sind notwendig. Insbesondere bei der internen Verlinkung sollten jedoch nur URL mit einem Status Code 200 verwendet werden.
Der dritthäufigste auftretende oder auf den ersten Blick wichtigste Statuscode ist 404. Dieser besagt, dass eine URL beziehungsweise die angeforderte Ressource nicht gefunden werden kann. Generell ist es natürlich, dass durch die Entwicklung einer Website einige Seiten nicht mehr aufrufbar sind. Das können beispielweise nicht mehr wiederkehrende Produkte oder gelöschte Beiträge sein. Eine übermäßig hohe Anzahl an 404-Statuscodes im Verhältnis zu den gesamten Statuscodes kann aber auch auf strukturelle Probleme hinweisen.
Im Idealfall ist die Zahl der mit 404 antwortenden URL so gering wie möglich. Wenn die Ressource hinter einer URL langfristig nicht mehr vorhanden ist, empfiehlt sich der Einsatz des 410-Statuscode. Dieser weist Crawler daraufhin, dass der Inhalt nicht mehr wiederkehrt und verringert folglich das Crawling der URL. Bei einem 404-Statuscode kann eine URL noch lange Zeit weiterhin gecrawlt werden – je nach vorheriger Wichtigkeit, weil es nicht eindeutig ist, ob die Inhalte wieder verfügbar sein werden.
Weitere mögliche Statuscodes in einer Logfile-Analyse
Die folgende Abbildung zeigt einen Ausschnitt aus einer Google-Data-Studio-Lösung für die Analyse von Logfiles. Zu sehen ist: ein relativ normaler Verlauf von ausgegebenen Statuscodes mit temporären Anstiegen an einzelnen Tagen über den Zeitraum von knapp einem Monat innerhalb eines Shops. Sollten bei einer solchen Auswertung einzelne Statuscodes überwiegen, gilt es, die Herkunft dieser zu hinterfragen.
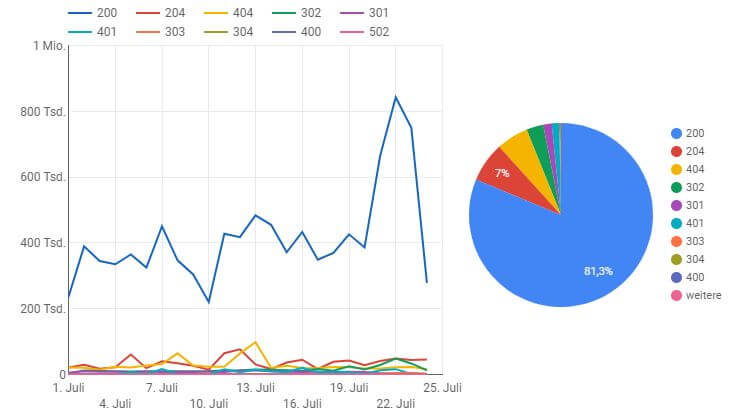
Statuscodes eines Logfiles in einer Google-Data-Studio-Lösung. (Screenshot: Google)
Neben den dargestellten Statuscodes gibt es noch eine Vielzahl weiterer möglicher Statuscodes, die mitunter von Bedeutung für SEO sein können, wie 302-Weiterleitungen (temporäre Weiterleitungen) oder 5xx-Statuscodes, die für Serverfehler stehen. Letztere können auch ein Indiz für Probleme mit der Serverarchitektur sein, die die Crawleffizienz verringern und auch für Nutzer problematisch sind.
Der 302-Statuscode kann ein größeres Problem darstellen. Zwar muss dieser manchmal sinngemäß für temporäre Weiterleitungen eingesetzt werden, wird aber auch für eigentlich permanente Weiterleitungen benutzt. Das Problem ist, dass dadurch Signale wie bestehende Rankings der originären URL nicht auf die neue Ziel-URL übertragen werden. Zusätzlich wird die Übertragung der internen Linkstärke gehemmt und im Zweifelsfalle gestoppt.
Parameter und ihre Bedeutung in Logfile-Analysen
Parameter werden häufig zur Generierung von speziellen Inhalten benutzt, wenn absolute URL nicht möglich sind, wie beispielweise bei gefilterten Seiten (Farb-, Preisfilter und ähnliches) oder internen Suchergebnisseiten. Generell gibt es eine Vielzahl von Einsatzgebieten von Parametern, zum Beispiel Tracking-Parameter – um den Ursprung eines internen oder externen Zugriffs zu überprüfen – oder für Seiten innerhalb einer Serie von Blätterseiten (Seite 1, Seite 2, Seite 3 und so weiter).
Grundsätzlich ist es für Suchmaschinen irrelevant, welche Zeichen in einer URL stehen. Jegliche Abweichungen wie Klein- und Großschreibung oder Sonderzeichen erzeugen zunächst eine eigenständige Adresse und werden auch so von Suchmaschinen verstanden. Das heißt, dass Crawler sie crawlen, um die dort auffindbaren Inhalte zu erfassen.
Da durch die Kombinationsmöglichkeiten einzelner URL und der Vielzahl von Parametern eine extrem hohe Menge von URL entstehen kann, gilt es, diesen Punkt zu überwachen. Jene URL müssen es in der Regel von der Indexierung ausgeschlossen werden, da sie oftmals nur doppelte Inhalte von bereits vorhandenen Seiten mit gegebenenfalls geringfügiger Änderung darstellen oder gar keine Suchmaschinenrelevanz haben. Selbst wenn diese URL von der Indexierung ausgeschlossen sind, kann die schiere Anzahl an möglichen URL die Crawleffizienz und das Crawling primärer Seiten einschränken.
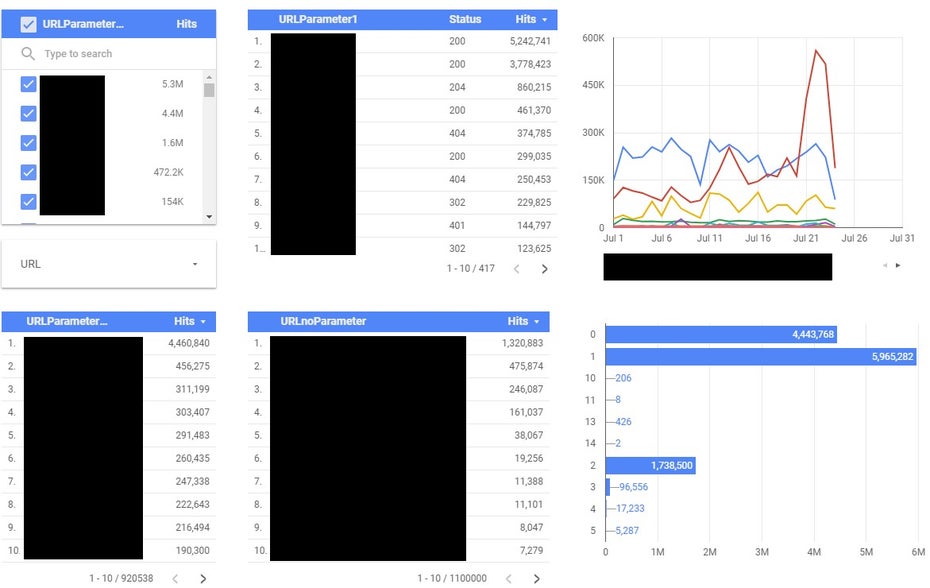
Parameterauswertung mittels Google-Data-Studio-Lösung. (Screenshot: Google)
Zusätzliche Datenquellen zur Anreicherung von Logfiles
Die eben dargestellten Punkte, Statuscodes und Parameter stellen nur einen kleinen Auszug aus den möglichen Betrachtungen einer Logfile-Analyse dar. Abhängig von der Ausrichtung – wie E-Commerce oder Nachrichtenportal –, Content-Management-System und auch Größe kann jede Webseite ihre eigenen Besonderheiten mit sich führen. Diese gilt es auch bei Logfile-Analysen zu beachten. Allein der Blick in Logfiles wird selten entscheidende Erkenntnisse hervorbringen – der Zusammenhang zu der Architektur und Funktionsweise der Website ist immer essentiell. Nur mit gutem Verständnis der Website können tatsächliche Optimierungen aus einer Logfile-Analyse abgeleitet werden.
Weitere interessante Punkte in einer Logfile-Analyse können sein:
- Crawlfrequenz: Wie häufig wird die Seite insgesamt gecrawlt? Gibt es Abweichungen auf einer Verzeichnisebene oder sonstige Peaks
- Crawltiefe und gecrawlte Verzeichnisse: Werden die wichtigsten Verzeichnisse ausreichend gecrawlt?
- Irrelevante URL/Ressourcen: Werden irrelevante URL häufig aufgerufen, wie beispielweise Funktionen, die zum Darstellen einer Seite überhaupt nicht benötigt werden oder den Seiteninhalt ändern?
- Werden die URL aus der Sitemap gecrawlt und wenn ja wie häufig?
- Untersuchung weiterer Bots: Wie crawlen Bing und andere Suchmaschinen die Webseite?
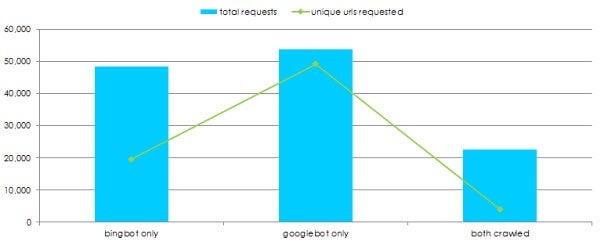
Darstellung der Anzahl aufgerufener URL in einem Logfile durch Google und Bing. Zusätzliche Darstellung einzigartig aufgerufener URL und URL, die von beiden gecrawlt wurden. (Screenshot: Builtvisible)
Abgesehen von den vielfältigen Möglichkeiten, die bereits die Daten der Logfiles bieten, kann man diese noch zusätzlich mit weiteren Daten anreichern. Die Möglichkeiten sind nahezu unendlich. Letztlich wird als Verbindungspunkt immer nur eine URL benötigt und diese schließlich bei sehr vielen Datenquellen beziehungsweise Toolanbietern bereitgestellt. Je nach Analyseziel können sich Traffic-Daten aus Web-Analyse-Tools wie Google Search Console oder Analytics Crawl-Daten respektive Daten über vorhandene Backlinks hinzuziehen, um weitere Rückschlüsse über das Crawling-Verhalten zu gewinnen.
Mobile-First-Index und Logfile-Analysen
Ein interessanter Aspekt ist darüber hinaus der Mobile-First-Index. Hintergrund ist, dass Google in naher Zukunft statt der Desktop-Seite die Mobile-Seite zur Bewertung präferieren wird.
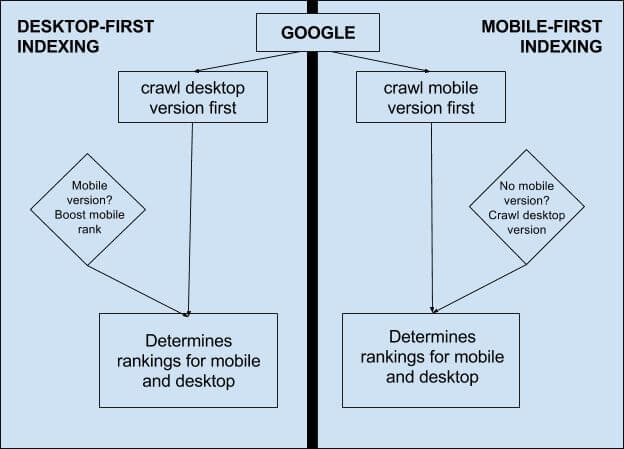
Darstellung des Indexierungsverhaltens von Google beim aktuellen Desktop-First-Indexing und folgendem Mobile-First-Indexing. (Grafik: Moz.com)
Laut John Müller lässt sich anhand der Logfiles bereits erkennen, ob Google die Website im Zuge des Mobile-First-Index häufiger crawlt. Das übliche Verhältnis zwischen mobilem und Desktop-Useragent ist 1:4, solange die Website noch nach altem Muster gecrawlt wird. Bei Websites, die bereits nach dem neuen Muster gecrawlt werden, soll sich dieses Verhältnis jedoch deutlich ändern und die Zugriffe mittels mobilem Useragent den größeren Anteil ausmachen.
Fazit
Logfile-Analysen sind ein sehr gutes Mittel, um präzise Analysen über Crawl-Verhalten, Crawling-Fehler und Ableitungen zum Verständnis der Website-Architektur durch Crawler zu erstellen. Während die Google Search Console beispielweise nur einen rudimentären Blick in mögliche Crawling-Fehler ermöglicht, können mit Logfile-Analysen detaillierte Betrachtungen erzeugt werden. Es ist jedoch wichtig, sich nicht zu sehr in den Logfiles zu verlieren und diese immer in Relation zu der Website, den Potenzialen und Herausforderungen zu stellen. Eine sehr granulare Optimierung des Crawlings ist nicht immer zielführend. Insbesondere wenn zahlreiche Ressourcen aufgewendet werden müssen, die die Optimierung zwar aus SEO-Sicht optimal machen aber einfach nicht mehr wirtschaftlich sind.
Letztlich sind Logfile-Analysen ein wichtiger Bestandteil technischer SEO-Analysen und sollten entsprechend genutzt werden, um die größtmögliche Basis an Informationen für ganzheitliche Analysen bereitstellen zu können.
 Eduard Protzel ist SEO-Consultant bei der Online-Marketing-Agentur Trust Agents in Berlin. Er ist zuständig für die strategische Beratung und Koordination von operativen Umsetzungen bei nationalen sowie internationalen Projekten.
Eduard Protzel ist SEO-Consultant bei der Online-Marketing-Agentur Trust Agents in Berlin. Er ist zuständig für die strategische Beratung und Koordination von operativen Umsetzungen bei nationalen sowie internationalen Projekten.
