
Logfile-Analysen im SEO: Wie verhalten sich Crawler wirklich auf meiner Website? (Teil 1)
")
(Foto: Shutterstock / Dominik Bruhn)
Der Vorteil von Logfile-Analysen liegt darin, dass hier ein nahezu ungefilterter Blick auf das Verhalten von Crawlern auf einer Webseite geworfen werden kann.
- Welche URL werden häufig gecrawlt?
- Welche HTTP-Statuscodes werden ausgegeben?
- Gibt es Einschränkungen, die das Crawling und letztlich die Indexierung der Seite erschweren?
All diese Fragen lassen sich durch Logfiles gezielt beantworten. Gerade im SEO-Bereich, wo oftmals diverse Rankingfaktoren in verschiedener Abhängigkeit den Erfolg beeinflussen, ist nur selten eine absolute Gewissheit über den Erfolg von Maßnahmen möglich. Logfile-Analysen sind daher eine gute Möglichkeit, um einen weiteren Blick auf eine Webseite und bisher ungenutzte Potenziale zu erhalten.
Logfiles sind Aufzeichnungen aller Zugriffe auf einen Server. Ob tatsächlicher Nutzer, Suchmaschinen-Crawler oder auch Tools zum selbstständigen Crawlen einer Webseite – alle hinterlassen einen „Fußabdruck“ in Form eines Eintrages in dem sogenannten Logfile eines Servers. Jede Anfrage steht für eine Zeile im Logfile mit einer Reihe von Informationen.
Da dieses Thema sehr umfangreich ist, wird sich der Beitrag in zwei Teile aufgliedern. Der erste Teil widmet sich grundlegenden Aspekten der Logfile-Analyse, wie der eigentlichen Nutzung im SEO sowie Aufbereitung und Validierung der Logfiles. Im zweiten Teil werden Einblicke in die Auswertung gegeben und Möglichkeiten zur Anreicherung der Logfiles mit weiteren Datenquellen aufgezeigt.
Logfiles in der Webanalyse
Logfiles dienten früher auch zur Analyse der Performance einer Webseite. Durch die Auswertung der einzelnen Zugriffe, den Verlauf der Session und Verweildauer konnte so die Effektivität einzelner Marketingmaßnahmen überprüft werden. Jedoch stieß diese Art der Webanalyse schnell an ihre Grenzen und wurde von den gängigen Webanalyse-Tools wie zum Beispiel Google Analytics abgelöst.
Einer der Kritikpunkte an der Webanalyse mittels Logfiles war die fehlende Einordnung von Nutzern mit sich dynamisch ändernden IP-Adressen in Sessions, die die Auswertungen deutlich verfälscht hat. Aus einem Nutzer beziehungsweise seinem Aufenthalt auf der Webseite konnten so gleich mehrere werden, weil sich innerhalb einer Session seine IP geändert hat. Dadurch war die korrekte Zuordnung nicht mehr einfach zu bewerkstelligen. Weiterhin galt es als unmöglich, die Interaktion mit client-seitig nachgeladenen Elementen nachzuvollziehen, da diese keine neue Anfrage auslösen und somit nicht in den Logfiles auffindbar sind.
Zusätzlich zu den beiden genannten Punkten ist es nicht möglich, Zugriffe zu verfolgen, die sich bereits auf gecachte Inhalte beziehen. Dabei ist es gang und gäbe, dass Inhalte von Browsern zur Beschleunigung der Ladezeit gecacht werden.
Nichtsdestoweniger sind Logfiles für eine SEO-fokussierte Auswertung ein sehr guter Ausgangspunkt, um das Verhalten von Suchmaschinen-Crawlern auf einer Webseite nachvollziehen zu können.
Logfile-Analysen und SEO – Welche Bedeutung haben Logfile-Analysen?
Zunächst muss man verstehen, dass die Auswertung von Logfiles selbst keinen Einfluss auf die SEO-Performance hat. Ebenso hat die Optimierung des Crawling-Verhaltens keinen Einfluss auf das Ranking. Was aber grundlegend für jeglichen SEO-Erfolg ist: Die vorliegenden Inhalte können gefunden und indexiert werden.
Wenn Inhalte jedoch erst sehr spät gefunden und indexiert werden, obwohl sie schon lange veröffentlich wurden, bedeutet das einen deutlichen Nachteil im Vergleich zu Wettbewerbern. Dauert es gar Wochen oder Monate, bis ein bestimmter Teil der Webseite gecrawlt wird und dieser aufgrund von beispielsweise saisonalen Produkten eine besondere Bedeutung hat, besteht nicht nur ein Nachteil im Wettbewerbsvergleich – auch ein monetärer Schaden kann die Folge sein. Wenn diese Inhalte erst nach der eigentlichen zeitlichen Relevanz indexiert werden, vergeudet man hier im Zweifelsfall Potenziale und Geld. Zugegeben: Das Beispiel stellt eine mögliche Problematik etwas überspitzt dar, verdeutlicht aber das Potenzial von Logfile-Analysen und einer Optimierung des Crawling-Verhaltens.
Ohne Blick in die Logfiles oder eine tiefergehende Analyse von indexierten sowie gecrawlten Seiten ist es wie mit Schrödingers Katze – die indexierten Seiten sind aktuell, werden gecrawlt, sind aber auch gleichzeitig nicht aktuell und werden nicht gecrawlt. Beides ist absolut möglich und eine reine Betrachtung der Webseite über eigenes Durchklicken sagt nichts oder wenig über das Verhalten von Suchmaschinen auf selbiger aus.
Um die Kiste zu öffnen und entsprechende Insights für die Auswertung des Crawling-Verhaltens zu erhalten sowie den obigen Extremfall zu verhindern, müssen verschiedene Aspekte betrachtet werden. In der Regel ist es nicht nur ein einzelner Punkt, der den Engpass im Crawling darstellt, sondern eine Ansammlung verschiedener Probleme, die zusammen ein Gesamtproblem darstellen.
Wie ist ein Logfile aufgebaut?
Da jeder Zugriff, auch der Wechsel von einer URL zur nächsten, einen neuen Eintrag generiert, können Logfiles bereits bei Webseiten im mittleren Bereich eine immense Größe erreichen. Wenn ein Nutzer beispielweise auf der Startseite einsteigt, sich über eine Kategorie dort dann drei Produkte anschaut sowie vor jedem Produkt per Klick auf die Kategorie zurücknavigiert, entstehen dabei bereits sieben Einträge.
Ein Eintrag für eine einzelne URL sieht dabei exemplarisch so aus:
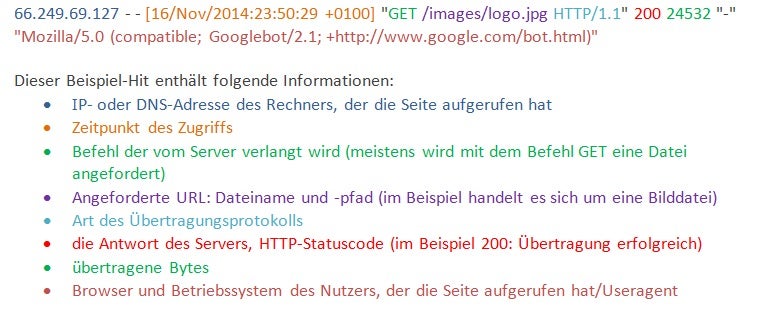
(Screenshot: t3n.de)
Das obige Beispiel zeigt einen Zugriff durch den Googlebot. Es ist hierbei wichtig, zu wissen, dass Crawler eine Liste von URL abarbeiten und nicht wie ein „echter Nutzer“ von einem Link zum nächsten klicken. Die Liste der zu crawlenden URL korreliert dabei natürlich mit den auffindbaren Links innerhalb eines Dokuments. Im Gegensatz zu einem Nutzer wird dabei jedoch in der Regel kein Referrer übergeben, weil der Googlebot oder auch andere Crawler direkt auf eine URL zugreifen, statt über einen Link dahin zu gelangen. Der Referrer gibt an, welche URL vor dem Zugriff auf die gegenwärtige URL aufgerufen wurde, und ist – sofern vorhanden – auch Teil des Logfiles.
Ausnahme hierbei: Eine Ressource einer externen URL, beispielsweise spezielle Funktionen oder sonstige Inhalte, werden für das Laden der gegenwärtigen URL benötigt. In diesem Falle wird auch bei Zugriff durch einen Crawler ein Referrer angegeben.
Validierung von Logfiles
Um Webseiten selbstständig mit Tools wie Screaming Frog zu crawlen, wählen viele als Useragent Varianten des Googlebots aus. Dadurch soll der Crawl wie durch Google selbst imitiert werden. In Bezug auf eine Logfile-Analyse verfälscht dies aber möglicherweise die Analyse. Daher muss an dieser Stelle auf andere Art und Weise die Herkunft der Anfrage validiert werden – das geschieht über die IP.
Eine der Möglichkeiten ist hier der sogenannte Reverse-DNS-Lookup mittels der Windows-Console. Aufgrund der IP können der Server und somit die Herkunft bestimmt werden. Es wird also sichergestellt, dass die IP mit dem Useragent Googlebot auch wirklich von Google kommt.

Screenshot eines Nslookup-Befehls zur Ermittlung des Servers einer IP. (Screenshot: t3n.de)
Grundsätzlich ist dieses Verfahren die sicherste Art, um die Herkunft der Anfrage festzustellen. Je nach Größe einer Seite kann die Anzahl an Zugriffen durch einen Crawler schnell eine Größe erreichen, die eine solche Validierung ineffizient oder gar zeitlich unmöglich macht. Jeder einzelne Zugriff beziehungsweise jede IP in dem Logfile muss bei diesem Verfahren einzeln validiert werden. In manchen Fällen hat man zum Teil Logfiles mit über 10 Millionen Zugriffen durch den Googlebot innerhalb eines Monates. Um die Vorauswahl der relevanten Zeilen hier effizient zu gestalten, beschränkt man sich in der Regel auf den IP-Bereich 66.249.*.*. Dieser hat sich erfahrungsgemäß als ausreichend erwiesen, um das Verhalten des Googlebots zu überprüfen.
Tipp: An dieser Stelle empfiehlt sich auch stets ein Blick in die Google-Search-Console, um die Anzahl der Zugriffe mit den sichtbaren unter „Crawl Statistiken“ zu vergleichen. Aufgrund der Vorabauswahl mittels IP-Bereich wird sich diese zwar immer etwas unterscheiden beziehungsweise die Zahl der Zugriffe wird geringer sein. Wenn die Abweichung jedoch sehr extrem wird, wie beispielsweise weniger als 10 Prozent Zugriffe innerhalb der Logfiles im Vergleich zur Google-Search-Console, gilt es, die Logfiles zu hinterfragen. Eine mögliche Fehlerquelle kann dabei sein, dass die Logfiles von nur einem Server vorhanden sind, obwohl mehrere aufgrund von Load-Balancing benutzt werden. Load-Balancer werden benutzt, um die Last auf mehrere Server zu verteilen, und kommen insbesondere bei großen Webseiten mit vielen Zugriffen vor.
Generell gilt die Devise: Je mehr Daten, desto besser. Ein einzelner Tag an Logs kann bereits für eine grundlegende Analyse des Verhaltens von Crawlern ausreichen. In manchen Fällen ist es jedoch empfehlenswert, über den Zeitraum von einer Woche oder gar einem Monat die Logfiles zu untersuchen, um Auffälligkeiten und Bottlenecks im Crawling-Verhalten aufzudecken.
Aufbereitung und Verarbeitung von Logfiles
Ausgehend von der Art des Servers und der Konfiguration können die Logdateien in verschiedenen Mustern erstellt werden. Im Idealfall sind die Logs bereits in einer Datei zusammengefasst und lassen sich so einfach weiterverarbeiten. Das ist aber eher die Ausnahme als die Regel. Mittels der Console in Windows, GREP oder Terminal für Mac-Nutzer lassen sich Dateien zusammenfassen oder auch manipulieren, um beispielwiese einzelne Zeilen mit dem gewünschten Inhalt zu extrahieren.
Um eine Auswertung von Logfiles vorzunehmen, müssen diese – nachdem man sie erst mühsam zusammengefügt hat – wieder in einzelne Elemente innerhalb der eigentlichen Datei zerlegt werden. Folgende Daten sind als Ausgangsbasis immer interessant:
- Zugriffsdatum und Zeit
- Vollständige Anfrage
- Statuscode
- Größe
- Useragent
Mittels verschiedener Excel-Formeln oder SEO-Tools-for-Excel lässt sich die Anfrage in einzelne Punkte herunterbrechen und betrachten. Wichtig ist bei der Zerlegung der Anfrage, dass die einzeln betrachteten Elemente weiterhin in der gleichen Zeile mit der Ausgangsanfrage stehen. So wird die weitere Bearbeitung mittels Pivot-Tabellen in Excel oder anderen Tools ermöglicht.
Jedoch stößt man mit Excel oftmals an die Grenzen der 1.048.576 möglichen Zeilen, weil Logfiles schnell eine extreme Größe erreichen können. Abhilfe schaffen hier verschiedene Logfile-Analyse-Tools wie der Screaming-Frog-Analyzer oder Enterprise Lösungen.
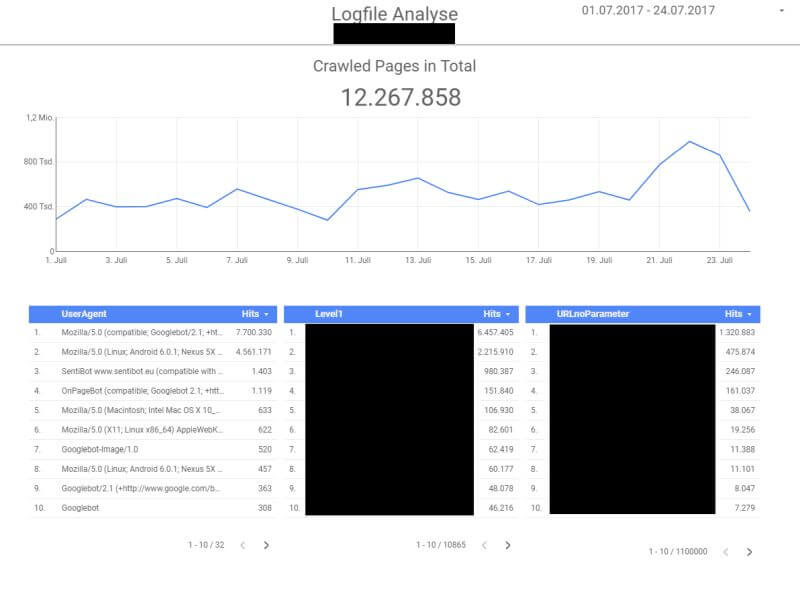
Logfile-Analyse mittels Google Data Studio. (Screenshot: Google Data Studio)
Fazit und Ausblick auf den zweiten Teil
In diesem ersten Teil über Logfile-Analysen im SEO wurden grundsätzliche Themen wie der Hintergrund, das Nutzen und die Aufbereitung von Logfiles behandelt. Diese Themen sollten nicht unterschätzt werden. Ohne valide Datenbasis können bei einer Analyse irreführende oder gänzlich falsche Ergebnisse entstehen.
Der zweite Teil wird sich mit der eigentlichen Analyse beschäftigen und auf diese Punkte eingehen:
- HTTP-Statuscodes in einer Logfile-Analyse
- Parameter und ihre Bedeutung in Logfile-Analysen
- Zusätzliche Datenquellen zur Anreicherung von Logfiles
- Mobile-First-Index und Logfile-Analysen
 Eduard Protzel ist SEO Consultant bei der Online-Marketing-Agentur Trust Agents in Berlin. Er ist zuständig für die strategische Beratung und Koordination von operativen Umsetzungen bei nationalen sowie internationalen Projekten.
Eduard Protzel ist SEO Consultant bei der Online-Marketing-Agentur Trust Agents in Berlin. Er ist zuständig für die strategische Beratung und Koordination von operativen Umsetzungen bei nationalen sowie internationalen Projekten.
