





t3n SEO-Check: Typische Onpage-Probleme bei Onlineshops

Onpage-SEO-Tools
Aufgrund des Umfangs und der Komplexität der meisten Onlineshops sind Onpage-SEO-Tools, welche die gesamte Website crawlen, oft unerlässlich. Abhängig von Vorkenntnissen, Budget und Anforderungen haben sich unterschiedliche Lösungen durchgesetzt. In jedem Fall lohnt ein Blick in die Google Search Console, welche auf Probleme beim Crawling und der Indexierung der eigenen Seite hinweist.
Wer fortgeschrittene SEO-Kenntnisse hat, kann seine Website mit Desktop-Software wie Screaming Frog vom eigenen Rechner aus crawlen lassen und die Ergebnisse in Excel auswerten. Dafür wird nur eine relativ günstige Softwarelizenz fällig.
Software-as-a-Service-Anbieter (SaaS) wie Ryte bieten eine benutzerfreundliche Alternative, stellen die technischen Ressourcen zum Crawlen und bieten Hilfestellung durch vorgefertigte Reports und begleitende Anleitungen. Da die Onpage-Optimierung in den letzten Jahren an Bedeutung zugenommen hat, bieten viele All-In-One-SEO-Tools wie Semrush oder Sistrix mittlerweile auch Website-Audits als Modul an. Die Kosten für SaaS-Lösungen liegen in der Regel um die 100 Euro monatlich.
Für meinen heutigen SEO-Check habe ich, wie in meinem Arbeitsalltag so oft, überwiegend auf Ryte zurückgegriffen. Da ich das Onpage-Tool schon seit Jahren als zahlender Kunde nutze und unser Agentur-Account mit Kundenprojekten am Limit ist, waren die Münchener Kollegen so freundlich, mir für meine kostenlosen SEO-Checks vorübergehend einen Account zur Verfügung zu stellen.
Schlechte interne Verlinkung
Die interne Verlinkung ist besonders bei Onlineshops mit vielen Produkten ein großer Hebel für die Suchmaschinenoptimierung. Denn oft sind wichtige Kategorien oder Produkte zu schlecht für Nutzer und Bots erreichbar. Bei sehr breiten Sortimenten ergibt sich durch die Kategorisierung über mehrere Ebenen natürlicherweise ein langer Klickpfad zu oft SEO-technisch besonders wichtigen Unterkategorien und Produkten. Es kommt auch nicht selten vor, dass einige Seiten gar keine internen Links haben. Dies ist der Worst Case, den man unbedingt vermeiden sollte. Da die schnelle Erreichbarkeit mit wenigen Klicks jedoch wichtig für das Crawling und die Relevanz-Bewertung durch Google ist, sollte besonders auf eine gezielte interne Verlinkung geachtet werden.
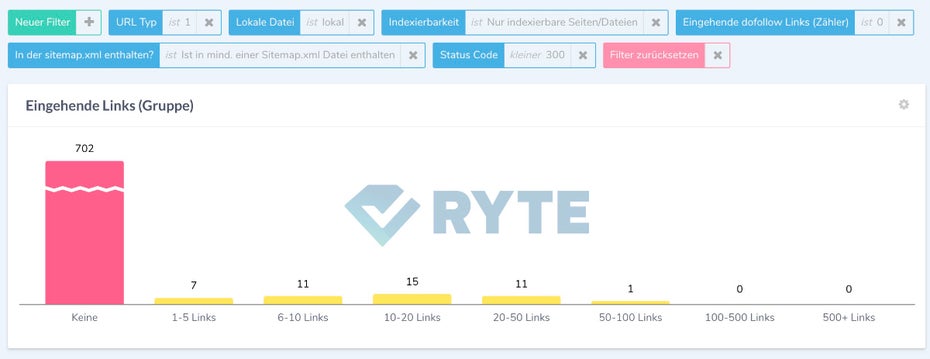
Der Onlineshop meinduft.de hat über 700 Seiten, die gar nicht intern verlinkt sind und daher auch als verwaiste Seiten bezeichnet werden (Screenshot: ryte.com)
Interne Links auf fehlerhafte Seiten
Aufgrund des Umfangs der meisten Onlineshops ergeben sich häufig auch interne Links auf Seiten, die nicht mehr existieren und 404-Fehler oder andere Fehlermeldungen hervorrufen. Bei systematisch erzeugten Links etwa über die Hauptnavigation oder im Footer lässt sich dies schnell beheben. Oft verstecken sich aber Links auf fehlerhafte Seiten auch in den redaktionell gepflegten Seiten wie dem Service- oder Pressebereich. Diese findet man am besten mit einem vollständigen Onpage-Crawl. Dieser erzeugt dann eine Liste der Links auf Fehlerseiten, die man Stück für Stück abarbeiten kann.

Klickt der Nutzer bei diesem Shop im Downloadbereich auf “VARIO compact”, gelangt er auf eine Fehlerseite (Screenshot: a1-zaundiscount.de)
Temporäre Weiterleitungen
Vorübergehende Weiterleitungen per HTTP-Statuscode 302 sind nur in den wenigsten Fällen wirklich sinnvoll. Bei Shopsystemen kommen sie häufig im Zusammenhang mit dem Warenkorb oder dem Kunden-Login zum Einsatz. Diese Seiten sind ohnehin in der Regel für die Indizierung ausgeschlossen. Problematisch wird es aber, wenn 302-Redirects anstelle der permanenten 301-Weiterleitung falsch genutzt werden. Diese sind dafür vorgesehen, Nutzer und Bots auf geänderte URLs weiterzuleiten. Suchmaschinen verwerfen dann die ursprüngliche URL und indexieren stattdessen die neue. Bei einer vorübergehenden Weiterleitung behalten Google & Co die Einstiegs-URL noch bei.
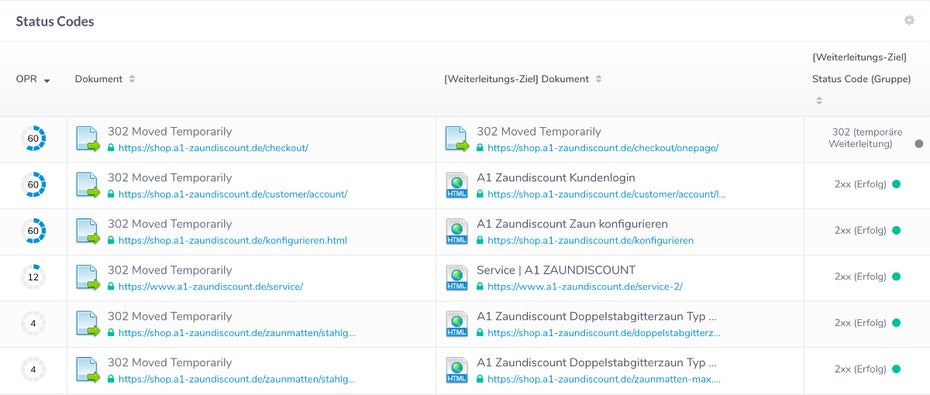
a1-zaundiscount.de nutzt temporäre Weiterleitungen fälschlicherweise anstelle von permanenten Weiterleitungen (Screenshot: ryte.com)
Interne Nofollow-Links
Vor einer halben Ewigkeit konnte man die interne Pagerank-Verteilung mal über das Rel-Nofollow-Attribut steuern. Seitdem wird diese längst überholte Praxis munter weiter von Websitebetreibern genutzt. Mittlerweile gibt es jedoch seit vielen Jahren keinen Grund mehr, interne Links mit „nofollow“ zu markieren, da Google diese Links nicht wie gewünscht bei der Pagerank-Verteilung ausschließt, sondern der über diese Links vererbte Pagerank einfach verloren geht. Häufiger Anwendungsfall sind Links auf rechtliche Angaben wie das Impressum oder die Datenschutzerklärung. Sollen diese nicht in den Google-Index, ist ein „nofollow“-Link ein ungeeignetes Mittel. Stattdessen sollte die Meta-Robots-Angabe der unerwünschten Seite mit „noindex“ versehen werden. In den Links auf diese Seiten sollte auf jeden Fall das „nofollow“-Attribut entfernt werden. Wer partout diese Seiten bei der Pagerank-Verteilung ausschließen will, sollte das Post-Redirect-Get-Verfahren (PRG) anwenden. Hier kommt technisch gesehen eine Formularweiterleitung zum Einsatz, die Google nicht als Link erkennt oder verfolgt. Für Nutzer können PRG-Links so gestaltet werden, dass sie sich optisch nicht von normalen Links unterscheiden lassen.

Bei diesem Onlineshop werden einige Seiten intern mit „nofollow” verlinkt (Screenshot: drhoehls.de)
Doppelte Inhalte
Gerade bei Onlineshops entstehen durch die facettierte Suche, also die Eingrenzung von Produktlisten nach Filtern, Produktvariationen wie verschiedenen Verpackungsgrößen und fehlenden einzigartigen Produktbeschreibungen, oft doppelte Inhalte. Auch wenn es keine Abstrafung durch Google für doppelte Inhalte gibt, können sich Duplicate-Content-Probleme negativ für SEO auswirken und sollten vermieden werden. Abhängig von der Ausprägung der mehrfach vorliegenden Inhalte gibt es verschiedene Lösungsansätze. Für die Filter in Produktlisten werden PRG-Links eingesetzt, die Produktvariationen zusammengefasst oder per Canonical „vertaggt“. Dazu werden einzigartige Kategorie- und Produktbeschreibungen verfasst.
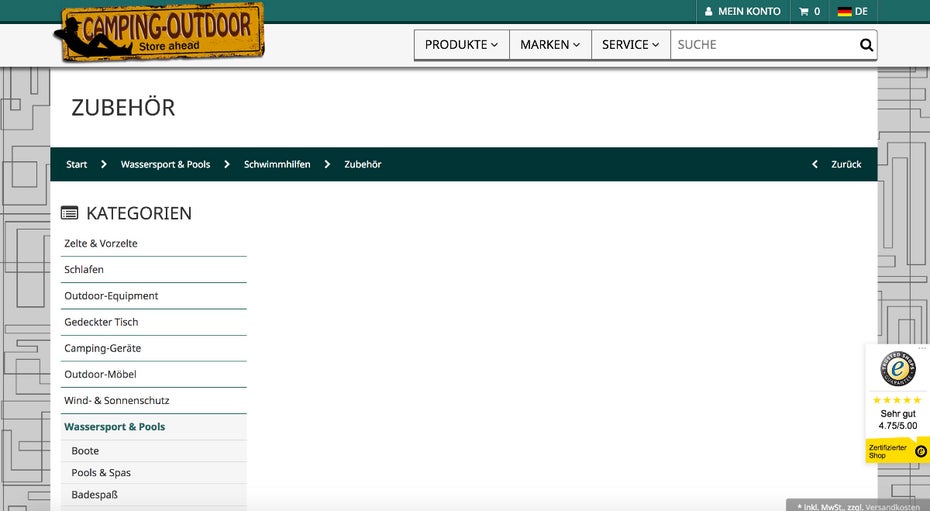
In diesem Camping- und Outdoor-Onlineshop gibt es zahlreiche leere Kategorien, wie diese, die für doppelte Inhalte sorgen (Screenshot: camping-outdoor.eu)
Fehlender oder falscher Canonical-Tag
Der Canonical-Tag hilft dabei, Duplicate-Content zu vermeiden, der durch unterschiedliche URLs zu ein und demselben Inhalt entsteht. Dies wird häufig durch GET-Parameter für die Sortierung oder Tracking-Informationen aus Social Media oder von Partnerseiten verursacht. Daher sollte jede Seite auf ihre kanonische URL über den Canonical-Tag im HTML-Head verweisen. Ohne Canonical-Tag oder permanente Weiterleitung überlässt man die Entscheidung, welche der URL-Varianten im Index gespeichert wird, der Suchmaschine. Und das muss nicht immer im eigenen Sinn sein. Auch der falsche Einsatz des Canonical-Tags, etwa durch systematische Fehler, kann schwerwiegende Folgen haben. Im schlimmsten Fall ignoriert Google die Angaben der Website und indexiert wiederum mitunter die falschen URLs.
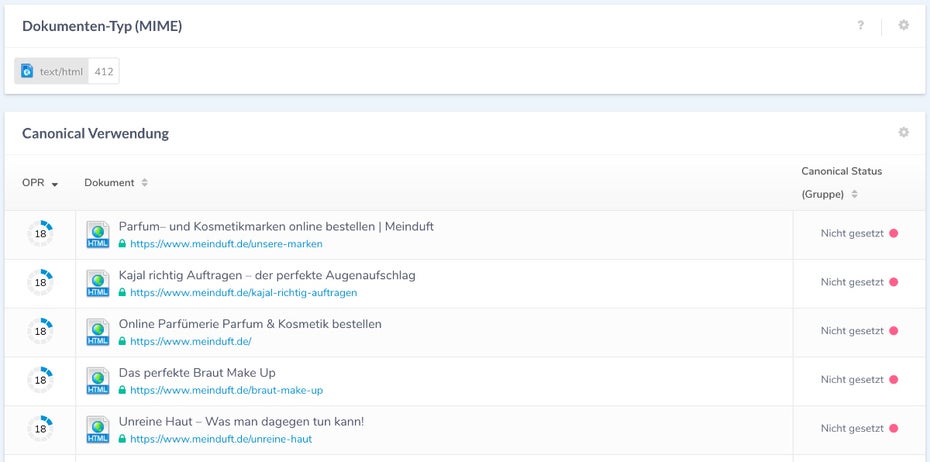
Bei meinduft.de fehlt der Canonical-Tag bei über 400 Seiten, was schnell zum Duplicate-Content-Problem werden kann (Screenshot: ryte.com)
Unvollständige Sitemap.xml
Die Sitemap.xml dient dazu, gezielt die gewünschten Seiten bei Suchmaschinen wie Google einzureichen. Hier sollten also alle URLs enthalten sein, die indexiert werden sollen und können. Jedoch stellen wir immer wieder fest, dass entweder unsinnige Seiten, die beispielsweise über Meta-Robots aus noindex gesetzt sind, in der Sitemap.xml aufgelistet werden. Auch fehlen häufig relevante Seiten, die jedoch indexiert werden sollen. Um zu erfahren, ob die über die Sitemap.xml eingereichten Seiten von Google indexiert wurden, kann man in der Google-Search-Console unter „Crawling > Sitemaps” die Indexierung überprüfen. Ob indexierbare Seiten in der Sitemap.xml fehlen, kann man mit einem Onpage-Crawl herausfinden. Fehlen Seiten in der Sitemap, muss überprüft werden, ob diese noch aufgenommen werden oder von der Indexierung ausgeschlossen werden sollen.
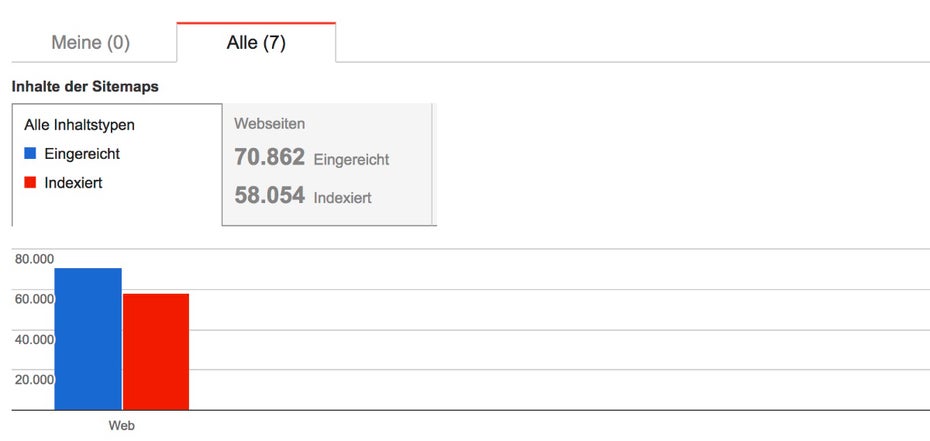
In der Google Search Console kann man überprüfen, ob alle über die Sitemap.xml eingereichten Seiten auch indexiert wurden (Screenshot: google.com)
Zu hohe Gesamtgröße der Seiten
Zu guter Letzt, aber nicht weniger wichtig, sind alle Dinge, welche die Ladezeit verlangsamen. Häufig verursachen großzügig bebilderte Produktlisten hohe Dateigrößen, welche den Seitenaufbau verzögern. Werden dutzende nicht-optimierte Produktbilder auf einer Seite geladen, summiert sich das schnell zu mehreren Megabyte. Meist können die Bilder jedoch ohne sichtbaren Verlust auch automatisch beim Upload oder vorher manuell vom Grafikdesigner signifikant komprimiert werden. Auch viele andere externen Ressourcen wie aufgeblähte CSS- und Javascript-Dateien blockieren häufig den schnellen Seitenaufbau. Da sich lange Ladezeiten vor allem auch auf die Absprungrate und Conversionrate negativ auswirkt, sollte jeder Shopbetreiber das Thema Pagespeed, im eigenen Interesse und über den reinen SEO-Effekt hinaus, besonders ernst nehmen.
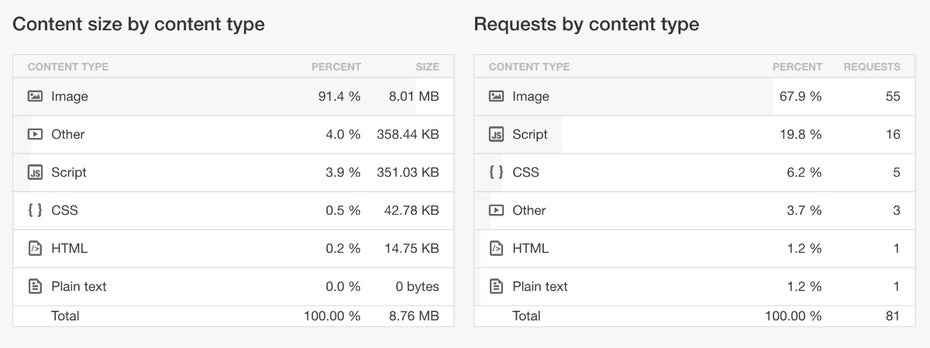
Bei reggae-wear.com machen die Bilder in der Kategorie Männer-Shirts 8 MB und damit 91% der Gesamtgröße aus (Screenshot: pingdom.com)
Ich soll eure Seite durchleuchten und eure Problemzonen aufdecken? Dann reicht jetzt eure Seite für einen kostenlosen SEO-Check ein:
Jetzt Seite einreichen! Christian B. Schmidt optimiert seit 1998 Websites und ist Gründer der SEO-Agentur Digitaleffects aus Berlin. In seiner werktäglichen Podcast- und Videoreihe SEO-Driven führt er in diesem Jahr gratis SEO-Checks für 1.000 Websites durch. Der t3n SEO-Check mit Christian B. Schmidt gibt euch wöchentlich kostenlose Starthilfe.
Christian B. Schmidt optimiert seit 1998 Websites und ist Gründer der SEO-Agentur Digitaleffects aus Berlin. In seiner werktäglichen Podcast- und Videoreihe SEO-Driven führt er in diesem Jahr gratis SEO-Checks für 1.000 Websites durch. Der t3n SEO-Check mit Christian B. Schmidt gibt euch wöchentlich kostenlose Starthilfe.

Fragen zum Thema? Ich beantworte sie gerne hier in den Kommentaren!
Hey Christian,
spannender Artikel zu diesem Thema. Ich habe einen kleinen Online Shop und mich auch schon ganz gut in das Thema eingelesen. Habe bis jetzt schon viel über den Screaming Frog gelesen, beispielweise diesen Artikel hier (auch wenn er schon etwas älter ist) einer Seoagentur: https://www.online-solutions-group.de/Blog/screaming-frog-seo-spider-mit-dem-frosch-auf-tauchstation-gehen/, den fand ich recht informativ.
Nun zu meiner Frage. Denkst du es ist möglich, vorausgesetzt man liest sich gut ein, den Screaming Frog anzuwenden oder würdest du da eher das Tool von Ryte empfehlen. Mein Budget ist nicht so riesig, daher wäre wahrscheinlich der Screaming Frog (was den Preis angeht) billiger, aber es bringt mir ja auch wenig wenn ich dann nachher damit viel länger brauche. Wäre mal über deine Einschätzung gespannt.
Grüße Martin
Danke für die Frage, Martin, und den hilfreichen Link ;) Da ich persönlich nicht viel mit Screaming Frog gearbeitet habe bisher, ist es schwer eine Empfehlung zu geben. Ich denke am besten testest Du beide Tools mal, das sollte in jedem Fall kostenlos möglich sein, und entscheidest für Dich selbst, womit Du besser zurecht kommst.