Container-Virtualisierung: Docker und Kubernetes erfolgreich einsetzen

In den letzten Jahren war in der Softwareentwicklung ein Trend hin zu verteilten Systemen und Anwendungen unter dem Architekturmuster der Microservices zu verzeichnen. Infrastruktur-Technologien wie die Containerisierung sind Teil dieser Entwicklung und sorgen für eine Adaption der innovativen Konzepte im Cloud-Computing-Bereich. Gerade bei Entwicklern wird die Containerisierung mittels Docker immer beliebter. Dies hat mehrere Gründe. Die relevantesten sind sicherlich die Geschwindigkeit und Konsistenz, die sich bei der Entwicklung, beim Debugging und Testen mithilfe von Containern ergeben.
Docker: Was ist es, was kann es, wie funktioniert es?
Das Konzept von Containern ist eine neue Variante der Virtualisierung mit einem Fokus auf PaaS. Im Vergleich zu virtuellen Maschinen sind sie schlanker und lassen sich einsetzen, um Applikationen fertig gepackt zum Testen und Deployment auszuliefern. Während bei virtuellen Maschinen die Hardware emuliert wird, erfolgt die Virtualisierung bei Containerlösungen wie Docker eine Ebene höher, nämlich beim Betriebssystem. Dies wird durch Linux-Kernel-Features wie Cgroups und Namespaces realisiert. Mittels dieser können Prozesse und deren Ressourcen voneinander isoliert und auch limitiert werden. Dadurch ist das Betriebssystem beziehungsweise dessen Kernel nicht Teil eines Containers und entsprechend kompakter sowie schneller und einfacher nutzbar. Der Container enthält lediglich die Abhängigkeiten, die für das auszuführende Programm benötigt werden.
Die in der Sprache Go geschriebene Containerlösung Docker wurde von Docker Inc. erstmals im März 2013 veröffentlicht. Mit der Docker-Runtime ist eine zusätzliche Schicht zwischen Applikation und Host-Betriebssystem gegeben, in welchem sich Docker-Container ausführen lassen. Jeder dieser Container bringt alle benötigten Abhängigkeiten für die jeweilige Applikation mit und läuft in einer eigenen Umgebung. Verteilt werden Container als Docker-Images, gewissermaßen Templates zur Erstellung von Containern. Innerhalb einer Docker-Runtime oder einem Cluster können mehrere Container gleichzeitig laufen. Startet man mehrere Container mit demselben Image, so sind diese zunächst genaue Replikate. Das geniale ist nun, dass man weitere Veränderungen vornehmen kann, ohne dieses Base-Image zu modifizieren. Die Technik, die dahintersteckt, ist das UnionFS. Ein Dateisystem, welches ursprünglich für das Plan9-Betriebssystem entwickelt wurde. Mit diesem können Verzeichnisbäume in so genannte Layer übereinandergelegt werden. Diese werden dann in einer logischen Sicht zusammengefügt, sodass der oberste Layer derjenige ist, dessen Sicht ausschlaggebend ist. Können dort Dateien nicht gefunden werden, werden diese in den unteren Layern gesucht. Ein Entwickler hat daher beispielsweise die Möglichkeit, ein Ubuntu-basiertes PHP-Base-Image zu benutzen und eigenen Code oder Extensions hinzuzufügen. Wird dieses Ubuntu-Base-Image gepatched, hat der Entwickler die Möglichkeit, dieses zu beziehen und seine Modifikationen darüber zu legen. Das erhöht den Komfort und spart Zeit:
Der Entwickler muss sich zum Beispiel nicht damit beschäftigen, dass die Versionen der Pakete auf dem neusten Stand sind, sondern er kann sich auf die Weiterentwicklung seines Codes fokussieren. Auch Operations profitiert enorm, da gewährleistet wird, dass die Entwicklungsumgebung und das Produktivsystem sich aus denselben Images ableiten. Damit kommt es zu keinen negativen Überraschungen à la „bei mir lokal hat es aber noch funktioniert“. Es gibt jedoch eine Einschränkung, die bei einer effizienten Umsetzung von Container-Projekten zu berücksichtigen ist. Docker selbst bringt keinen Ressource-Scheduler, keine Hochverfügbarkeit oder dergleichen mit. Hierfür gibt es aber Lösungen wie beispielsweise Docker Swarm oder Kubernetes.
Wichtig ist in diesem Kontext, dass Container standardmäßig als „Immutable Infrastructure“ zu verstehen sind. Das bedeutet, dass Container intern keine persistenten Daten halten. Soll auf persistente Daten zugegriffen werden, müssen diese als externes Volume in den Container eingebunden (gemountet) werden. Dies bedeutet für Systemadministratoren, dass zum Beispiel Bugfixes niemals in einem Container stattfinden dürfen, da dieser jederzeit zerstört oder neu gestartet werden kann. Die Änderungen wären dann unwiederbringlich verloren. Der richtige Weg ist es, das Problem zu debuggen und im Image zu beheben. Das Image kann im Anschluss neu ausgerollt werden. Ein beispielhafter Workflow hierfür wäre:
- „Check out“ des Git-Repositories, welches die Templates, Skripte, gegebenenfalls Binaries und Konfigurationsdefinitionen für das Image bereithält
- Generieren eines neuen Branches
- Erstellen des Bugfixes
- Lokales Testen via docker-compose
- Wenn nicht funktional: re-iterieren
- Wenn funktional: „committen“, Pull-Request erstellen und die Änderungen zum Master-Branch „mergen“
- Die Delivery-Pipeline (siehe unten) anstoßen
Kubernetes: Nicht nur ein Orchestrierungstool
Zum effizienten Managen von Containern ist der Einsatz einer Clusterverwaltung wie Kubernetes von Vorteil. Kubernetes ist ein von Google Inc. als Open-Source-Software entwickeltes Management-Tool für die Bereitstellung, Verwaltung und Überwachung einer Container-Umgebung. Diese ermöglicht das Hosten von sogenannten Kubernetes-Clustern, welche sich aus Compute-Nodes zusammensetzen. In diesen können eine große Anzahl von Containern, basierend auf vordefinierten Templates (Kubernetes-Manifests), betrieben werden. Dabei werden von Kubernetes verschiedene Docker-Hosts, sogenannte Nodes, betrieben. Auf diesen lassen sich die kleinsten Einheiten von Kubernetes, sogenannte „Pods“, verteilen. Ein Pod repräsentiert hierbei gewöhnlich eine Applikation, kann aber mehrere Container enthalten. Kubernetes betreibt einen „kubelet“ genannten Agent, welcher die Pods überwacht und bei einem Ausfall unter anderem einen neuen Pod auf einem anderen Node starten kann. Auf einem höheren Level lassen sich auch größere Vernetzungen von Containern in mehreren Pods definieren, etwa in Deployments. Die wichtigsten Features von Kubernetes zusammengefasst:
- Resource-Scheduler: Platziert Pods/Container anhand der Ressourcenanfragen auf den verfügbaren Compute-Nodes.
- Auto-Scaling: Kubernetes ermöglicht eine automatisierte Anpassung der benötigten Compute-Nodes aufgrund Lastenänderungen. Bei wachsenden Anforderungen nimmt Kubernetes Compute-Nodes zum Cluster hinzu und reallokiert dynamisch die Ressourcen.
- Self-Healing: Der kubelet-Service überwacht alle laufenden Container und startet diese bei Bedarf neu. Dies erfolgt automatisiert anhand vorher festgelegten Regeln und befreit den Administrator von lästigen, manuellen Zugriffen.
- Service-Discovery: Eine voll funktionsfähige Service-Discovery mittels DNS, um Verbindungen zu anderen Containern zu erkennen, ist in Kubernetes standardmäßig integriert. Alle Pods und alle Service werden Cluster-intern registriert und anhand des Health-Status unter cluster.local propagiert.
- Rolling-Upgrades/ Rollbacks: Die Deployment-Ressource unterstützt Rolling-Upgrades anhand sequenzieller Re-Deployments von allen betreffenden Pods.
- Secret / Configuration-Management: Ist standardmäßig in Kubernetes integriert und ermöglicht das sichere Handling von beispielsweise Passwörtern oder API-Keys.
- Storage-Orchestration: Out-of-the-Box werden diverse Storage-Lösungen wie Google GCE PD, AWS EBS, S3, Ceph, NFS oder iSCSI unterstützt. Diese können direkt an den Cluster angeschlossen werden und beispielsweise als externe Volumes für persistente Daten benutzt werden.
Kubernetes hilft uns also Container hochverfügbar, skalierbar und hochperformant zu betreiben.
Continuous-Delivery-Pipeline: Wie Deployment-Workflows optimal automatisiert werden
Aufgrund der bestehenden Komplexität ist es sinnvoll, eine Continuous-Delivery-Pipeline zu etablieren, mit welcher neuer Code, Bugfixes oder neue Versionen von 3rd-Party-Software eingespielt werden kann. Da in diesem Umfeld nichts mehr in die laufende Umgebung deployt wird (Immutable Infrastructure), ändert sich auch der gewohnte Weg von solchen Pipelines. Generell bietet es sich an, ein Git-Repository als Code-Repository zu haben und ein separates für die Pflege des/der Docker-Images. Als Job-Scheduler kann beispielsweise Gitlab-CI oder Jenkins genutzt werden. Letzteres bietet sich an, da es hierfür unzählige Plugins, beispielsweise für Docker oder auch Kubernetes gibt und Jenkins sehr flexibel ist.
In folgender Zeichnung findet sich ein exemplarischer Deployment-Workflow für das E-Commerce-Framework Spryker im Zusammenspiel mit Kubernetes. Der Entwickler pusht in diesem Fall den Code in ein gemeinsames Code-Repository und gibt an, in welche Umgebung (Live, Stage oder Dev) er deployen möchte. Daraufhin läuft ein Jenkins-Job, welcher dieses Repository auscheckt, die Images mit dem neuen Code baut, testet und in der Image-Registry published. Daraufhin wird Kubernetes angewiesen, diese Images aus der Registry zu ziehen und die Pods neu auszurollen.
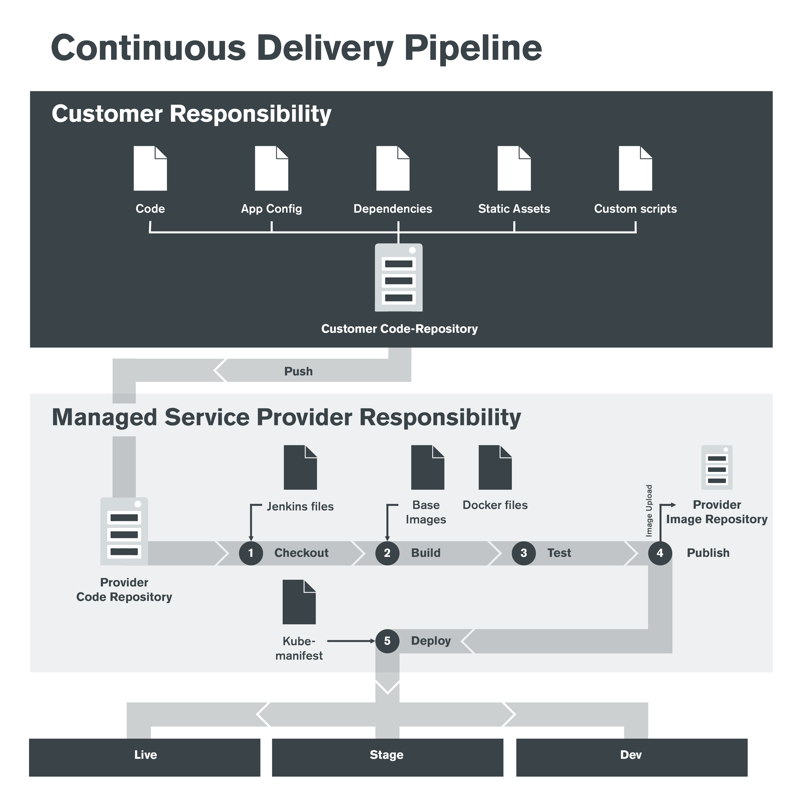
(Grafik: © Claranet GmbH)
Caveats – was du beachten solltest
Damit dies alles reibungslos funktioniert, ist Folgendes unbedingt zu berücksichtigen: Beim Containerdesign sollte darauf geachtet werden, den Container als statische „Black-Box“ zu sehen. Ideal ist, wenn nur ein Prozess beziehungsweise Service pro Container läuft. Hier gibt es sicherlich Ausnahmen, wie PHP, bei denen es sinnvoll sein kann, nginx und php-fpm im selben Container zu haben. Das Container-Image sollte idealerweise sinnvolle „defaults“ in den Konfigurationsdaten mitbringen, die jedoch von extern durch Variablen überschrieben werden können. Dies macht das Image deutlich universaler. Nutzdaten dürfen niemals in Containern gespeichert werden. Zum einen gehen diese nach einem Neu-Deployment verloren, zum anderen ist die Performance deutlich schlechter. Für Nutzdaten muss daher ein externes, persistentes Volume genutzt werden. Auf Shared Storage zwischen Containern sollte grundsätzlich verzichtet werden. Wenn dies nicht möglich ist, sollte idealerweise nicht NFS, sondern ein Object-Store wie S3 verwendet werden.
Im Kubernetes-Kontext bietet es sich an, einen Paketmanager wie Helm zu nutzen, um die mangelnde Parametrisierbarkeit von Kubernetes-Manifesten zu umgehen. Wenn Scaling/Auto-Scaling verwendet wird, muss vorher sichergestellt werden, dass die Cloud, in welcher der Kubernetes-Cluster läuft, eine Integration in Kubernetes hat. Wenn nicht, muss diese selbst geschaffen werden.
Generell muss der „Everything-as-Code“-Gedanke unbedingt gelebt werden. Wer hier noch wenig Erfahrung hat, sollte sich folgende Tools genauer ansehen:
- Cloud: Terraform
- Cluster: Kubernetes-Manifests, Helm
- Jenkins: Job-DSL-Plugin, Pipeline-Plugin
- Dynamische Orchestrierung/Konfigurationsmanagement: Ansible
- Für alles andere: Shellscripts, Python, Perl
Mit den genannten Tools in petto und der Berücksichtigung einiger Dos and Don’ts erhält man eine sehr moderne, dynamische und hochskalierende Umgebung. Änderungen sind Entwicklern und Operations komplett transparent und können jederzeit reproduziert werden. Alle Umgebungen sind durchweg konsistent, sodass auf Integrationstests Verlass ist.
 Michael Riexinger ist seit 15 Jahren im Managed Hosting aktiv. Er verantwortet bei Claranet den Bereich Platforms Engineering, der sich mit Design und Betrieb innovativer Cloud-Plattformen beschäftigt. Fokus: Container, Kubernetes, Automatisierung.
Michael Riexinger ist seit 15 Jahren im Managed Hosting aktiv. Er verantwortet bei Claranet den Bereich Platforms Engineering, der sich mit Design und Betrieb innovativer Cloud-Plattformen beschäftigt. Fokus: Container, Kubernetes, Automatisierung.
