Google-Cache und Archive.org: Verlorene Web-Inhalte wiederfinden
")
(Grafik: Shutterstock)
Angenommen, du hast eine Website in der Lesezeichen-Sammlung abgelegt und beim erneuten Aufruf stellst du fest, dass es diese nicht mehr gibt. Die spezielle Karte von Auenland oder die Beschreibung von Winterfell würdest du aber dennoch gerne nochmal lesen.
Oder du hast selbst eine Fan-Website aufgebaut, viel Herzblut investiert, das Projekt aber aus Mangel an Zeit eingestellt und gelöscht … ohne Backups anzulegen. Nach ein paar Jahren packt dich das Fieber wieder, du willst das Projekt wiederbeleben, aber wie kommst du an die alten Inhalte?
Vielleicht willst du auch nur wissen, wie eine bestimmte Website vor zwölf Jahren ausgesehen hat und welchen Inhalt sie hatte. Wie kann man das bewerkstelligen?
In solchen und ähnlichen Szenarien können der Cache von Google oder das Internet-Archiv helfen. Die Betonung liegt hierbei bei können.
Google Cache: Das Web-Kurzzeitgedächtnis 
Google erstellt von den Websites einen Schnappschuss und legt ihn als Cache ab. Diesen Cache erreichst du unter anderem, indem du nach einer Seite suchst und dann in den Suchergebnissen auf den grünen Pfeil neben dem Domain-Namen klickst. Nach dem Klick auf den Pfeil wird das Popup „Im Cache“ eingeblendet:
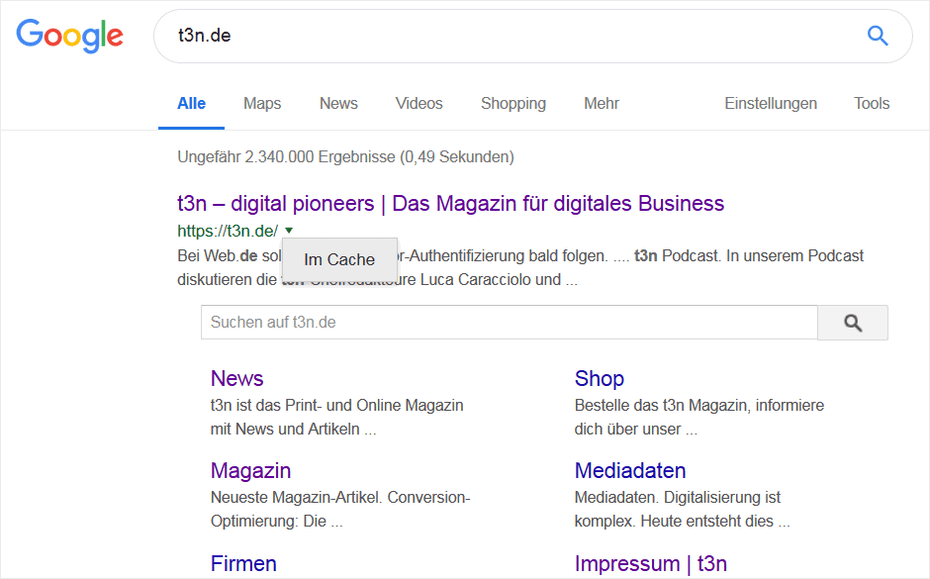
Google-Cache von t3n.de aufrufen. (Screenshot: t3n)
Alternativ kannst du sowohl den Domain-Namen oder auch einen Permalink direkt in der Adresszeile des Browser nach dem folgenden Muster aufrufen: „http://google.com/search?q=cache: t3n.de“
Google zeigt dann den Schnappschuss der Seite an, wie sie vor wenigen Tagen aussah. Wie du anhand des folgenden Screenshots siehst, ist der Schnappschuss von t3n.de einen Tag alt:

Die Startseite von t3n im Google-Cache. (Screenshot: t3n)
Mit diesem Ergebnis kann man oft schon arbeiten und Bilder, Texte und weitere Inhalte entnehmen. Allerdings darf man nicht zu optimistisch an das Ganze herangehen. Manchmal kommt das CSS nicht ganz mit, nicht von jedem Blog-Artikel gibt es einen Cache und je nach Website ist es so, dass Google den Cache nach ein paar Tagen oder nach ein bis zwei Wochen erneuert. Also ist Eile angesagt, wenn man die Inhalte retten will.
Archive.org: Das Web-Langzeitgedächtnis
Liefert der Google-Cache keine oder keine zufriedenstellenden Ergebnisse – keine Panik, tief durchatmen und das Internet-Archiv, auch bekannt als Wayback Machine, ansteuern. In unregelmäßigen Zeitabständen steuert der Crawler die Websites an und macht Kopien. Der folgende Screenshot zeigt …
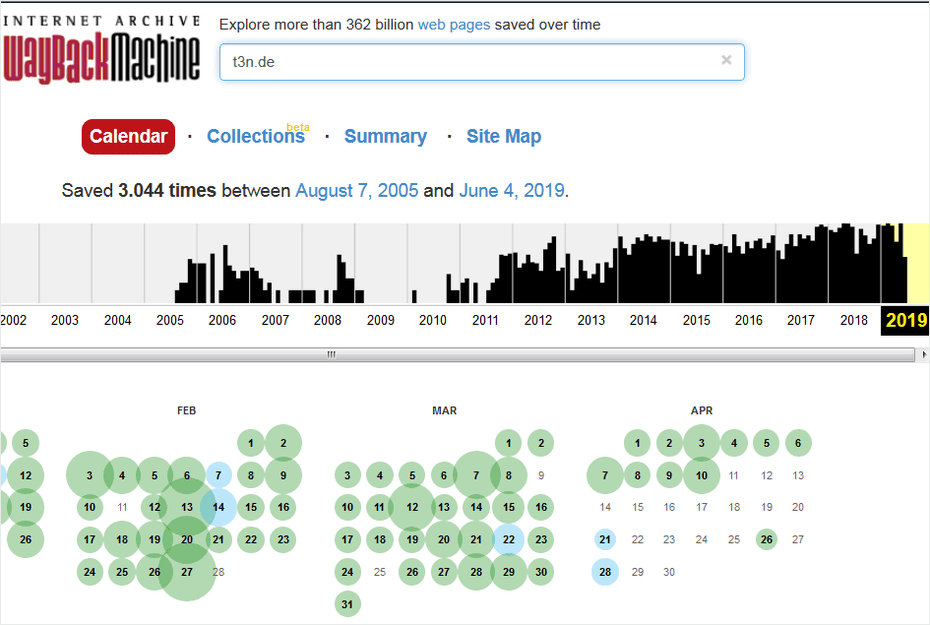
t3n wurde seit 2005 mehr als 3.000 Mal von der Wayback Machine besucht. (Screenshot: t3n)
… dass der Crawler von Archive.org t3n.de seit September 2005 mehr als 3.000 Mal angesteuert hat. Die einzelnen Besuche werden in einer Kalenderansicht abgebildet. Diese kannst du aufrufen, um den jeweiligen Schnappschuss der Seite zu sehen.
Fazit
Sowohl Google-Cache als auch die Wayback Machine können im Fall der Fälle viele Nerven retten. Verlassen sollte man sich auf diese beiden Tools dennoch nicht. Besser ist es, man setzt auf vollständige Backups und spart sich diese beiden Werkzeuge für den absoluten Notfall auf. Denn auch wenn man das Glück haben sollte, alle Inhalte durch Google-Cache oder Archive.org wiederzufinden, ist es schon für eine mittelgroße Website eine extrem mühsame Arbeit, alle Texte, Bilder und sonstiges herauszufischen.
Für Web-Archäologen oder andere Neugierigen, die wissen wollen, wie sich Webprojekte im Wandel der Zeit geändert haben, sind die beiden Tools extrem praktisch.

Tolle Sache! Direkt mal was Wichtiges im Internet-Archiv gefunden. Eine Website, die ich versehentlich gelöscht hatte. Danke!
Google Cache ist doch so gut wie abgeschafft. Ich würde sagen, gut die hälfte aller Websites sind nicht enthalten und auf der Mobilansicht ist der Cache überhaupt nicht verlinkt.
Interessanter Artikel, aktuell hilft er mir allerdings nicht beim Auffinden eines aus dem Sortiment genommenen Produktes, dessen Beschreibung ich zwar habe, aber keinen Link dazu.
Gibt es dazu auch eine Möglichkeit?