
Aufräumen im Code: Wie BEM mehr Modularität in dein Frontend bringt

Anders als noch vor zehn oder 15 Jahren sind Websites heute keine in Stein gemeißelten Rahmen für Layouts mehr, sondern müssen leicht adaptierbare und hoch anpassungsfähige Umgebungen für Inhalte sein. Diese Umgebungen sind jedoch zum Zeitpunkt der Entwicklung meist noch unbekannt. Daher wird ein solides Konstruktionsgerüst benötigt. Methoden wie BEM ermöglichen es, diese Umgebungen semantisch, responsiv, für Entwickler benutzbar und vor allem skalierbar zu machen.
OOCSS war der Anfang
Die größte Veränderung im Prozess, wie Webprojekte umgesetzt werden, war nach den Tabellen-Designs der 90er Jahre die Objektorientierung mit CSS oder kurz OOCSS – ein Begriff und eine Methodik, die Nicole Sullivan aus der klassischen Softwareentwicklung entlehnt hat. Dabei geht es darum, Code in logische und eigenständige Blöcke zu zerlegen, die in weiterer Folge miteinander interagieren können. Anstelle also eine Website aus HTML zu „gießen“, wurden modulare „Objects“ gebaut, die – genauso wie bei Lego-Bausätzen – ein großes Ganzes formten, dabei aber beweglich, verschachtelbar und anpassungsfähig blieben. Die Idee dahinter: Jedes Objekt beziehungsweise jede Komponente muss eigenständig funktionieren können. Diese Abstraktion erlaubte es nun, Konstrukte zu schaffen, die verschachtelbar und unabhängig von anderen Code-Teilen waren.
Nicole Sullivan veröffentlichte 2010 einen Artikel, in dem sie zeigte, wie ein User-Interface mit repetitiven Objekten gestaltet werden kann, ohne zum Zeitpunkt der Implementierung zu wissen, welche Breite, welchen Inhalt und welche Dekorationen das konkrete Objekt möglicherweise haben wird. Das gezeigte User-Interface? Kein geringeres als das von Facebook. Das Media-Object war geboren.
Grids hatten zu diesem Zeitpunkt Tabellen bereits ersetzt, aber der revolutionäre Ansatz von OOCSS erforderte neue Denkansätze – besonders, weil das „Responsive Webdesign“ eine neue Ära einleitete. Code schrieb man jetzt in sich gegenseitig erweiternden Klassen und Sub-Klassen. Aus klobigen und „overqualified“ Beschreibungen des Inhalts des Codefragments wurden leicht zu lesende und semantische Anweisungen.
Diese neue Art zu denken warf aber auch einige Fragen auf: Wie umfangreich darf ein Objekt sein? Wie kann ich Sub-Objekte sinnvoll abbilden? Wie organisiere ich jetzt meinen Code? Welche Selektoren soll ich nutzen? Wie sieht es mit Naming-Conventions aus? All diese Fragen tauchten plötzlich auf, und „Webdesigner“ wurden nun zu „Frontend-Architekten“ geadelt – zu Recht. Denn auf einmal war es nicht mehr möglich, ohne Planung einfach „drauf los“ zu coden: Aus dem „Webdesign“ wurde eine Disziplin, ähnlich anspruchsvoll wie die der Software-Entwicklung. Aus kryptischem und inhaltsbeschreibendem Code wie #sidebar-left .topHead .green wurden sprechende, semantische und universell einsetzbare Objekte wie .sidebar .widget .adspace – weil Klassennamen relevant aber auch neutral sowie sinnvoll, aber auch wiederverwendbar sein sollten.
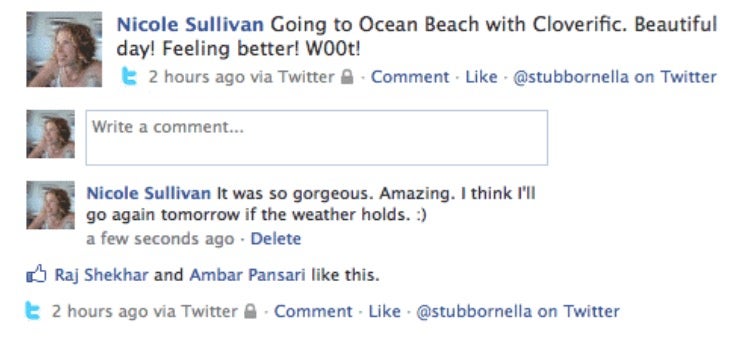
Bei der Entwicklung eines UI ist oft nicht bekannt, welche Breite, welchen Inhalt und welche Dekoration das konkrete Objekt möglicherweise haben wird – so wie bei den Kommentaren in Facebook. (Screenshot: Facebook)
Wie konkret dürfen generische Klassennamen sein, damit sie wiederverwendbar bleiben? Wie baue ich ein Konstrukt an Klassen auf, welches leicht für mein Projekt adaptierbar und gleichzeitig skalierbar bleibt? Das waren die neuen Herausforderungen.
Und es hat BEM gemacht!
Block, Element, Modifier: Diese drei Begriffe wurden von den Entwicklern hinter der russischen Suchmaschine Yandex zu einer Methodologie erhoben, die unser derzeitiges Verständnis von Frontend-Architektur prägt: BEM.
Code wird in Blöcke und deren Elemente zerlegt, welche sich durch Modifikatoren verändern lassen. Ein Block kann aus mehreren Elementen bestehen, welche durch den Modifikator anpassbar sind. Durch dieses einfache Muster ist BEM der ideale Weg, um im Team an Projekten mit sich ändernden Anforderungen zu arbeiten. Die folgenden gezeigten Code-Beispiele sind eine modernere BEM-Adaption von Nicolas Gallagher.
.block{}
Der „Block“ ist das höchste Level der Abstraktion eines Objekts.
.block_ _element{}
Das „Element“ ist konkreter als der Block und hilft dabei, das Objekt zu spezifizieren.
.block– –modifier{}
Der Modifier bildet jeden möglichen Status des Blocks ab.
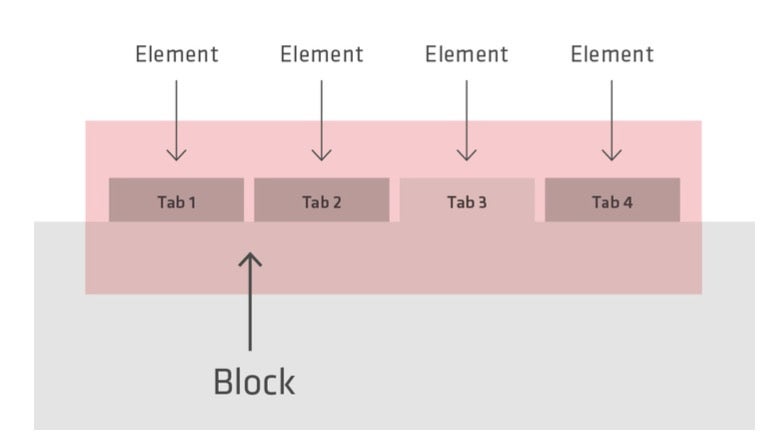
Das Verhältnis zwischen dem Block und seinen Elementen – Tab 3 besitzt einen Modifier.
Obwohl BEM nicht gerade schön anzusehen ist und vielleicht sehr aufwendig erscheint, überwiegen die Vorteile: BEM erlaubt es dem Entwickler, sich nur durch das Lesen der Klassennamen augenblicklich in eine völlig unbekannte Code-Struktur einzulesen.
Suchformular mit herkömmlichen Klassennamen
<form class="site-search full">
<input type="text" class="field">
<input type="Submit" value ="Search“ class="button">
</form>
Listing 1
Der oben dargestellte Code zeigt eine Implementierung, wie sie öfter für Suchfunktionen verwendet wird. Das Problem: Die Klassennamen lassen nur vage erahnen, was sich dahinter verbirgt. Anders mit BEM:
Suchformular mit BEM
<form class="site-search site-search--full">
<input type="text" class="site-search_ _field">
<input type="Submit" value ="Search" class="site-search_ _button">
</form>
Listing 2
Hier wird deutlich, dass .site-search ein Block bzw. eine Komponente ist, welche aus Elementen (.site-search_field und .site-search_button) besteht. Auch, dass es sich bei „full“ um eine Modifikation von .site-search handelt, ist jetzt klarer.
Block beziehungsweise Komponente (manchmal auch Objekt) werden Code-Strukturen genannt, die logisch zusammengehören: In diesem Fall handelt es sich um ein Codefragment, das eine Suchfunktion zur Verfügung stellt. Im Rahmen von BEM ist es wichtig, zwischen generischen beziehungsweise abstrakten Bezeichnungen und spezifischen Codestrukturen zu unterscheiden. Code-Fragmente, die nur einen Zweck haben, sind spezifisch und sollten auch spezifisch benannt werden. Generische Code-Fragmente können in spezifischen Code-Strukturen vorkommen, müssen es aber nicht.
Für die Wiederverwendbarkeit von Code ist es wichtig, wiederkehrende und abstrakte Strukturen generisch zu umschreiben. Dabei sollten die Struktur-Bezeichnungen nicht inhaltsbeschreibend sein – denn darunter leiden die Wiederverwendbarkeit und die Semantik. Ein Code-Fragment etwa, das eine Information anzeigt, eignet sich auch zur Anzeige von Warnungen. Es ist also wichtig, zwischen Inhalt, optischer Darstellung und der Semantik des Code-Fragments zu unterscheiden. Ein Beispiel:
Hinweisfenster mit falschen Spezifikationen
.infobox .infobox-default{}
.infobox .infobox-alert{}
Listing 3
Hier wurde ein abstraktes Fragment falsch spezifiziert beziehungsweise erweitert. Der Name .infobox lässt Interpretation zu und wird durch Sub-Klassen unsinnig spezifiziert. Ein „Hinweis-Fenster“, das eine Warnung ausgibt, könnte in BEM geschrieben so aussehen und wäre zudem auch erweiterbar:
Hinweisfenster in BEM
.label{}
.label--alert{}
.label--info{}
Listing 4
Spezifische Komponenten sollten hingegen spezifische Namen tragen, welche sich durch weitere Sub-Klassen weiter spezifizieren lassen. Diese Aneinanderreihung ermöglicht eine einfache Wahrnehmung selbst von komplizierten Code-Strukturen.
Generell gilt: Abstrakte Code-Strukturen sollen nicht zu spezifiziert benannt werden und spezifische Code-Strukturen dürfen nicht zu abstrakt sein. Es ist besser, .customer-form_name als Modifikator zu implementieren als „nur“ die generische Klasse .name zu wählen, um das Input-Feld des Namens zu bezeichnen. Dabei spielt die Länge der Klassennamen keine Rolle, als Faustregel gilt: Namen sollten so kurz wie möglich und so lang wie nötig sein. Der Informationsgehalt muss allerdings ausreichen, um fremden Entwicklern zu erlauben, Code zu verstehen und zu sehen, was er darstellen soll.
Dieses Prinzip birgt jedoch ein weitreichendes Problem: Ab wann ist die Architektur zu granular? Und wann habe ich mehr Klassennamen als eigentlichen Code? Harry Roberts, der Pionier des OOCSS, sagt dazu Folgendes: „If something does N things, it should have N hooks“. Es ist also nicht nötig, die Klasse .btn-primary in die Klassen .btn-brandcolor, .btn-big und .btn-rounded zu zerlegen, denn der Button erfüllt nur einen Zweck. Wie granular der Code aber letztlich sein soll, hängt vom Projekt ab. So kann es durchaus zweckmäßig sein, gewisse Komponenten granularer zu implementieren als andere.
Es ist nicht alles BEM, was glänzt
Allerdings sollte man nicht den Fehler machen, ab jetzt alles in dieser neuen Methodologie zu schreiben. Nur weil ein Code-Fragment innerhalb eines BEM-Blocks existiert, bedeutet das noch lange nicht, dass es sich dabei um ein BEM-Element handelt. Es ist also unsinnig, Stand-Alone-Klassen in die BEM-Methodologie zu übertragen oder ein Logo wie folgt einzubinden:
Einbinden eines Logos
.header{}
.header_ _logo{}
Listing 5
Das Beispiel zeigt: Das Logo ist nur zufälligerweise innerhalb des „Headers“ positioniert – dabei könnte es sich genauso gut in einer Sidebar, in einem Navigationsmenü oder im Footer befinden. So kann es für diesen konkreten Fall sinnvoller sein, einfach die Klasse „.brand-logo“ oder „.site-logo“ zu nutzen. Es ist unsinnig, zwanghaft jeden Code mit der BEM-Methode zu schreiben.
Ist das Element zufällig dort, wo es ist und kann es auch an einer anderen Stelle im Code existieren? Oder befindet sich das Element dort, weil es Teil eines bestimmten Blocks ist? Wenn der zweite Fall zutrifft, dann ist es sinnvoll, BEM zu nutzen.
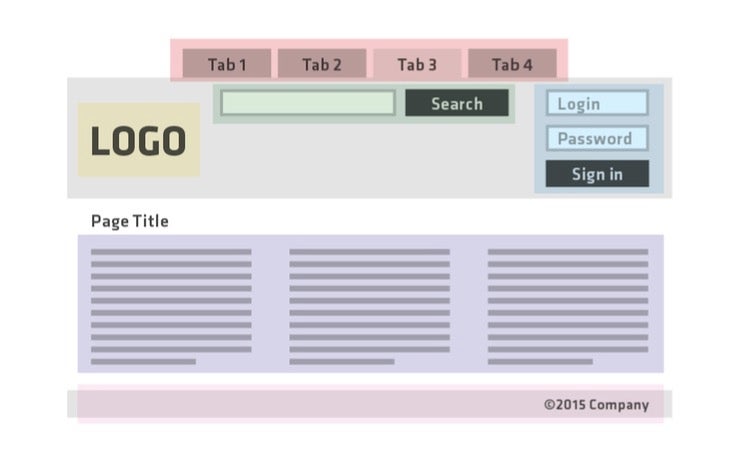
Um zu verstehen, wann die Nutzung von BEM sinnvoll ist, lohnt sich ein Blick auf die einzelnen Elemente – ist ihre Platzierung fix oder könnten sie sich auch an anderer Stelle befinden?
Der BEM-Gedanke lässt sich auch weiter tragen, um die Nutzung für Entwickler noch einfacher zu machen. So ist es möglich, die Unterstriche mit Bindestrichen zu ersetzen, um BEM-Blöcke und -Elemente durch simples Doppelklicken einfacher selektierbar zu machen. Oder: Der Einsatz von „camelCase“ – der Binnenminuskel – macht Klassennamen, die aus mehreren Wörtern bestehen, besser lesbar. Im Folgenden ein Beispiel, wie aus richtiger BEM-Syntax einfach zu lesender Code wird, mit dem man durch besseres Markieren auch komfortabler entwickeln kann:
Klassennamen mit Bindestrich
.block-element{}
.block--modifier{}
.block-name-element-name{}
Listing 6
Klassennamen mit camelCase
.block-element{}
.block--modifier{}
.blockName-elementName{}
Listing 7
An Namenskonventionen anpassbar
BEM ist eine Methodik und ein Versuch, Code verständlicher und einfacher zu schreiben. Dabei ist es variabel genug, um sich an bereits etablierte Namenskonventionen eines Entwicklerteams anzupassen. So wird aus dem klassischen „Media-Object“ eine mit Hilfe von BEM und den oben getroffenen Überlegungen leicht lesbare und portierbare Komponente:
Media-Object, herkömmliche Methode
<div class="media">
<img xsrc="logo.png" alt="Logo von t3n.de" class="img-rev">
<div class="body">
<h3 class="bigger">Große Überschrift</h3>
<p class="bold">Ich bin der Intro-Text!</p>
</div>
</div>
Listing 8
Media-Object mit BEM
<div class="media">
<img xsrc="logo.png" alt="Logo von t3n.de" class="media-img--rev">
<div class="media-body">
<h3 class="alpha">Große Überschrift</h3>
<p class="abstract">Ich bin der Intro-Text!</p>
</div>
</div>
Listing 9
Die Relation zwischen .media und .media-body ist jetzt klarer und außerdem ist erkennbar, dass ein Modifier von .media-img implementiert wurde. Die h3-Überschrift ist semantisch richtig, aus optischen Gründen besitzt sie aber denselben Schriftgrad wie eine h1-Überschrift. Durch das Anwenden des griechischen Alphabets als Klassennamen ergibt sich eine bessere Skalierung. Der Intro-Text ist deutlich ausgewiesen und lässt sich durch die generische Bezeichnung .abstract verschieden und unabhängig gestalten – ohne dabei den HTML-Code zu beeinflussen.
Fazit
Der Schlüssel zu gelungener Frontend-Architektur ist das sinnvolle Benennen des Konstruktionsgerüsts. Es ist also wichtig zu entscheiden, ab wann und wie weit ein Code-Fragment sich im BEM-Kontext auswirkt. BEM produziert zwar mehr Code, aber dieser ist leichter zu warten und zu erweitern. Und genau das ist der Hauptgrund, der für den Einsatz spricht: Frontend-Entwickler schreiben Code, den sie schnell wieder ändern können – weil sie aufgrund der Benennung zu jeder Zeit genau die Funktion erkennen, die ein Code-Element im Gesamtgefüge des Frontends erfüllt.
 Mario Janschitz hat neben dem erfolgreichen Abschluss seines interdisziplinären Studiums (IT/BWL) sein Wissen als Agentur-Inhaber, Dozent, Fachautor, Beirat eines internationalen Konzerns und als Gründer eines IT-Startups praktisch angewandt.
Mario Janschitz hat neben dem erfolgreichen Abschluss seines interdisziplinären Studiums (IT/BWL) sein Wissen als Agentur-Inhaber, Dozent, Fachautor, Beirat eines internationalen Konzerns und als Gründer eines IT-Startups praktisch angewandt.

„Und genau das ist der Hauptgrund, der für den Einsatz spricht: Frontend-Entwickler schreiben Code, den sie schnell wieder ändern können – weil sie aufgrund der Benennung zu jeder Zeit genau die Funktion erkennen, die ein Code-Element im Gesamtgefüge des Frontends erfüllt.“ – Also sehe ich das richtig, wenn man gut und strukturiert benennt, dann ist das das praktisch selbe wie es BEM macht?
Nein. Die wichtigsten Vorteile von BEM werde im Artikel erst gar nicht erwähnt. BEM hat eine schnellere Rendering-Zeit. Das ist dadurch bedingt, dass Klassen nur durch eine Ebene selektiert werden. Selbst wenn du dein CSS gut strukturierst, aber mehrere Ebenen bzw. verschiedene Selektionen nutzt, wird BEM schneller im Rendering sein.
In Zeiten von Less und Sass finde ich die Benutzung des Modifers so aber irgendwie unpraktisch. Einfach ne klasse .full an den verschiedensten Elementen sorgt für eine andere Darstellung und ist easy in der Less-Schreibweise zu benutzen.
Interessanterweise wird auf den wichtigsten Grund der „pro BEM“ ist null eingegangen: Die Vermeidung der Nutzung von Kindselektoren/Vererbung und damit die fehlende Hierarchie bzw. Spezifität. Ein BEM-Selektor ist immer „Einstufig“ und muss somit nicht aufwändig überschrieben werden. Das ist sozusagen die zu Ende gedachte Version von „Keine IDs benutzen“.
Hier mehr dazu: https://css-tricks.com/strategies-keeping-css-specificity-low/
Danke, das sehe ich genauso. Vor allem ist BEM auch nur eine Naming-Convention. Eine, die einen enormen Einfluss hat, aber dennoch nur eine Naming-Convention. Auf OOCSS ist kurz eingegangen wurden, aber eben nur kurz. Es ist wichtig alle Methoden zur Strukturierung von CSS zu kennen. Es wäre besser sich mit SMACSS zu beschäftigen. Denn dort werden noch einmal alle Methoden zusammengefasst.