
Event-Sourcing: Das steckt hinter dem Software-Kontenbuch

(Abbildung: Shutterstock/ Aleksandar Karanov)
Microservices machen es einfach, ein Softwaresystem nachträglich um neue Komponenten zu erweitern. Ein häufiges Problem sind allerdings die von den Microservices verwalteten Daten – vielleicht werden nach einem Jahr im Betrieb für eine neue Anforderung auf einmal Informationen benötigt, die eigentlich von Anfang an hätten erhoben werden müssen. Oder es fehlen historische Daten, die von der Software schon längst verworfen wurden. In solchen Fällen kann Event-Sourcing helfen.
Das Kernprinzip des Event-Sourcings ist einfach: Eine Software speichert nicht nur den aktuellen Zustand ihres Anwendungsbereichs, sondern auch jedes Ereignis, das jemals aufgetreten ist und zu einer Veränderung dieses Zustands geführt hat.
Das dahinterstehende Prinzip ist nicht besonders neu, sondern im Grunde genommen seit Jahrtausenden bekannt. Denn auch ein analog mit Stift und Papier geführtes Kontenbuch eines Buchhalters ist nichts anderes: Ab der Eröffnung eines Kontos wird jede Buchung (also jedes Event) einzeln festgehalten. Innerhalb der Buchung sind alle relevanten fachlichen Informationen gespeichert, etwa die Veränderung des Bestands und – wer es genauer will – die Soll- und Habenseite der Buchung sowie zugehörige Metadaten wie etwa das Datum und ein beschreibender Text.
(Abbildung: Martin Helmich / t3n)
Fragt den Buchhalter nun jemanden nach dem aktuellen „Zustand“ des Kontos, lässt sich dieser jederzeit aus der Gesamtheit aller Buchungen rekonstruieren: Es müssen nur die Beträge aller einzelnen Transaktionen verrechnet werden. Das Spannende dabei: Mit so einem Rebuild lässt sich anhand der Events nicht nur der aktuelle Zustand des Kontos rekonstruieren, sondern der Zustand zu jedem beliebigen Zeitpunkt. Um den Kontostand zu einem bestimmten – aber beliebigen – Zeitpunkt zu ermitteln, müssen beim Rebuild lediglich die Events bis zu diesem Zeitpunkt berücksichtigt und alle Nachfolgenden vernachlässigt werden – und schon ist die Point-in-Time Recovery geglückt.
Sind irgendwann richtig viele Buchungen im Kontenbuch, wird es der Buchhalter womöglich leid, für einen aktuellen Saldo immer wieder alles neu aufsummieren zu müssen. Deshalb wendet er einen Trick an: In regelmäßigen Abständen – beispielsweise am Ende jedes Tages, jeder Woche oder jedes Monats – ermittelt er den aktuellen Saldo (also den Zustand des Kontos) und hält ihn im Kontenbuch fest. Falls dann zwischendurch jemand nach einem aktuellen Kontenstand fragt, braucht er nur noch Buchungen dazurechnen, die seitdem hinzugekommen sind. Auf diese Art erstellt er einen Snapshot, auf dem er zu einem späteren Zeitpunkt einfach wieder aufbauen kann.
Event-Sourcing in der Softwareentwicklung
In der Softwareentwicklung wird Event-Sourcing natürlich nicht mit Stift und Papier umgesetzt. Dennoch folgt es denselben Regeln wie das Beispiel aus der analogen Welt.
Auch in einer Event-Sourcing-Anwendung wird üblicherweise der aktuelle Zustand der Applikation verwaltet, beispielsweise in Form eines oder mehrerer Objekte. Ein Inventar, das den Lagerstand verschiedener Gegenstände verwaltet, könnte beispielsweise über eine Klasse Inventory abgebildet sein:
class Inventory {
public items: Record<string, number> = {};
}Nebenbei: Als Programmiersprache für die Beispiele wird hier Typescript verwendet. Die grundlegenden Prinzipien sind jedoch auf nahezu alle Programmiersprachen anwendbar.
Im nächsten Schritt können verschiedene Events definiert werden, die den Zustand des Lagers verändern – beispielsweise wenn Gegenstände entnommen werden oder das Lager wieder aufgefüllt wird:
interface InventoryEvent {
when: Date;
userID: string;
apply(on: Inventory): void;
}
class RemovedItemFromInventory implements
Event {
public constructor(
public readonly when: Date,
public readonly userID: string,
public readonly item: string,
public readonly amount: number
) {}
public apply(inv: Inventory) {
if (this.item in inv.items) {
inv.items[this.item] = Math.max(
inv.items[this.item] - this.amount,
0
);
}
}
}
class RestockedInventory implements Event {
// ...
}Um das Ganze anzusteuern, kann ein Command Handler implementiert werden, der dann beispielsweise als Webservice angesprochen werden könnte. Er übersetzt Nutzerinteraktionen – wenn etwa eine Entnahme verbucht werden soll – in Events, die dann auf den aktuellen Zustand angewandt und über einen Event-Bus veröffentlich werden:
class InventoryCommandHandler {
private inventory: Inventory;
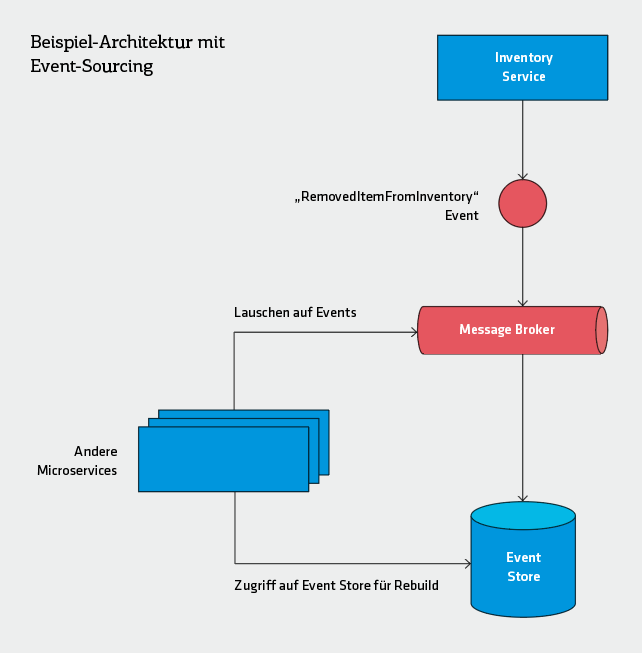
private eventBus: EventBus; public removeItemsFromInventory(item: string, amount: number) { const evt = new RemovedItemFromInventory( new Date(), "martin", item, amount, ); evt.apply(this.inventory); this.eventBus.publish(evt); } }In einer Event-Sourcing-Architektur müssen Events dauerhaft und bestenfalls an zentraler Stelle – in einem Event Log – gespeichert werden. Im obigen Beispiel könnte der eventBus.publish-Aufruf also beispielsweise dafür zuständig sein, das erstellte Event über den Message-Broker einer Publish-/Subscribe-Architektur zu veröffentlichen. Auf diese Weise können andere Services der Microservice-Architektur auf das Event reagieren – und das Event kann ebenso direkt gespeichert werden.
Das Schaubild auf Seite 157 zeigt eine Beispielarchitektur mit Event-Sourcing: Microservices veröffentlichen hier Events an einem Message-Broker, von wo aus sie persistent in einem Event-Store gespeichert werden. Microservices können außerdem am Message-Broker auf Events warten, um sie in Echtzeit zugestellt zu bekommen, oder über den Event-Store auf historische Events zugreifen.
Ebenfalls interessant: Mit Tools wie Jaeger bei Microservices die Übersicht behalten
Mit Event-Sourcing lässt sich also sehr einfach auf neue Anforderungen an die Software reagieren und neue Geschäftsregeln können rückwirkend auf den Datenbestand angewandt werden. In so einem Fall könnte der Zustand der Applikation einfach aus dem Event-Log wiederhergestellt und bei diesem Rebuild schon an die neuen Geschäftsregeln angepasst werden. Auch Reporting-Anforderungen, die häufig historische Daten benötigen (Wie häufig und wie lange war Artikel X im letzten Jahr nicht auf Lager?), können anhand des Event-Logs einfach im Nachhinein beantwortet werden.
Weil ein Rebuild bis zu einem ganz bestimmten Zeitpunkt durchgeführt werden kann, kann jeder Zustand wiederhergestellt werden, den die Applikation an einem beliebigen Zeitpunkt hatte. Das nennt man Point-in-Time-Recovery. Sie kann auch beim Debugging unterstützen, wenn beispielsweise in einer Entwicklungsumgebung die exakten Umstände zu dem Zeitpunkt nachgestellt werden sollen, an dem ein bestimmter Bug aufgetreten ist. Zusätzlich gibt es ein Audit-Log – also ein Protokoll darüber, welcher Nutzer, wann welche Aktion ausgeführt hat.
Hohe Komplexität
Event-Sourcing klingt schön – und das erste Beispiel mutet auch noch überschaubar an. In der Praxis ist das Architekturmuster aber gar nicht so einfach zu implementieren. Insbesondere in verteilten Microservice-Architekturen wird zunächst einmal die Infrastruktur benötigt, um überhaupt Events veröffentlichen und verteilen zu können – Event-Sourcing-Architekturen bauen daher häufig auf der Publish/Subscribe-Architektur mit einem zentralen Message-Broker wie etwa RabbitMQ oder Apache Kafka auf.
Als Nächstes müssen sämtliche Events natürlich irgendwo gespeichert werden. In größeren Anwendungen können schnell sehr viele Events anfallen; und weil es immer sein kann, dass auch alte Events für einen Rebuild noch benötigt werden, können in der Regel auch keine gelöscht werden. Aus diesem Grund sollte für das persistente Event-Log eine Datenbank ausgewählt werden, die gut mit wachsenden Datenmengen mitskalieren kann. Wenn viele verschiedene Event-Typen, in denen unterschiedliche Daten gespeichert sind, verarbeitet werden, sollte die Event-Datenbank zudem kein festes Datenschema vorgeben. Beide Anforderungen werden von modernen NoSQL-Datenbanken – beispielsweise MongoDB, Elasticsearch oder Cassandra – gut unterstützt. Auch in üblichen Public-Cloud-Angeboten finden sich geeignete Lösungen wie etwa Amazon DynamoDB oder Azure CosmosDB.
Zu guter Letzt gibt es Frameworks, die den Aufbau einer Event-Sourcing-Architektur von Anfang bis Ende unterstützen wollen. Das sind zum Beispiel das Axon-Framework für Java und das Eventflow-Framework für C#. Darüber hinaus hält sich die Verfügbarkeit guter Event-Sourcing-Frameworks – auch für andere Programmiersprachen – bisher noch in Grenzen.
Dilemma Datenschutz
Spätestens bei „alte Events werden nicht gelöscht“ sollten beim Datenschützer alle Alarmsirenen schrillen. Eine Event-Sourcing-Architektur ist jedoch darauf angewiesen, dass alte Events dauerhaft erhalten bleiben – wie beim Kontenbuchbeispiel von oben.
Dumm nur, wenn die für den Rebuild benötigten Events personenbezogene Daten enthalten, für deren Verarbeitung möglicherweise keine Rechtsgrundlage mehr besteht und die ansonsten einfach hätten gelöscht werden können. Ein möglicher Weg zum Umgang damit könnte sein, solche Events beim Entfall der Rechtsgrundlage so zu anonymisieren, dass sie nicht mehr personenbeziehbar sind – aus „Zahlungseingang über 100 Euro von Kunde Max Mustermann“ würde dann einfach „Zahlungseingang über 100 Euro von gelöschtem Kunden“. So oder so sollten derartige Löschkonzepte stets auf den jeweiligen Einzelfall bezogen mit einem Datenschutzexperten abgestimmt werden.
Event-Sourcing ist also ein mächtiges Architekturmuster, das in der Softwareentwicklung zahlreiche Möglichkeiten eröffnet. Der Preis dafür sind eine weitaus höhere Komplexität der Software sowie ein (noch) nicht allzu großes Ökosystem an Bibliotheken und Frameworks – wer das Architekturmuster implementieren will, muss daher oft selbst Hand anlegen. Ob die dadurch gewonnenen Vorteile den Preis des Implementierungsaufwands und der höheren Komplexität rechtfertigen, muss allerdings jedes Entwicklungsteam für sein Projekt selbst entscheiden.

Für Node.js gibt es auch ein event-sourcing Framework:
https://github.com/thenativeweb/wolkenkit