Extract, Transform, Load: ETL-Lösungen auf einen Blick

(Abbildung: Shutterstock / hanss)
Wie viele Nutzer besuchen unsere Website jeden Monat? Wie viele Signups haben wir täglich? Welche Features werden am häufigsten verwendet? Solche Fragen kann man schnell mit passenden Tools wie Google Analytics oder Mixpanel beziehungsweise mit einfachen Datenbankabfragen beantworten. Doch früher oder später reichen solche einfachen Metriken nicht mehr aus. Wenn das Unternehmen wächst oder es immer schwieriger wird, Kunden zu gewinnen und ans Unternehmen zu binden, tauchen komplexere Fragen auf, die sich nicht so leicht beantworten lassen: Wie hoch ist die Kundenzufriedenheit von Nutzern aus den USA, die über laufende Adwords-Kampagnen gewonnen wurden? Welches Kundensegment hat die höchste Kundenbindungsrate? Welchen Einfluss hat der Kundensupport auf unsere Churn-Rate? Wer Antworten auf solche Fragen sucht, muss Metriken aus verschiedenen Fachabteilungen und Systemen zusammenbringen und zentral auswerten.
In der Praxis ist das allerdings alles andere als einfach. Laut einer aktuellen Auswertung von Siftery, einem Portal, in dem Unternehmen ihre verwendeten Apps auflisten, kommen im Durchschnitt pro Firma 37 verschiedene Softwarelösungen zum Einsatz – bei Großunternehmen sind es sogar rund 90. Bei all den Vorteilen, die dieser „Best of Breed“-Ansatz mit sich bringt – kostengünstige Lösungen, einfache und schnelle Implementierung und mehr – müssen Unternehmen einen entscheidenden Nachteil in Kauf nehmen: Datensilos. Wenn jede Fachabteilung mit ihren eigenen Lieblingstools arbeitet, bleiben wichtigen Daten für die anderen Teams oft unzugänglich.
Dies wird zum Problem, wenn man abteilungsübergreifende Analysen über Kunden, Produkte, Vertrieb oder Marketing anstellen und kritische Metriken wie Neukundengewinnung oder Retention optimieren möchte. Die Rohdaten müssen zunächst aus ihren Silos befreit und an einem zentralen Ort konsolidiert werden. Datenredundanz, Inkonsistenzen und Kompatibilitätsprobleme sind dabei unvermeidbar. Im nächsten Schritt muss sichergestellt werden, dass die nötigen Daten in regelmäßigen Zeitabständen aktualisiert werden, denn die Analyse von historischen Metriken ist selten genügend. Diese Herausforderungen lassen sich mithilfe sogenannter ETL-Systeme (Extract, Transform, Load) deutlich einfacher meistern.
So funktionieren ETL-Systeme
ETL-Systeme versetzen Unternehmen in die Lage, Daten aus den unterschiedlichsten Quellen unter einen Hut zu bringen. Seien es Besucherzahlen von der Unternehmenswebsite aus Google Analytics, Kundenfeedback aus dem Help-Desk-System oder Benutzeraktionen, Logs und Events, die in der eigenen Anwendung mit Tools wie Mixpanel oder Kissmetrics erfasst wurden. Nachdem solche Daten aus ihren Silos befreit wurden (Extract), lassen sie sich mithilfe diverser Tools im ETL-System bearbeiten (Transform), um sie in ein einheitliches Format zu bringen, beziehungsweise um Datenredundanzen zu beseitigen. Anschließend werden die extrahierten Daten in der Regel in ein Data-Warehouse wie Google Bigquery oder Amazon Redshift beziehungsweise in einen Data Lake exportiert (Load), wo sie dann zur zentralen Analyse aufbereitet werden können. Einige Lösungen bieten zudem die Möglichkeit, Daten nach relationalen Datenbanksystemen wie MySQL oder in einfachen Dateien (CSV, JSON, etc.) zu exportieren, die sich lokal oder in einem Cloud-Storage-System speichern lassen.
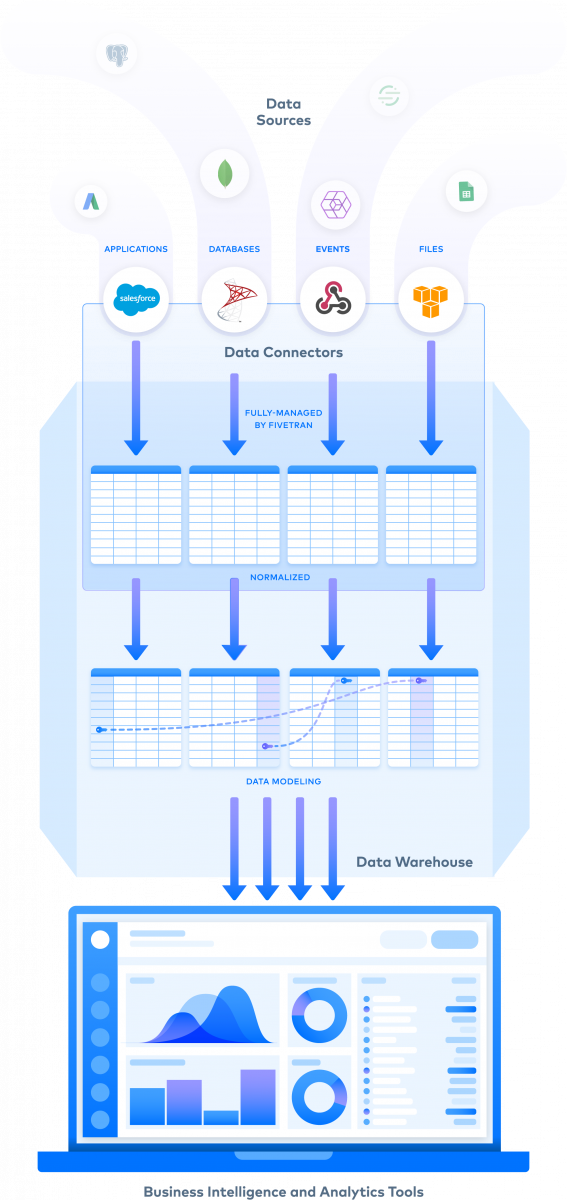
Mehr als 70 Anwendungen lassen sich per integriertem Konnektor an die ETL-Lösung Fivetran anbinden. Zudem können Anwender eigene benutzerdefinierte Konnektoren in Serverless-Umgebungen erstellen. (Abbildung: Fivetran)
Mithilfe von ETL-Tools lassen sich diese Prozesse vollständig automatisieren. Das spart Zeit und Ressourcen gegenüber dem manuellen Export in das Data-Warehouse. Auch Entwickler profitieren vom Einsatz der Tools, da sie keine Datenintegrationen über die API der verschiedenen Lösungsanbieter und Cronjobs für die regelmäßige Datenabfrage mehr selbst implementieren müssen. Sobald die Daten erst einmal im Data-Warehouse gespeichert sind und die kontinuierliche Aktualisierung sichergestellt ist, können Unternehmen auf Business-Intelligence-Lösungen wie Google Data Studio oder Klipfolio zurückgreifen, um Dashboards und Berichte zu erstellen, die dann für Planung, Monitoring und weitere Analysen in den einzelnen Abteilungen genutzt werden können.
Moderne ETL-Lösungen für Einsteiger
Wer denkt, ETL-Systeme seien nur für große Unternehmen relevant, täuscht sich: Inzwischen gibt es eine ganze Reihe moderner Cloudlösungen, die kleine und mittlere Firmen adressieren.
Stitch
Ein gutes Beispiel ist Stitch, ein moderner ETL-Dienst, der im Jahr 2016 gestartet worden ist und einen einfachen Einstieg in die Welt der automatisierten Datenintegration verspricht. Er will Unternehmen in die Lage versetzen, Daten für Fachabteilungen und Analysten innerhalb von Tagen, statt Wochen bereitstellen zu können. Als Datenquelle werden mehr als 80 Online-Dienste unterstützt, darunter Marketingtools wie Google Analytics, Marketo und Mixpanel sowie Productivity-Apps wie die Projektmanagementlösungen Jira und Trello und das Zeiterfassungstool Harvest.
Mithilfe eines modernen User-Interfaces erstellen Anwender ihre Data-Pipelines per Drag & Drop. Die Extraktions-, Transformations- und Ladeprozesse lassen sich dabei nach eigenen Anforderungen konfigurieren und vollständig automatisieren. So kann man das System beispielsweise so einstellen, dass Daten aus Google Analytics alle drei Stunden extrahiert, aufbereitet und nach Bigquery exportiert werden.
Statt die Daten in ein Data-Warehouse zu laden, können Unternehmen sie auch direkt an Business-Intelligence-Lösungen wie Chartio oder Klipfolio anbinden. Ein weiterer Vorteil für Einsteiger besteht im Freemium-Modell des Anbieters: Wer sich einen ersten Eindruck von den Möglichkeiten des Systems machen möchte, kann es kostenlos mit bis zu fünf Datenquellen nutzen, solange die Grenze von fünf Millionen Data-Rows pro Monat nicht überschritten wird. Unternehmen, die monatlich zwischen fünf und 250 Millionen Zeilen bearbeiten wollen, müssen zwischen 100 und 1.000 US-Dollar pro Monat auf den Tisch legen.
Alooma
Alooma mit Stammsitz in Redwood City, Kalifornien, wird zwar als „Enterprise Data Pipeline Platform“ vermarktet. Mit ihrem flexiblen Preismodell, das ab 20 Dollar pro eine Million Rows im Monat startet, kommt die Lösung aber nicht nur für große Unternehmen infrage. Anwender können beliebige Daten aus Datenbanken und zahlreichen Cloudanwendungen extrahieren, ebenso wie aus XML-, JSON- und CSV-Dateien, die in Cloud-Storage-Systemen wie Box und Google Drive gespeichert sind. Auch die Anbindung von On-Premise-Servern ist über FTP möglich. Hinzu kommen API und SDK (Software Development Kits) für populäre Programmiersprachen wie Java und Python und mobile Systeme (iOS und Android), die Kunden nutzen können, um Daten direkt aus ihren Anwendungen nach Alooma zu senden. Mit Alooma Live steht zudem ein interessantes Feature zur Verfügung, das man nicht bei jedem ETL-Tool findet: Das Echtzeit-Visualisierungstool ermöglicht es Datenwissenschaftlern und Entwicklern, Datenströme live überwachen und kontrollieren zu können.
Fivetran
Fivetran stammt ebenfalls aus Kalifornien und ist 2013 aus dem renommierten Startup-Inkubator Y Combinator heraus gegründet worden. Inzwischen zählt das Unternehmen über 100 Mitarbeiter und kann namhafte Kunden wie den Payment-Anbieter Square vorweisen. Neben nativen Konnektoren für über 70 Cloudanwendungen können Anwender auch Daten aus eigenen Datenbanken extrahieren. Dabei werden so gut wie alle populären Datenbanksysteme unterstützt, von klassischen SQL-Systemen wie MySQL, PostgreSQL und Microsofts SQL-Server über dokumentenorientierte Systeme wie MongoDB bis hin zu modernen Clouddatenbanken wie Amazon Aurora und DynamoDB. Für jede angebundene Datenquelle generiert das System automatisch ein übersichtliches Entity-Relationship-Diagramm (ERD), um sicherzustellen, dass die Daten leicht verständlich und problemlos abzufragen sind. Hinzu kommt die Möglichkeit, benutzerdefinierte Konnektoren in einer Serverless Umgebung wie Amazon Lambda oder Google Cloud Functions zu erstellen. Die serverlosen Funktionen werden dann von Fivetran in benutzerdefinierten Zeitabständen abgerufen und die Daten in das Data-Warehouse geladen. Kunden haben die Auswahl zwischen Bigquery, Redshift, Azure SQL, Data-Warehouse und Snowflake.
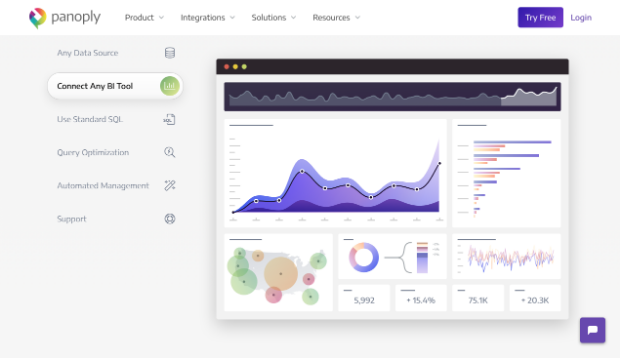
Die All-in-One-Plattform
Panoply bietet neben zahlreichen Integrationsmöglichkeiten ein eigenes Data-Warehouse und ermöglicht die direkte Anbindung an Business-Intelligence-Tools. (Screenshot: Panoply)
Panoply
Eine weitere Lösung, von der Startups und KMU profitieren können, ist Panoply. Der in Tel Aviv entwickelte Dienst präsentiert sich als Smart-Data-Warehouse, das ETL-Tools und eine Data-Warehouse-Lösung auf einen gemeinsamen Nenner bringt. Damit können Anwender nicht nur unterschiedliche Datenquellen anbinden und Daten automatisiert extrahieren sowie transformieren, sondern sie auch direkt in Panoply lagern. Aus den extrahierten Daten lassen sich Datentabellen erstellen, die frei konfigurierbar und sofort einsatzbereit sind. Anwender, die sich für Panoply entscheiden, müssen also die Daten nicht nach Redshift, Bigquery oder in ein anderes Data-Warehouse exportieren. Um die Daten auszuwerten, lassen sich populäre BI-Tools wie etwa Bime oder Tableau Software integrieren. Die monatlichen Preise beginnen ab 250 Dollar für 25 Millionen Rows und 12,5 Gigabyte Speicherplatz.
Mit Xplenty bietet sich eine weitere professionelle ETL-Lösung, die ebenfalls aus Tel Aviv stammt. Größere Unternehmen mit erhöhten Anforderungen rund um Sicherheit und Compliance sollten sich auch die Lösungen der Enterprise-Klasse wie Talend, Matillion, Nexla und Adeptia näher anschauen.
Alternative Datenintegrationslösungen
Neben diesen ETL-Systemen, die für ein breites Publikum konzipiert sind und die typischen Anwendungsfälle rund um Datenintegration und Analytics unterstützen, gibt es zahlreiche Alternativen, die eine Marktnische adressieren oder spezielle Use-Cases abbilden. So fokussiert sich StarfishETL zum Beispiel auf die Integration und Migration von CRM-Daten, während Dataloader.io sich dem Import und Export von Salesforce-Daten widmet. Mit dem günstigen Datenintegrationstool Skyvia kann man Daten aus vielen Cloudanwendungen extrahieren, aber nur in einfachen Dateien (CSV, JSON, etc.) ausgeben. Die Cloudriesen Amazon und Google wiederum bieten mit Data-Pipelines beziehungsweise Cloud-Dataflow ebenfalls kostengünstige Datenintegrationsdienste, mit denen Daten, die in der jeweiligen Cloud gespeichert sind, sich automatisiert nach Redshift beziehungsweise Bigquery exportieren lassen. Die praktischen Konnektoren für SaaS-Dienste von Drittanbietern sucht man hier jedoch vergeblich.
Segment fokussiert sich auf Kundendaten
Ebenfalls erwähnenswert ist Segment, das zwar keine ETL-Lösung im engeren Sinne, aber dennoch eine attraktive Alternative für Einsteiger ist, die ihre Kunden besser verstehen möchten. Anders als die meisten ETL-Systeme fokussiert sich das in San Francisco gegründete Startup, das bis dato rund 100 Millionen Dollar eingesammelt hat, ausschließlich auf Kundendaten. Es vermarktet seine Lösung als „Customer Data Infrastructure“-Plattform, mit der Firmen sämtliche Kundeninformationen, egal wo sie entstehen und gespeichert werden, auf einen gemeinsamen Nenner bringen können. Firmen wie Levi’s, Trivago und IBM setzen Segment schon ein, um ein unternehmensweites, einheitliches Verständnis ihrer Kunden zu gewinnen. Mit Preisen, die bei 120 Dollar pro Monat anfangen, kommt Segment auch für kleinere Unternehmen in Frage. Der Dienst ermöglicht die automatisierte Datenintegration mit über 200 Systemen. Entwickler können zudem die nativen SDK von Segment in ihre Apps integrieren und sämtliche User Actions und Logs selbst erfassen.
Fazit
Ein klares, detailliertes Kundenverständnis, das auf Basis kontinuierlicher Analysen stetig an neue Gegebenheiten angepasst wird, verschafft Unternehmen entscheidende Vorteile im Markt. Um ein solches Kundenverständnis zu erreichen und es jeder Fachabteilung zugänglich zu machen, brauchen Unternehmen eine Infrastruktur, mit der Daten aus unterschiedlichen Kanälen gesammelt, an einem zentralen Ort gespeichert und analysiert werden können. ETL-Lösungen wie Stitch, Alooma oder auch Segment machen genau dies möglich – und versetzen neben etablierten Konzernen zunehmend auch Startups in die Lage, diese komplexen Prozesse vollständig zu automatisieren.
ETL-Lösungen in der Übersicht findet ihr hier.
