
Frameworks für Machine Learning: So gelingt der Einstieg in die KI-Entwicklung
")
(Grafik: Shutterstock)
Eine Frau in Japan erkrankt an Blutkrebs. Mehrere Monate lang wird sie in einem Krankenhaus mit zwei Medikamenten behandelt, die in der Branche als zuverlässig gelten. Doch der Genesungserfolg bleibt aus. Der Zustand der Frau verschlechtert sich, die Ärzte sind ratlos. Daraufhin geben sie die genetischen Daten der Patientin, die sich während der Behandlung verändert hatten, in Watson ein. Die künstliche Intelligenz von IBM vergleicht die Daten innerhalb weniger Minuten mit denen von 20 Millionen anderer Patienten. Das Ergebnis: Die Frau aus Japan leidet an einer besonders seltenen Form von Blutkrebs. Ein von IBM Watson vorgeschlagene Ersatzmedikament schlägt schließlich an. Schon kurze Zeit später kann die Frau das Krankenhaus verlassen.
Auch wenn das Beispiel noch zu den wenigen Einzelfällen in der Wirtschaftswelt gehört: Von solchen oder ähnlichen Szenarien wie in Japan träumen inzwischen viele Unternehmen, wenn es darum geht, eigene Anwendungen rund um das Thema künstliche Intelligenz und Machine Learning zu entwickeln. Schließlich kann sich eine Investition in wertvollen Zeit- und Kosteneinsparungen niederschlagen. Die rasante Verbreitung entsprechender Technologien stellt Unternehmen jedoch vor zwei gravierende Probleme: Es fehlt an Know-how über die Datengewinnung aus dem laufenden Betrieb einerseits und an qualifizierten Entwicklern andererseits. Umso wichtiger ist es, sich selbst mit den Grundlagen der Thematik vertraut zu machen. Auf den nachfolgenden Seiten zeigen wir, wie das gelingt.
Was ist Machine Learning?
Am Anfang steht etwas Lesearbeit, die man am besten mit entsprechenden Büchern oder in Online-Tutorials verbringt. Ein absoluter Klassiker ist mittlerweile der Onlinekurs, von Andrew Ng3, einem der bekanntesten Professoren im Feld des Machine Learnings an der Stanford University im Silicon Valley. Durch den Kurs ist es auch möglich, außerhalb einer Elite-Universität mit State-of-the-Art-Technologien in Berührung zu kommen.
Das führt auch schon zu einer weiteren wichtigen Erkenntnis: Das Feld des Machine Learnings ist sehr akademisch. Wer die Theorien hinter diesen Algorithmen tiefgreifend verstehen will, muss viel Zeit investieren. Das gelingt oftmals nur durch ein langwieriges Studium. Erst danach ist man in der Lage, diese Algorithmen zu verstehen und zu optimieren. Allerdings ist das noch lange kein Grund, aufzugeben. Zahlreiche Frameworks bieten auch Einsteigern die Möglichkeit, Machine Learning anhand der praktischen Ausführung vortrainierter Modelle zu verstehen.
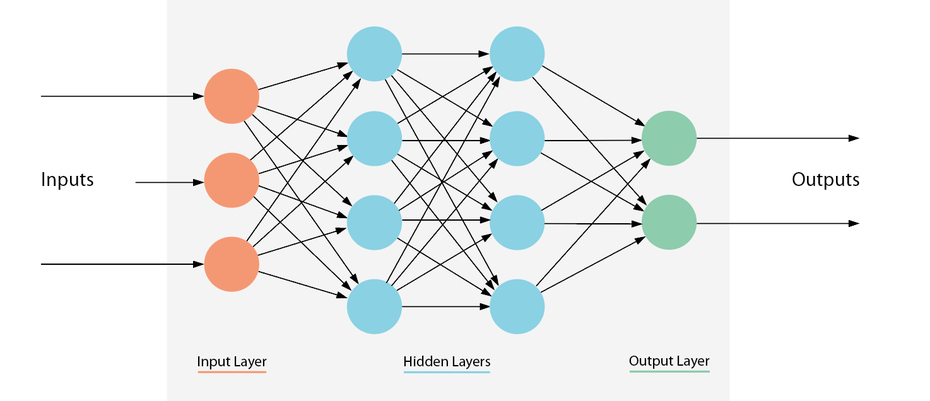
Neuronale Netze sind in Ebenen aufgebaut, die aus einer Reihe von miteinander verbundenen Knotenpunkten bestehen. Netze können Dutzende oder hunderte verborgener Ebenen enthalten. (Grafik: t3n)
Es gibt verschiedene Formen des Machine Learnings: Supervised (überwacht), semi-supervised (halbüberwacht), unsupervised (unüberwacht) und Reinforcement (verstärkendes) Learning. Ist ein Algorithmus supervised, so weiß er beispielsweise durch ein Label, dass ein konkreter Datenpunkt zu einer bestimmten Klasse gehört oder einen spezifischen Zielwert hat. Ein Beispiel wären hier künstliche neuronale Netze oder Entscheidungsbäume (engl.: Decision Tree). Ist der Algorithmus dagegen unsupervised, so muss er selbst herausfinden, was der Zielwert oder die Klasse des Datenpunkts ist. Am meisten verbreitet ist jedoch das Supervised Learning. Deshalb beschäftigen sich auch viele Tutorials vornehmlich damit, was Einsteigern sehr entgegenkommt.
Im Falle des Supervised Learnings erhält der Datenpunkt neben seiner Repräsentation als Vektor (der sogenannte „Feature-Vektor“) noch ein Label. Benutzt man einen Klassifikator (Datenpunkte werden Klassen zugeordnet), so ist das Label die Klassenbezeichnung, zu der dieser Datenpunkt gehört. Anhand dieser Klasse versucht der Algorithmus dann während des Trainings, die Datenpunkte korrekt zu separieren. Neben der Klassifikation existiert auch die Regression. Hier gibt es keine Klassen. Das Label ist in diesem Fall ein Zahlenwert – der Zielwert für diesen Datenpunkt. Soll beispielsweise ein Modell gebaut werden, dass die monatliche Miete einer Wohnung anhand diverser Faktoren schätzt (Anzahl der Bäder, Anzahl der Schlafzimmer, Quadratmeterzahl), so lassen sich diese Faktoren als Features bezeichnen und die geschätzte Miete als Label (oder Zielwert).
Machine Learning kann sehr viele Probleme lösen und bei wichtigen Entscheidungen assistieren. Bezieht die Maschine menschlichen Input in ihre Entscheidung mit ein, spricht man von Human-in-the-Loop (HITL). Wie eingangs schon erwähnt, kann Watson von IBM beispielsweise helfen, im Krankheitsfall die richtige Diagnose zu stellen. Algorithmen in autonomen Fahrzeugen wiederum werden in der Zukunft auf Basis von Machine-Learning-Algorithmen dafür sorgen, dass Menschen sicher ans Ziel kommen.
Für den Anfang sollte man sich allerdings einfacheren Projekten zuwenden, die man auch in kurzer Zeit lösen und damit eine eigene Anwendung oder Startup-Idee umsetzen kann. Dort steht man meist vor reinen Datenverarbeitungsproblemen wie Bilderkennung oder der maschinellen Verarbeitung von Text. Für diese Probleme existieren sogar meist schon Lösungen auf Stackoverflow und Github.
Geeignete Daten suchen
Allerdings benötigt jede gute Statistik eine repräsentative Menge von Stichproben, damit sie aussagekräftig ist. Das bedeutet, dass man eine große Menge von Datenpunkten benötigt, damit die trainierten Modelle smart werden und die richtigen Entscheidungen treffen.
Doch woher kommen diese Daten? Es gibt diverse Portale, die freie Datensets anbieten. Auf Kaggle treten Machine Teacher gegeneinander in Wettkämpfen an, indem sie auf freien Datensets ihre Algorithmen testen. Im UCI Machine Learning Repository findet man 438 Datensets zu diversen Themen über die Klassifikation von Buzz in Social-Media-Channels bis hin zu einer Regression von Facebook-Metriken. Ein weiteres Daten-Repository stellt Datahub dar. Dort haben sich die Gründer Adam Kariv und Rufus Pollock ihren Traum von einem offenen Austauschplatz für Daten erfüllt. Auch die Administrationen von Staaten haben viele Daten, die sie zur Verfügung stellen wollen. Darunter sind Bereiche wie Landwirtschaft, Klima, Bildung und viele mehr. Ein Beispiel für dieses Vorgehen findet sich für die USA auf der Plattform data.gov.
Wurde ein Datensatz ausgewählt, der die Anwendung trainieren soll, kann man im Prinzip sofort starten. Als nächstes muss die Entscheidung fallen, was man mit diesen Daten tun will. Lohnt sich für dieses Datenset eine Klassifikation? Die Frage kann mit „Ja“ beantwortet werden, wenn das Datenset über ein Klassenlabel verfügt. Dabei handelt es sich meist um alphanumerische Bezeichner (beispielsweise „Spam“ und „Nospam“ in einer Antispam-Datenbank). Oder ist hier eher eine Regression sinnvoll? Die Antwort fällt positiv aus, wenn das Datenset über einen nummerischen Zielwert verfügt (beispielsweise der Kurs bei einer Aktienvorhersage).
Ebenfalls empfehlenswert ist KNIME (Konstanz Information Miner) – ein graphisches Tool zur Datenanalyse. Mit KNIME kann man schnell und unkompliziert seine Daten visualisieren, auswerten und Modelle darauf trainieren. Die Software bietet die gängigsten Diagramme und Darstellungen an, die man in der Statistik benutzt. Nachdem man das Datenset angeschaut und studiert hat, kann man mit KNIME bereits durch „Drag and Drop“ bequem die Komponenten für eine Machine-Learning-Anwendung verbinden und auf Play drücken.
Da sich graphische Tools besonders gut für den Einstieg und die Visualisierung der Arbeitsschritte eignen, empfiehlt es sich, wenigstens einmal kurz den Workflow zu skizzieren, nämlich erst das Training eines Machine-Learning-Modells und danach das Testen beziehungsweise Evaluieren des Modells. Eine Alternative zu KNIME ist das Programm Rapidminer.
Das richtige Framework nutzen
Will man allerdings ohne eine graphische Benutzeroberfläche an dem Code der Anwendung arbeiten und das fertige Modell in eine Anwendung integrieren, muss man sich einer Programmiersprache bedienen. Zum Glück sind fast alle gängigen Programmiersprachen für die Entwicklung von Machine-Learning-Anwendungen geeignet. Es gibt kaum Einschränkungen und die Communities rund um diese Programmiersprachen sind meist sehr schnell, wenn es darum geht, neue Bibliotheken einzubinden.
Hat man keine besonderen Präferenzen, so ist Python eine Sprache, die man wählen sollte. Warum gerade Python? In der Wissenschaftswelt ist Python eine sehr beliebte Sprache, wodurch viele Optimierungen von Algorithmen und viele Frameworks für Machine-Learning-Anwendungen dort zuerst verfügbar waren.
Ein simples Framework für den Einstieg in Python ist Scikit-learn. Damit ist mit wenigen Codezeilen vieles möglich. So lässt sich nach einem kurzen Blick auf die Seite der Scikit-learn-Beispielprojekte bereits ein einfacher Klassifikator implementieren, den man mit den besorgten Daten trainieren kann. Scikit-learn bietet sich für Anfänger an, weil es viele Metriken zur Bestimmung der Güte des Modells schon mitbringt und es auch sehr gute Optionen zur Visualisierung bietet.
Um mit den Daten überhaupt arbeiten zu können, müssen erstmal Features (Merkmale in den Daten) extrahiert werden. Wer mit Texten arbeitet, der will beispielsweise schauen, ob ein Wort vorkommt oder nicht. Man könnte außerdem versuchen, die Wörter auf den Wortstamm zu reduzieren und schauen, ob dieser Wortstamm im Text vorkommt. Auch das Vorkommen von bestimmten Sonderzeichen lässt sich als Merkmal erfassen – je nachdem, welches Problem gelöst werden will und wie die Daten aussehen. Arbeitet man mit Bildern, dann ließe sich eine Kantendetektion (Canny-Algorithmus oder Sobel-Operator) nutzen, um zu erkennen, was auf dem Bild gezeigt wird.
Für das Extrahieren dieser Merkmale können Einsteiger ebenfalls Frameworks verwenden. Sie helfen dabei, die Merkmale aus den Daten herauszubekommen. Die Merkmale werden dann zu Vektoren, die man in den Algorithmus stecken kann. Der Vorgang nennt sich Feature Extraction. Bei der Extraktion von Merkmalen aus dem Text helfen die Frameworks NLTK und Spacy. Diese erledigen den Job des Merkmalextrahierens, indem sie beispielsweise schätzen, welche Wörter im Text Orte, Personen und bestimmte Entitäten sind oder den Typ des jeweiligen Wortes.
Auch für die Extraktion von Merkmalen aus Bildern gibt es Frameworks. Dafür eignen sich Scikit-image und OpenCV. Damit kann man aus den Bildern Kantenstrukturen und Histogramme erstellen lassen, die sich als sehr gut als Merkmale anbieten. Diese Frameworks sind für Einsteiger zu empfehlen, da sie meist gut dokumentiert sind und viele Beispiele für die Benutzung enthalten sind. Wer außerhalb von Python unterwegs ist, kann sich auch das Weka Framework für Java anschauen oder Mlpack für C.
Geht es noch tiefer?
Nachdem nun einfache Probleme gelöst sind, können Interessierte sich komplizierteren Anwendungen widmen. Neben den sogenannten „Shallow-Neural-Networks“ (simple künstliche neuronale Netze mit einfachen Aktivierungsfunktionen) gibt es noch komplexere neuronale Netze. Deep Learning heißt die Disziplin, in der diese Netze mehrere Schichten haben und es verschiedene Typen von Schichten gibt. Diese Netze haben gezeigt, dass sie für einen komplexen Input (ein Bild oder ein Text) eine viel höhere Genauigkeit erzielen, als herkömmliche Algorithmen. Das funktioniert unter anderem so gut, da das Feature Engineering hier durch Autoencoder übernommen wird, die sehr viele Informationen aus dem Eingangsmedium extrahieren.
Die Open-Source-Datenbank Tensorflow bietet einen guten Einstieg zum Experimentieren mit Deep Learning. Das integrierte Tensorboard ermöglicht die grafische Darstellung der Daten. (Screenshot: Tensorboard)
Das klingt spannend? Ist es auch. Allerdings bringt das Training von Modellen mittels Deep Learning auch einige Probleme mit sich. Weil durch die Komplexität viele Parameter mehr als bei herkömmlichen Verfahren optimiert werden müssen, sind deutlich mehr Daten nötig. Man muss diese also im Vorfeld beschaffen. Außerdem müssen Entwickler viel mehr Zeit in die Architektur des Netzes stecken. Deep-Learning-Netze verfügen über eine höhere Anzahl von Schichten sowie über eine Vielzahl von Schichttypen. Die Optimierung bietet bei diesem Ansatz natürlich viel mehr Raum für Verbesserungen und Änderungen, ist dadurch aber auch komplexer und schwieriger in der Handhabung.
Wer trotzdem mit Deep Learning experimentieren will, sollte einen Blick auf Tensorflow und Keras werfen. Mit diesen beiden Bibliotheken lassen sich Deep-Learning-Anwendung bauen. Aber Vorsicht, zuerst sollten die Machine-Learning-Basics klar sein, bevor man mit diesen beiden Open-Source-Bibliotheken arbeitet. Damit ist sichergestellt, dass man eine grobe Vorstellung davon hat, was sich hinter den wenigen Codezeilen versteckt, die für eine funktionsfähigen Anwendung nötig sind.
Fazit
Dieser Artikel hat einen kurzen Einblick in die Welt des Machine Learnings gewährt. Was der Artikel aber nicht gezeigt hat, ist die Schwierigkeit, die Ergebnisse eines Modells gut zu interpretieren. Das sollte man sehr gewissenhaft tun, da man sich nach dem Training des Modells darauf verlassen muss, dass die Trainings- und Testdaten ausreichend waren, damit die Anwendung auch nach einem Deployment in einer produktiven Umgebung noch funktioniert.
Was ist dafür nötig? Eine gute Dokumentation ist wichtig, damit jeder Entwickler, der aktuell und zukünftig an dem Machine-Learning-Projekt arbeitet, eine gute Vorstellung vom entstandenen Modell hat. Außerdem sollte ein Review-Prozess rund um die Entstehung des Machine-Learning-Modells etabliert werden. Häufig schleicht sich unbemerkt eine Verzerrung (engl.: bias) in die Daten oder den Prozess ein, das Training wird also sehr einseitig und entwickelt ungewollte Tendenzen. Ein Review-Prozess mit einem Entwickler oder externem Beauftragten könnte diesen Fehlern und negativen Effekten vorbeugen.
Genauso wichtig ist es allerdings auch, die Ergebnisse und den Prozess interpretierbar und verständlich zu machen, um mit den optimierten Algorithmen keine negativen Effekte für andere Menschen oder Unternehmen zu erzielen.
