
JavaScript-Engines: Die Turbolader für den Browser

(Shutterstock / Art Alex)
Der Grundauftrag aller Javascript-Engines liegt in der Konvertierung von Javascript-Code in schnellen, optimierten Code, den Browser und Webanwendungen dann interpretieren können. Dabei setzt jeder Browser auf eine eigene, spezifische Engine, etwa V8 in Google Chrome, Chakra in Microsoft Edge oder Spidermonkey in Mozilla Firefox.
Die Javascript-Engine-Pipeline
Für sie alle gilt: Ihr Einsatz beginnt mit dem Javascript-Quellcode, den der Entwickler geschrieben hat. Die Javascript-Engine analysiert ihn und wandelt ihn in einen Abstract Syntax Tree (AST) um – eine Baumdarstellung des Quellcodes, welcher anschließend in Bytecode umgewandelt wird. Dieser Bytecode wird dann vom Bytecode-Interpreter ausgeführt.
Um eine bessere Ausführungsgeschwindigkeit zu erreichen, kann dieser Bytecode zusammen mit gesammelten Profiling-Daten an einen optimierenden Compiler geschickt werden. Der optimierende Compiler trifft aufgrund dieser Profiling-Daten bestimmte Annahmen und erzeugt dann hochoptimierten Maschinencode. Wenn sich eine der Annahmen irgendwann als falsch herausstellt, wird der Code deoptimiert und die Ausführung kehrt zum Interpreter zurück, der dann neue Profiling-Daten sammelt, um den Code später erneut zu optimieren.
Sehen wir uns nun die Teile dieser Pipeline an, die tatsächlich für die Ausführung von Javascript-Code zuständig sind. Das heißt: Wo genau wird Code interpretiert und optimiert? Wir konzentrieren uns dabei auf einige der Unterschiede zwischen den populärsten Javascript-Engines. Üblicherweise besteht die Pipeline immer aus einem Interpreter und zumindest einem optimierenden Compiler. Der Interpreter erzeugt sehr schnell Bytecode, der optimierende Compiler benötigt etwas länger, erzeugt aber dafür hochoptimierten Maschinencode.
Dieser generische Ansatz entspricht ziemlich genau dem Ansatz von V8, der Javascript-Engine in Chrome und Node.js. Der Interpreter in V8 heißt Ignition, der optimierende Compiler heißt Turbofan. Eine weitere populäre Javascript-Engine ist Spidermonkey, schon in den 1990er Jahren von Brendan Eich entwickelt und damit die erste Javascript-Engine überhaupt. Spidermonkey kommt in Mozilla Firefox zum Einsatz. Die Pipeline sieht anders aus als bei V8: Hier gibt es nicht einen, sondern zwei optimierende Compiler. Auf den Interpreter folgt der Baseline-Compiler, der einfachen Maschinencode erzeugt. In Kombination mit Profiling-Daten, die während der Ausführung des Codes gesammelt werden, kann der Ionmonkey-Compiler dann hochoptimierten Code erstellen. Sollten sich dabei getroffene Annahmen als falsch herausstellen, kehrt die Ausführung zum Baseline-Code zurück. Chakra, die Javascript-Engine in Microsoft Edge und Node-Chakracore, hat eine sehr ähnliche Architektur, mit einem Interpreter und ebenfalls zwei Compilern, SimpleJIT und FullJIT. Dabei steht JIT für Just-in-Time-Compiler. Javascriptcore (oder kurz JSC), Apples Javascript-Engine, wie sie in Safari und React Native verwendet wird, bringt es mit drei verschiedenen optimierenden Compilern auf die Spitze. LLInt, der Low-Level-Interpreter, führt zum Baseline-Compiler, der zum DFG-Compiler weiterführt. Code, der sehr häufig verwendet wird, kann dann zuletzt noch durch den FTL-Compiler optimiert werden.
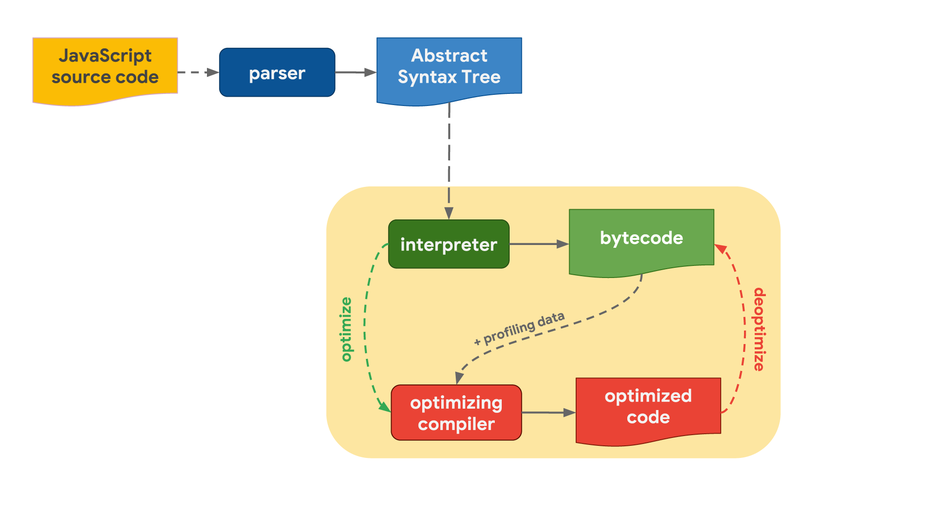
Compiler helfen Javascript-Engines dabei, eine bessere Ausführungsgeschwindigkeit zu erreichen: Sie erzeugen hochoptimierten Maschinencode. Verschiedene Engines setzen auf einen, zwei oder noch mehr Compiler. (Grafik: Mathias Bynens, Benedikt Meurer)
Warum haben manche Engines mehr Compiler als andere? Ein Interpreter kann Bytecode schnell erzeugen, aber Bytecode ist generell nicht sehr effizient. Ein optimierender Compiler benötigt dagegen länger, erzeugt aber letztendlich viel effizienteren Maschinencode. Es gilt also, den richtigen Kompromiss zwischen schnellem Erzeugen von Code (Interpreter) oder schnellerer Ausführung des erzeugten Codes (Optimierender Compiler) zu finden. Einige Engines entscheiden sich dafür, mehrere optimierende Compiler mit unterschiedlichen Zeit- und Effizienzeigenschaften hinzuzufügen, was eine feinere Kontrolle über diese Kompromisse auf Kosten zusätzlicher Komplexität und Compile-Zeiten ermöglicht.
Die übergeordnete Architektur bleibt aber, trotz aller Unterschiede im Detail, dieselbe: Alle Javascript-Engines weisen einen Parser und eine Interpreter-Compiler-Pipeline auf. Darüber hinaus gibt es weitere Gemeinsamkeiten zwischen den einzelnen Engines. So implementieren beispielsweise die vier oben genannten Javascript-Engines das Javascript-Objekt-Modell auf eine sehr ähnliche Weise und verwenden dieselben Tricks, um den Zugriff auf Properties von Javascript-Objekten zu beschleunigen.
Das Javascript-Objekt-Modell
Die Javascript-Spezifikation definiert Objekte im Wesentlichen als Dictionaries, welche Property Namen (Strings) auf Property Attributen abbilden. Neben dem eigentlichen selbst [[Value]] definiert die Spezifikation die folgenden Property-Attribute:
[[Writable]] bestimmt, ob die Property neu zugewiesen werden kann
[[Enumerable]] bestimmt, ob die Property in for-in-Schleifen aufgeführt wird
[[Configurable]] bestimmt, ob die Property gelöscht werden kann
Arrays wiederum können als Spezialfall von Objekten gedacht werden. Ein wichtiger Unterschied besteht darin, dass Arrays eine spezielle Behandlung für Array-Indizes haben: Array-Index ist dabei ein spezieller Begriff in der Javascript-Spezifikation. Arrays sind auf 2³²-1 Elemente in Javascript beschränkt. Ein Array-Index ist irgendein gültiger Index innerhalb dieses Bereichs, das heißt ein Integer von 0 bis 2³²-2.
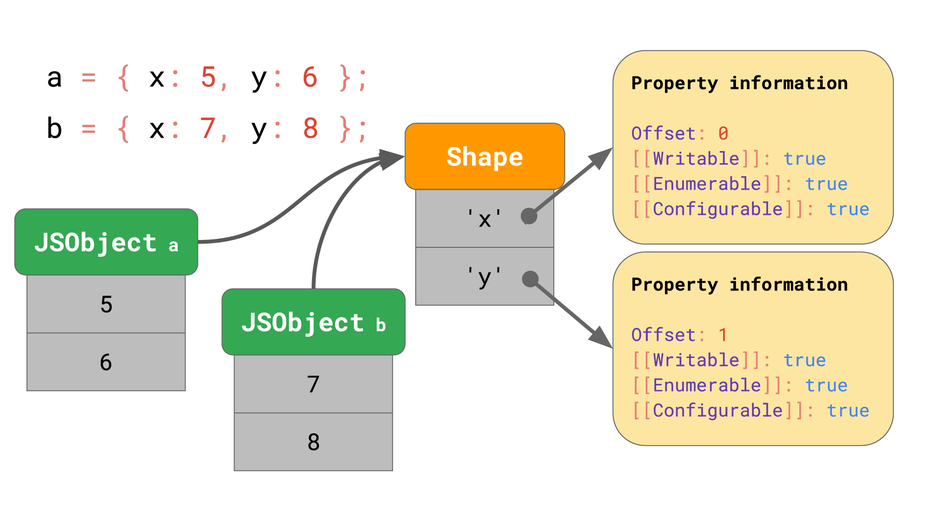
Um redundante Arbeit zu vermeiden, speichern Engines die Form von Objekten separat. Jedes Objekt mit derselben Form zeigt genau auf diese eindeutige Shape-Instanz. (Grafik: Mathias Bynens, Benedikt Meurer)
Ein weiterer Unterschied besteht darin, dass Arrays auch eine spezielle length-Property haben, die automatisch aktualisiert wird:
const array = ['a', 'b']; array.length; // a 2 array[2] = 'c'; array.length; // a 3
Shapes
Betrachtet man herkömmliche Javascript-Programme, so fällt auf, dass der Zugriff auf Properties bei weitem die häufigste Operation ist. Für Javascript-Engines ist es daher entscheidend, dass der Zugriff auf Properties schnell erfolgt, um eine gute Performance sicherzustellen. Hierbei helfen vor allem Formen – beziehungsweise Shapes – von Objekten sowie Inline-Caches, die das Nachschlagen von Property-Informationen im besten Falle obsolet machen. Im Einzelnen funktioniert dieses Prinzip wie folgt:
const object = {
foo: 'bar',
baz: 'qux',
};
// Hier wird nun auf die Eigenschaft 'foo' in 'object'
// zugegriffen:
doSomething(object.foo);
// ^^^^^^^^^^
In Javascript-Programmen sind häufig mehrere Objekte mit denselben Property-Namen vorhanden. Solche Objekte haben die gleiche Form (Englisch: Shape).
const object1 = { x: 1, y: 2 };
const object2 = { x: 3, y: 4 };
object1 und object2 haben hier dieselbe Form. Auch Zugriffe auf die gleiche Property für Objekte mit gleicher Form finden sehr häufig statt:
function logX(object) {
console.log(object.x);
// ^^^^^^^^
}
const object1 = { x: 1, y: 2 };
const object2 = { x: 3, y: 4 };
logX(object1);
logX(object2);
Javascript-Engines können den Zugriff auf Properties also basierend auf der Form eines Objekts optimieren. Das funktioniert folgendermaßen:
Nehmen wir an, wir haben ein Objekt mit den Properties x und y und verwenden dafür die Dictionary-Datenstruktur, die wir zuvor gesehen haben. Sie enthält die Property-Namen als Strings, und diese verweisen auf ihre jeweiligen Property-Attribute.
Greifen wir nun auf eine Property zu, zum Beispiel object.y, so muss die Javascript-Engine im JSObject nach dem Namen y suchen und dann die entsprechenden Attribute laden, um schlussendlich den [[Value]] zurückzugeben.
Aber wie sind diese Attribute im Speicher abgelegt? Sollten sie als Teil der einzelnen Objektinstanzen gespeichert werden? Gehen wir davon aus, dass wir zukünftig noch weiteren Objekten mit der gleichen Form begegnen, so wäre es Verschwendung, das vollständige Dictionary mit den Property-Namen und Attributen auf jedem JSObject einzeln zu speichern – schließlich werden die Namen für alle Objekte mit derselben Form wiederholt. Um Speicherverbrauch und redundante Arbeit zu vermeiden, speichern Engines die Shape von Objekten also separat. Diese Shape enthält alle Property-Namen und die Attribute mit Ausnahme ihrer [[Value]]. Stattdessen speichert die Shape den Offset der Werte innerhalb des Objektes, sodass die Javascript-Engine weiß, wo die Werte zu finden sind. Jedes Objekt mit derselben Form zeigt genau auf diese eindeutige Shape-Instanz. Die Objekt-Instanzen selbst enthalten jetzt nur noch die eigentlichen, für jedes Objekt einzigartigen, Werte. Sobald es mehrere Objekte gibt, wird der Vorteil deutlich: Egal, wie viele Objekte es gibt, solange sie die gleiche Form haben, müssen wir die Informationen über Shape und Properties nur einmal speichern!
Alle Javascript-Engines verwenden Shapes als Optimierung, benutzen allerdings unterschiedliche Bezeichnungen: Im akademischen Bereich ist der Begriff „Hidden Classes“ verbreitet, was allerdings in der Abgrenzung zur Javascript-class für Verwirrung sorgen kann. V8 nennt sie Maps, was sich mit dem ebenfalls schon vorhandenen Begriff der Javascript-Map überschneidet. Chakra nennt sie Types – und kommt damit in Abgrenzungsprobleme, was dynamische Typen und typeof angeht. Javascriptcore nennt sie Structures, Spidermonkey nennt sie Shapes. In diesem Artikel nutzen wir weiterhin den Begriff Shape.
Transition-Chains und Transition-Trees
Was passiert, wenn wir einem Objekt mit einer bestimmten Shape eine weitere Property hinzufügen? Wie findet die Javascript-Engine die neue Shape?
const object = {};
object.x = 5;
object.y = 6;
In solchen Fällen bilden die Shapes in der Javascript-Engine sogenannte Transition-Chains: Das Objekt beginnt ohne Properties, zeigt also zu Beginn auf die Empty Shape. Die nächste Zeile fügt diesem Objekt eine Property x mit einem Wert 5 hinzu, sodass die Javascript-Engine zu einer Shape übergeht, die die Property x enthält, und dem Objekt wird ein Wert 5 hinzugefügt (an Offset 0). Die nächste Zeile fügt eine Property y hinzu, sodass die Engine zu einer Shape übergeht, die sowohl x als auch y enthält, und fügt dem Objekt den Wert 6 hinzu (an Offset 1). Wir müssen nicht einmal die vollständige Tabelle der Properties für jede Shape speichern. Stattdessen enthält jede Shape nur Informationen über die neue Property, die sie einführt. Steht im Javascript-Code nun o.x, sucht die Javascript-Engine nach der Property x, indem sie die Transition-Chain rückwärts durchläuft, bis sie die Shape findet, die die Property x eingeführt hat.
Aber was passiert, wenn es keine Möglichkeit gibt, eine Transition-Chain zu bilden? Etwa, wenn es zwei leere Objekte gibt und jedem eine andere Property hinzugefügt wird?
const a = {};
a.x = 5;
const b = {};
b.y = 6;
In diesem Fall müssen wir verzweigen, und statt einer Transition-Chain entsteht ein sogenannter Transition-Tree:
Das Beispiel beginnt mit einem leeren Objekt a und fügt dann eine Property x hinzu. Anschließend ist a ein Objekt, das einen einzelnen Wert und zwei Shapes enthält: die Empty Shape und die Shape mit nur einer Property x. Das zweite Beispiel beginnt ebenfalls mit einem leeren Objekt b, fügt dann aber eine andere Property y hinzu. Schlussendlich haben wir jetzt zwei Transition-Chains und insgesamt drei Shapes.
Allerdings ist das Nachschlagen von Properties jetzt sogar noch langsamer als ohne Shapes, da wir linear durch die Transition-Chains laufen müssen, anstatt in einer Hash-Tabelle zu suchen. Aber wie helfen Shapes denn nun dabei, Javascript zu beschleunigen?
Inline-Caches (IC)
Die Hauptmotivation hinter Shapes ist das Konzept der Inline-Caches oder IC. Sie sind die wichtigste Zutat, um Javascript schnell zu machen! Javascript-Engines verwenden IC, um sich Informationen darüber zu merken, wo Properties von Objekten zu finden sind, um die Anzahl teurer Nachschlagevorgänge zu reduzieren.
Hier ist eine Funktion getX, die ein Objekt übernimmt und dessen Property x lädt:
function getX(o) {
return o.x;
}
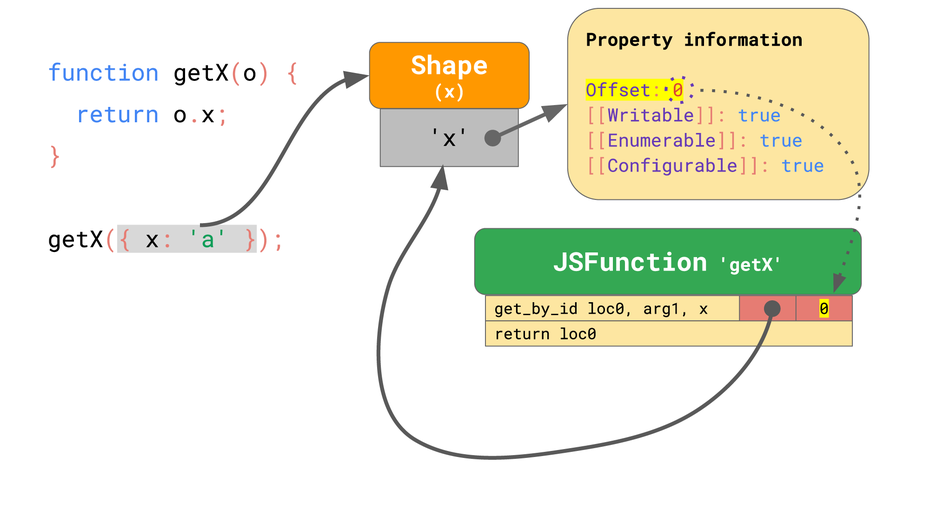
Mithilfe von Inline-Caches merken sich Javascript-Engines, wo die Properties einzelner Objekte zu finden sind. So können sie diese bei nachfolgenden Durchläufen direkt vom bekannten Offset laden und sparen sich das Nachschlagen. (Grafik: Mathias Bynens, Benedikt Meurer)
Wenn wir diese Funktion beispielsweise in Javascriptcore ausführen, erzeugt es den folgenden Bytecode:
get_by_id loc0, arg1, x return loc0
Der erste get_by_id-Befehl lädt die Property x vom ersten Argument (arg1) und speichert das Ergebnis in loc0. Der zweite Befehl beendet die Ausführung der Funktion mit dem Wert, den wir zuvor in loc0 gespeichert haben. JSC bettet außerdem einen Inline-Cache in den Befehl get_by_id ein, der aus zwei nicht initialisierten Slots besteht. Nehmen wir nun an, wir rufen getX mit einem Objekt {x: a} auf. Wie wir gelernt haben, hat dieses Objekt eine Shape mit der Property x und die Shape speichert den Offset und die Attribute für diese Property x. Wenn Sie die Funktion zum ersten Mal ausführen, sucht die Anweisung get_by_id die Property x und stellt fest, dass der Wert bei Offset 0 gespeichert ist.
Der IC im get_by_id-Befehl merkt sich die Shape und den Offset, an dem die Property gefunden wurde, sodass der IC für nachfolgende Durchläufe nur die Shape vergleichen muss. Wenn diese übereinstimmt, kann er den Wert einfach vom bereits bekannten Offset laden. Sieht die Javascript-Engine von nun an Objekte mit einer Shape, die ein IC zuvor aufgezeichnet hat, muss sie nicht mehr auf die Property-Informationen zugreifen und kann das kostspielige Nachschlagen vollständig vermeiden. Das ist wesentlich schneller, als jedes Mal nach der Property zu suchen.
Fazit
Um den Javascript-Quellcode von Entwicklern schnell im Browser ausführen zu können, konvertieren Javascript-Engines ihn mithilfe eines Interpreters und eines oder mehrerer Compiler in optimiertem, maschinenlesbarem Code. Shapes und IC helfen ihnen dabei, vor allem häufig auftretende Operationen weiter zu optimieren. Entwickler können sich diese Prinzipien zunutze machen, indem sie sicherstellen, dass Objekte immer auf die gleiche Weise initialisiert werden, damit sie immer die gleiche Shape bekommen. Außerdem sollten sie die Property-Eigenschaften von Array Elementen nicht zu sehr überfrachten, damit sie effizient gespeichert und ausgeführt werden können.
 Benedikt Meurer (@bmeurer) ist ein Javascript-Compiler-Engineer und liebt es, sich mit den verschiedensten Aspekten von Programmiersprachen auseinanderzusetzen. Er arbeitet für Google an der Javascript-Engine V8 und leitet derzeit die Performance-Initiative für Node.js.
Benedikt Meurer (@bmeurer) ist ein Javascript-Compiler-Engineer und liebt es, sich mit den verschiedensten Aspekten von Programmiersprachen auseinanderzusetzen. Er arbeitet für Google an der Javascript-Engine V8 und leitet derzeit die Performance-Initiative für Node.js.
 Mathias Bynens (@mathias) arbeitet für Google an der Javascript-Engine V8. Sein Fokus liegt auf der Verbesserung des ECMA-Script-Standards für alle Javascript-Dialekte durch das ECMA Technical Committee 39 (TC39).
Mathias Bynens (@mathias) arbeitet für Google an der Javascript-Engine V8. Sein Fokus liegt auf der Verbesserung des ECMA-Script-Standards für alle Javascript-Dialekte durch das ECMA Technical Committee 39 (TC39).

Endlich mal wieder ein Artikel, der es werden ist ihn zu lesen. Bitte mehr davon!