Schnittstellen-Booster: GraphQL als Alternative zu Rest

(Grafik: GraphQl)
Ob an Bord eines Flugzeuges oder unterwegs über Mobilfunknetze – wer mit einer langsamen Internetverbindung surfen will, braucht Geduld. Denn der Datenaustausch basiert typischerweise auf einer REST-Architektur. Die Ideen zu REST wurden vor 18 Jahren von Roy Fielding in seiner Dissertation beschrieben, also zu einer Zeit, als es noch keine Smartphones oder Internet im Flugzeug gab. Die Architektur kommt an ihre Grenzen, sobald auf komplexe Datenstrukturen zugegriffen werden soll. Ohne Zusatzaufwand für Optimierungen werden die Seiten träge, im schlimmsten Fall bricht der Leser der Seite ab. Deshalb lohnt sich ein genauerer Blick auf die Alternative GraphQL: eine Abfragesprache und ein zentraler HTTP-Endpoint zur Abfrage aus verschiedenen, dahinter liegenden Datenquellen.
Seit Facebook 2015 eine ausführliche Spezifikation und Referenzimplementierung von GraphQL als Open Source veröffentlicht hat, hat sich ein großes Ökosystem an Bibliotheken und Tools für alle aktuellen Programmiersprachen, Server und Clients entwickelt. Etliche große Unternehmen nutzen GraphQL, darunter Github, die New York Times, Xing oder Coursera. Das Berliner Startup Graphcool stellt mit Prisma.Cloud einen Cloud-Service zum schnellen Start einer GraphQL-Datenbank bereit. Auch Amazons neuer AppSync-Service setzt auf GraphQL.
Der Unterschied zu REST
Die Unterschiede zwischen GraphQL und REST zeigt das folgende Beispiel ganz gut: Eine Spotify-Suche per API nach einem Künstler und seinen Alben inklusive Titelliste. Bei REST müssen Entwickler folgende Endpoints von der Client-Seite (mehrmals) abfragen:
https://api.spotify.com/v1/search?type=artist
https://api.spotify.com/v1/artists/{artist-id}
https://api.spotify.com/v1/artists/{artist-id}/albums
https://api.spotify.com/v1/albums/{album-id}/tracks
Mit GraphQL können sie dagegen mit nur einer Abfrage an einen einzigen Endpunkt alle Informationen vom Server bekommen:
queryArtist(byName:“Xul Zolar“){
name
image
album {
name image
track {
name
}
}
}
Dabei müssen Entwickler im Client genau angeben, welche Attribute sie benötigen. Dadurch hat die Client-Seite aber auch die Kontrolle darüber, welche Daten die Anwendung sendet. Die Vorteile liegen auf der Hand:
Nur ein HTTP-Request: In mobilen Netzen ist jeder Verbindungsaufbau und jeder erneute Request durch eine hohe Latenz und lange Ping-Zeiten teuer. Denn mit jeder neuen, nachfolgenden (N+1) Abfrage dauert es insgesamt sehr viel länger, auch wenn die Anwendung nur geringe Datenmengen übermittelt.
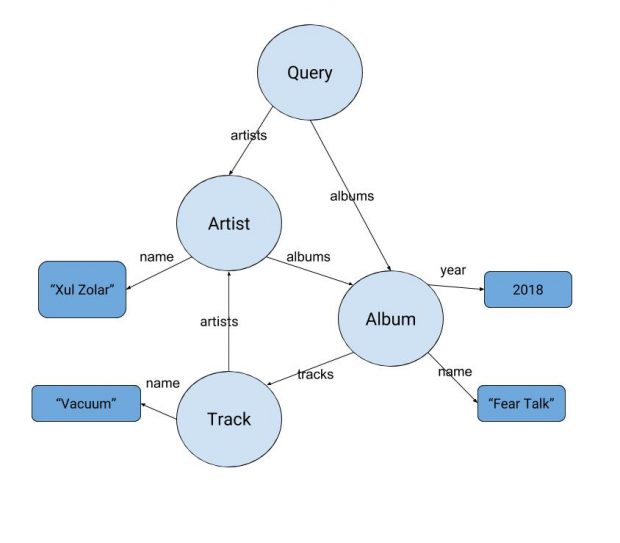
Im Gegensatz zu REST definiert GraphQL auch die Beziehungen zwischen den Entitäten. Dieses minimale Schema einer Spotify-Suche besteht aus einem Wurzelknoten vom Typ Query, der den direkten oder indirekten Zugriff auf alle weiteren Knoten erlaubt. (Grafik: Robert Howlowsky)
Konzentration auf die wichtigsten Daten bei der Übermittlung: Nur wenn Entwickler genau spezifizieren können, welche einzelnen Datenfelder notwendig sind, kann eine Anwendung das nötige Minimum übertragen. Im Gegensatz dazu übermittelt eine Anwendung bei REST immer alle Daten einer Ressource, das sogenannte „over-fetching“. Wenn beispielsweise unsere Spotify-Suche ein Künstlerbild anzeigen soll, würde REST auch alle anderen Attribute mitschicken, anstatt nur den Link zum Bild zu senden. Als Workaround könnten Entwickler einen weiteren REST-Endpunkt mit genau dieser Funktionalität anbieten, aber das bedeutet immer zusätzlichen Aufwand.
Eingebaute Validierung: Außerdem können Entwickler schnell prüfen, ob ein angefordertes Attribut überhaupt existiert: Der häufige Fehler, dass beispielsweise ein erwartetes Nachname-Feld leer bleibt, weil die Anwendung stattdessen “surname” hätte benutzen müssen, ist damit Vergangenheit.
Um zu prüfen, welche Attribute zur Verfügung stehen, besitzt GraphQL ein Schema, das aus einer Liste von Typ-Definitionen der Entitäten mit ihren Feldern besteht. Sie lässt sich in etwa mit einem Datenbankschema vergleichen. Während die meisten HTTP allgemein mit REST assoziieren – mit Ressourcen als Kernkonzept – ist GraphQL im Kontrast dazu ein konzeptuelles Modell eines Entitäten-Graphen. Im Gegensatz zu REST definiert GraphQL also auch die Beziehungen zwischen den Entitäten. Ein minimales Schema besteht nur aus einem Wurzelknoten (vom Typ Query), der direkt oder indirekt den Zugriff auf alle anderen Knoten im Graphen ermöglicht (s. Abbildung unten).
Die Schema-Definition: Variante 1
Ein sehr einfaches Beispiel zeigt, wie das funktioniert: In der folgenden, stark vereinfachten Beispielimplementierung hat der Query Type nur das Attribut hi mit dem Wert hello world. Es handelt sich dabei quasi um die Verbindung zum Datenknoten hello world, der über die Kante hi zu erreichen ist.
// Listing 1
// data/schema.js
import { GraphQLSchema, GraphQLString, GraphQLObjectType } from 'graphql';
const schema = new GraphQLSchema({
query: new GraphQLObjectType({
name: 'Query',
fields: {
hi: {
type: GraphQLString,
resolve: () => 'Hello world!'
}
}
})
});
export default schema;
Mit dem folgenden, einfachen Setup eines Express.js-Servers können Entwickler mit der express-graphql-Middleware einen GraphQL-Endpoint bereitstellen.
// Listing 2 // server.js import express from 'express'; import expressGraphQL from 'express-graphql'; import schema from './data/schema'; // von oben const app = express(); app.use('/graphql', expressGraphQL(req => ({ schema, graphiql: true }))); app.set('port', 4000); app.listen(port);
Entwickler starten nun den Server mit dem Befehl babel-node server und öffnen ein zweites Terminalfenster mit der folgenden Abfrage:
curl 'http://localhost:4000/graphql' \ -H 'content-type: application/json' \ -d '{"query":"{hi}"}'
Als Ergebnis bekommen sie das folgende JSON-Dokument:
{
"data": {
"hi": "Hello world!"
}
}
In data steht das Ergebnis der Abfrage. Im Fehlerfall würden die Fehlinformationen in einem optionalen error-Element stehen.
Da die In-Browser-IDE GraphiQL nach dem Start des Servers aktiviert ist (per graphiql:true), lässt sie sich im Browser über die Adresse http://localhost:4000/graphql?query={hi} oder für den Demoserver öffnen (s. Abbildung rechte Seite). Das Editor-Fenster am linken Rand zeigt automatisch die Abfrage und führt sie aus. Hier können Entwickler durch das Schema ein toolgestütztes Syntax-Highlighting und eine Auto-Vervollständigung nutzen. In GraphiQL können sie außerdem rechts neben dem Ergebnisfenster die Dokumentation des Schemas aufklappen.
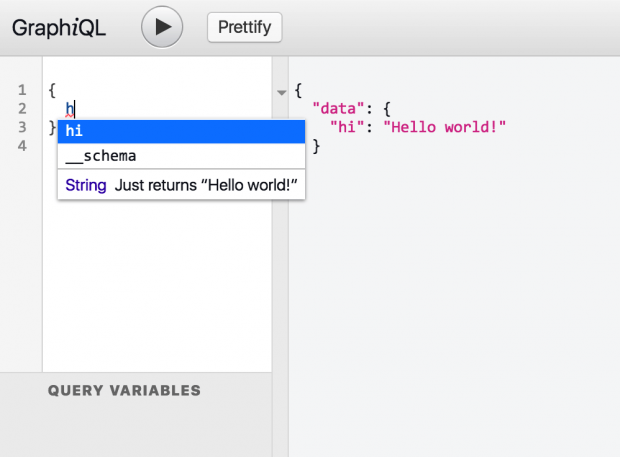
Das Editorfenster von GraphiQL zeigt links automatisch die Abfrage, rechts neben dem Ergebnisfenster lässt sich die Dokumentation anzeigen. (Screenshot: Robert Hostlowsky)
Darüber hinaus können sie zu ihrem Schema auch einige Beschreibungen hinzufügen, die ebenfalls in der GraphQL-Dokumentation („schema inspection“) rechts auftauchen. Zum Beispiel die Erweiterungen aus dem folgenden Listing:
// Listing 3
const schema = new GraphQLSchema({
query: new GraphQLObjectType({
name: 'Query',
fields: {
hi: {
description: 'Gibt einfach nur "Hello world!" zurück',
type: GraphQLString,
resolve: () => 'Hello world!'
}
}
})
});
Nach dem Neustart des Servers steht das neue Schema in GraphiQL zu Verfügung – eine API-Dokumentation ähnlich wie beispielsweise bei Swagger, nur dass bei GraphQL kein zusätzlicher Schritt notwendig ist, um sie zu erzeugen. GraphiQL fragt das Schema im Hintergrund über die gleiche Schnittstelle ab. Das Schema lässt sich auch per GraphQL selbst lesen. So stehen Entwicklern zum Beispiel alle Typdefinitionen zur Verfügung. Sie können das eingebaute Schema aber auch direkt abrufen, etwa im Terminal über die folgenden Zeilen:
curl 'http://localhost:4000/graphql' \ -H 'content-type: application/json' \ -d '{"query": "{__schema { types { name, fields { name, description, type {name} } }}}"}'
Das Resultat ist ein relativ langes, für Maschinen lesbares JSON-Dokument mit allen Informationen. Für eine einfachere und kompaktere Dokumentation können Entwickler auf Flowtype zurückgreifen – eine populäre Notation für Typ-Annotationen für Javascript. Damit ist es Zeit für die zweite Variante der Schema-Definition in GraphQL.
Schema-Definition: Variante 2
Für die Schema-Definition mit GraphQL SDL lassen sich Entwickler das bestehende Schema mit dem Modul printSchema in der GraphQL „Schema Definition Language“ ausgeben.
// data/printSchema.js
import { printSchema } from 'graphql';
import schema from './data/schema';
console.log(printSchema(schema));
Beim Start mit bash bin/printSchema erhalten sie die Ausgabe:
# Wurzelknoten, siehe "hi"
type Query {
# Gibt einfach nur "Hello world!" zurück'
hi: String
}
Umgekehrt lässt sich dieses Format als kompakte Alternative zur bisherigen Definition des Schemas verwenden. Dazu benutzen Entwickler einfach buildSchema aus dem Modul graphql:
// Listing 4
// data/schema.js
import { buildSchema } from 'graphql';
const schema = buildSchema(`
#
# „Wurzelknoten“
#
type Query {
# Gibt einfach nur "Hello world!" zurück'
hi: String
}
`);
export default schema;
Neben der Typdefinition muss natürlich auch die Logik implementiert werden, um bei Abfragen konkrete Werte zu erhalten. Im Server setzen Entwickler dazu die Definition des Wurzelknotens als Wert für rootValue, von dem aus alle anderen Knoten erreicht werden. Dazu müssen sie nur sogenannte resolver hinzufügen. Dazu gleich noch mehr. Der Rückgabewert der Funktion hi repräsentiert hier den Wert für das Feld hi von oben.
// Listing 5
// ... in server.js :
app.use('/graphql‘, expressGraphQL(req => ({
schema,
rootValue: {
hi: () => 'Hello world!'
},
graphiql: true
})));
Auch wenn GraphQL nur baumartige Strukturen zurückliefert, kann jede Abfrage auch Daten aus einem zyklischen Graphen auslesen. Ein Beispiel macht das deutlich: Die Suche bei Twitter nach allen Followern der Follower eines Twitter-Nutzers enthält typischerweise auch den Startknoten, wenn sich Twitter-Nutzer gegenseitig folgen. Mit solchen Abfragen wächst die Ergebnismenge natürlich schnell exponentiell an. Als Lösung gibt es in der Sangria-Scala-Bibliothek ein Modul, das die Abfragekomplexität anhand der Zahl der Ebenen abschätzt.
Resolver
- Über Resolver können GraphQL-Entwickler Daten aus einer beliebigen Datenquelle abrufen. Dabei gibt es verschiedene Typen:
- konstanter Wert/Objekt
- eine Funktion, etwa:
new Date().getFullYear() - eine Funktion, die ein Promise zurückgibt, das asynchron aufgelöst wird, beispielsweise: fetch(„from_url“)
- keine explizite Funktion/fehlend: Wenn kein Resolver definiert ist, leitet GraphQL den Wert automatisch aus einer Eigenschaft des Objektes mit demselben Namen ab. Entwickler können es beispielsweise dann verwenden, wenn sie mit dem ES6 Spread Operator die Werte aus der JSON-Antwort direkt übernehmen.
In den resolver-Methoden lassen sich Argumente verwenden, was für alle Abfragen nötig ist. In diesem Beispiel lässt sich so die Suche queryArtists(„byName“) parametrisieren, was in der SDL dann so definiert wird:
type Query {
queryArtists(byName: String = "Xul Zolar"): [Artist]
}
Promise-Objekte sind sehr interessant, weil mit ihnen viele asynchron laufende Datenabfragen möglich sind, ohne dass Anwender einzeln auf die Ergebnisse warten müssen. Dadurch kann man alle mächtigen Bibliotheken ohne großen Aufwand integrieren und nutzen, wie zum Beispiel Mongoose oder die Github-, Twitter- oder beliebige andere Client-Bibliotheken.
Übrigens: GraphQL erlaubt auch modifizierende Operationen (sogenannte „mutations“) und Benachrichtigungen des Clients per Subscribe-Mechanismus (sogenannte „subscriptions“). Die Abfragesprache ist hierbei ebenfalls unabhängig vom Protokoll: Programmierer können also neben Websockets zum Beispiel auch MQTT verwenden, was sich für Internet-of-Things-Anwendungen etabliert hat.
Weitere Details zum Umgang mit GraphQL, etwa zur Implementierung eines Resolvers, um die Abfrage der REST-API zu kapseln und damit einen GraphQL-API-Gateway aufzubauen, oder zur Implementierung der GraphQL-Schnittstelle für die Nutzung von Client aus, finden Entwickler in einer umfangreichen Blogreihe.
Bereit für den Produktiveinsatz
GraphQL spielt gegenüber REST dann seine Vorteile aus, wenn es eine exakte Definition gibt, welche Daten für eine Anwendung benötigt werden. Darüber hinaus ist es ideal für Abfragen durch Aggregation auf der Serverseite mit nur einem Request – also für mobile Verbindungen. Beim Einsatz von GraphQL sollte der Zugriff auf zusammenhängende Daten möglich sein, sodass sich die API-Entwicklung von der Client-Seite aus passend treiben lässt. Die Praxistauglichkeit von GraphQL zeigt nicht zuletzt die schnelle Adaption durch Entwickler und große Unternehmen.
Eine längere Fassung des Artikels ist im Softwerker-Magazin der codecentric AG erschienen.
