Software-Entwicklung: Tipps und Tools für die Versionskontrolle mit Git
In den letzten beiden Ausgaben des t3n-Magazins erschienen bereits zwei Artikel zum Thema Versionsverwaltung mit Git. Im ersten Teil wurde das Konzept und die Funktionsweise hinter Git beleuchtet [1], der zweite Artikel spielte eine Produktivumgebung mit dem Werkzeug zur Versionierung durch [2].
In diesem letzten Teil nun sind die Themen kleinteiliger. So spielen etwa die systeminterne Zwischenablage und der Rückgängig-Befehl eine Rolle. Doch auch ganze Konzepte, die etwa das Merging ersetzen wollen, werden vorgestellt. Es ist sozusagen ein Aufruf, über den Tellerrand der bisherigen Git-Gewohnheiten hinauszuschauen.
Die Zwischenablage Stash
Es gibt Situationen, in denen es entweder empfehlenswert oder sogar notwendig ist, ein „sauberes“ Working Directory zu haben; es sollten also keine lokalen Änderungen vorhanden sein. Das trifft für gewöhnlich dann zu, wenn der Branch gewechselt wird. Doch nicht immer ist dieser frei von gerade gewünschten Änderungen. Nach einigen Stunden Arbeit an einer neuen Funktion etwa, wenn plötzlich ein kritischer Bugreport eintrifft. Einerseits sollte man diesen umgehend bearbeiten, natürlich auf dem Stand des Produktivsystems. Andererseits können die gerade gemachten Änderungen schlecht commitet werden, sie sind ja noch nicht fertig.
Mit dem „Stash“ lässt sich genau dieses Dilemma lösen. Alle aktuellen Änderungen werden auf diese Art in eine Zwischenablage verfrachtet und lassen das Working Directory in jungfräulichem Zustand zurück. Sobald der Bugfix erledigt ist, lässt sich der alte Zustand wiederherstellen.
Teile von Dateien stagen
Große Commits, die viele verschiedene Themen enthalten, sind für andere Entwickler sowohl schwer zu überblicken als auch – im Fall von Problemen – schwer zu debuggen. Daher sollte in der Versionskontrolle auf granulare und thematisch abgegrenzte Commits geachtet werden.
Git hilft hierbei, etwa indem es erlaubt, nur Teile einer veränderten Datei in die Staging Area zu übernehmen. Wenn „git add“ mit dem Parameter „-p“ aufgerufen wird, lässt Git den Benutzer für jeden Teil der Datei entscheiden, ob er gestaget werden soll oder nicht. So kann sehr genau bestimmt werden, welche der Änderungen im nächsten Commit enthalten sein sollen und welche erst später committet werden.
Tracking Branches
Jede Config-Datei eines Git-Repositories (.git/config) beinhaltet Blöcke wie den Folgenden:

Git speichert in solchen Abschnitten Meta-Informationen über die Beziehung zwischen zwei Branches – der lokale Branch „master“ trackt den gleichnamigen Branch „master“ auf dem Remote „origin“. Diese Meta-Information nutzen einige andere Befehle in Git, etwa push, pull oder status.
![]()
In der Regel ist es nicht nötig, sich manuell um diese „Beziehungspflege“ zu kümmern; Git richtet das Tracking automatisch ein, wenn man einen lokalen Branch auf Basis eines Remote-Branches erstellt.
Rückgängig machen
Zuerst ein verhältnismäßig einfacher Fall: Der letzte Commit enthält Tippfehler in der Nachricht, diese sollen nun korrigiert werden. Git bietet beim commit-Befehl den „–amend“-Parameter an. Dieser überschreibt quasi den letzten Commit und es sieht so aus, als ob der Fehler nie passiert wäre. Per –amend lassen sich übrigens auch committete Dateien ändern, indem weitere hinzugefügt oder entfernt werden. Allerdings gilt die ungeschriebene, aber goldene Regel: Bereits veröffentlichte Commits sollten nicht mehr verändert werden.
Für diesen Fall steht mit dem „reset“-Befehl noch eine weitere Möglichkeit zur
Verfügung. Reset bedient sich der Tatsache, dass Branches nichts anderes
als Zeiger auf einen bestimmten Commit sind. Entsprechend setzt dieser Befehl den Zeiger auf einen älteren Commit. Tatsächlich gelöscht
wird hier nichts – in der History des Projekts sieht es dann aber
ganz so (wie ja auch gewünscht) aus.
Jetzt etwas komplizierter: Ein etwas älterer Commit soll „korrigiert“ werden. Dabei hilft der „revert“-Befehl. Hierbei wird allerdings kein Commit gelöscht, ganz im Gegenteil: Ein neuer Commit wird produziert, der die Effekte des entsprechenden Commits umkehrt.
Commits selektiv integrieren
Normalerweise werden Änderungen in einen Branch integriert, indem man ihn mit einem anderen mergt. In seltenen Fällen, in denen ein Merge nicht infrage kommt, stellt „cherry-pick“ eine interessante Alternative dar. Denn anstatt wie beim Merging einen kompletten Branch integrieren zu müssen, kann hier ein beliebiger einzelner oder auch mehrere Commits eingebaut werden. Um Probleme zu vermeiden, sollte dabei allerdings jeweils mit dem ältesten Commit begonnen werden.
GUI-Anwendungen wie etwa Tower [3] erleichtern solche Arbeiten übrigens, indem sie per Drag & Drop die Commits auswählen lassen.
Rebase anstatt Merge
Die gängigste Möglichkeit, einen Branch in einen anderen zu integrieren, ist das Merging. Bei einem gewöhnlichen Three-Way-Merge nimmt Git die beiden Endpunkte der zu mergenden Branches und den gemeinsamen Parent-Commit als Basis für die Integration. Endprodukt ist ein sogenannter Merge-Commit, der die beiden Branches wie ein Knoten wieder verbindet.

Die Alternative zum Merge ist der Rebase. Durch einen Rebase entsteht, anders als beim Merge, kein separater Integrations-Commit. Auch gibt es keine „Beule“ in der History des Projekts – es sieht vielmehr so aus, als ob die History linear verlaufen sei und alle Commits auf demselben Branch stattgefunden hätten.
Die Funktionsweise von Rebase erklärt sich idealerweise an einem konkreten Beispiel:
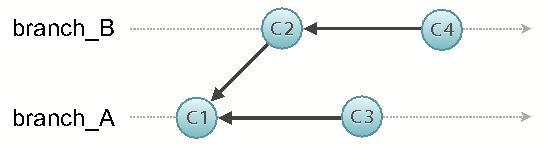
Branch_B ist der aktuelle HEAD-Branch. Bei einem Aufruf von „git rebase branch_A“ passiert aktuell zunächst folgendes: Alle neuen Commits (C2 und C4), die nach dem letzten gemeinsamen Commit (C1) entstanden sind, werden temporär entfernt. Nun werden die neuen Commits von branch_A auf branch_B angewendet, sodass im Anschluss beide Branches auf demselben Stand (dem von branch_A) sind.
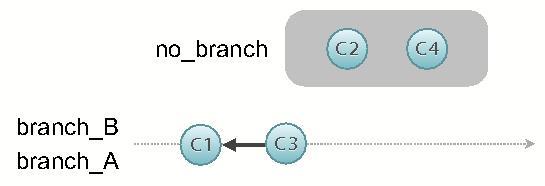
Gleich zu Beginn des Rebase-Befehls wurden die neuen Commits von branch_B temporär entfernt. Nun ist es an der Zeit, sie wieder anzuwenden – nacheinander und in ursprünglicher Reihenfolge.

Ergebnis ist, dass kein Merge-Commit entstanden und die History linear geblieben ist.
Geschichte schreiben
Eine Handvoll Befehle in Git verändern die History. Neben dem
Amending eines Commits gehört auch der Rebase zu diesen Befehlen. Es
gilt allerdings zu beachten, dass im Beispiel-Szenario die wieder
angewendeten
Commits nicht vollständig identisch sind (daher im Schaubild auch C2′
und C4′) – der Commit-Hash hat sich verändert, da mit dem Rebase die
History neu geschrieben wurde.
Bei Befehlen, die die History verändern, gilt daher immer die Regel:
Lokale Commits, die noch nicht veröffentlicht wurden, dürfen mit Rebase
oder Amend verändert werden. Wurden die Commits jedoch bereits
gepusht, sollten diese Tools nicht mehr angewendet werden.
Frühjahrsputz in Git
Im Leben eines Git-Repositories entsteht unter Umständen eine beachtliche Menge an Objekten – seien es nun Commits, Files oder File-Trees. Eine optimale Organisation dieser Objekte ist wichtig, damit Git seine gewohnt hohe Geschwindigkeit bei allen Operationen behält. Der Befehl „git gc“ (wobei „gc“ für „Garbage Collection“ steht) ist für genau diesen Zweck gedacht. Er wird zwar bei einigen Git-Kommandos automatisch im Hintegrund ausgeführt, dennoch ist ein gelegentliches „git gc“ (am Besten mit dem Parameter „–aggressive“, um das Optimum zu erreichen) kein schlechter Weg.
Helfer für die Kommandozeile
Wer viel auf der Kommandozeile arbeitet, kann sich seinen Alltag mit einigen Plugins etwas erleichtern. Dinge wie eine Tab-Autovervollständigung für die eigenen Branches oder die Anzeige des aktuell ausgecheckten Branches direkt im Prompt sind angenehme kleine Helferlein. Die entsprechenden Erweiterungen für Bash [4] und zsh [5] sind kostenfrei verfügbar.
Desktop-Clients

Eine Alternative zur Kommandozeile sind entsprechende Desktop-Clients. Viele Dinge lassen sich über ein grafisches User Interface einfacher und komfortabler erledigen. Ganz zu schweigen davon, dass man nicht jedes Kommando und jeden Parameter ständig parat haben muss. Für Windows-Nutzer ist „Tortoise Git“ [6] interessant, auf Mac OS ist „Tower“ [7] einen Blick wert.
Code-Hosting
Immer mehr Unternehmen und Freelancer entscheiden sich dafür, ihre Code-Repositories nicht mehr inhouse zu hosten. Die Bereitstellung und Pflege teurer Server-Infrastrukturen ist verständlicherweise nicht jedermanns Sache. Spezielles Know-how ist notwendig, Ressourcen werden gebunden und ein hohes Maß an Verfügbarkeit und Sicherheit muss garantiert werden.
Mittlerweile bietet eine ganze Reihe an Unternehmen an, das Code-Hosting von Git-Repositories nach dem SaaS-Prinzip zu übernehmen. Der mit Abstand größte Anbieter ist aktuell GitHub [8], gefolgt von Beanstalk [9] und Codebase [10]. Falls das externe Hosting des Codes eine Option ist, lohnt sich ein Blick auf diese Anbieter in jedem Fall.

Tobias Günther ist Geschäftsführer und Frontend-Entwickler beim Startup fournova GmbH. Mit seinem Team entwickelt er den Git-Client „Tower“ für Mac OS X (http://www.git-tower.com).
