
Neuronale Netze entwickeln: Erste Schritte mit TensorFlow

(Abbildung: Shutterstock / Tatiana Shepeleva)
Es müssen nicht immer gleich selbstfahrende Autos und neue Krebstherapien sein: Machine Learning zeigt sein Potenzial bereits bei vergleichsweise überschaubaren Alltagsherausforderungen, etwa bei Übersetzungen, Routenoptimierung oder automatisierten Vorschlägen basierend auf Nutzerinteressen.
Das Ende 2015 erstmals veröffentlichte TensorFlow zählt heute zu den beliebtesten und am meisten genutzten Machine-Learning- beziehungsweise Deep-Learning-Frameworks. Ursprünglich von der Alphabet-Tochter Deepmind entwickelt, ist die Software seit Ende 2015 Open Source und wird aktiv von knapp 2.000 Kontributoren weiterentwickelt. Am Beispiel einer Bildklassifizierung des CIFAR-10-Datensatzes erklären wir grundlegende Begriffe bei der Arbeit mit neuronalen Netzen und zeigen die Verwendung der kommenden TensorFlow-2.0-API. Mit wenigen Schritten bringen wir dabei einem Netz bei, Bilder vorhandenen Kategorien zuzuordnen.
TensorFlow 2.0 bietet einen leichten Einstieg durch aufgeräumte API, Eager Execution und Fokussierung auf die Keras-API. Zum Zeitpunkt der Erstellung dieses Artikels ist es in der frühen Version 2.0.0-alpha0 verfügbar. In dieser Fassung kann es bei der Nutzung der API noch zu Fehlern sowie Änderungen der Schnittstellen kommen.
Vorbereitung
Zur Nutzung von TensorFlow und der Codebeispiele aus diesem Artikel wird Python in Version 3.5, 3.6 oder 3.7 benötigt. Sobald Python erfolgreich installiert wurde, kann TensorFlow 2.0 mithilfe von Pip installiert werden. Hierzu muss man lediglich eine Konsole wie Terminal (Mac), Powershell (Windows) oder Bash (Linux) öffnen und folgenden Befehl ausführen:
pip install --upgrade tensorflow==2.0.0alpha0Mit dem gezeigten Befehl wird die CPU-Variante von TensorFlow installiert. Das bedeutet, alle Operationen werden lediglich mithilfe der CPU berechnet. Für das Training des simpel gehalten gezeigten Beispiels ist das ausreichend. Will man allerdings größere neuronale Netze trainieren, empfiehlt sich eine Installation der GPU-Variante. Das Training auf der GPU verbessert in der Regel die Ausführungszeit drastisch. Eine detaillierte Anleitung zur Installation der GPU-Variante von TensorFlow findet sich auf der Projektwebsite. Ausgerüstet mit unseren Werkzeugen, können wir jetzt an die Inhalte des Trainings gehen.
Das „Hello World“ für Machine LearningIn der Bildklassifizierung werden Bilder verschiedenen Kategorien zugeordnet. Die Kategorien können einer festgelegten Definition entsprechen (Auto, Frosch, Schiff …) oder auch dynamisch, basierend auf der Ähnlichkeit der Bilder, ermittelt werden. Wir betrachten in diesem Artikel die Zuteilung in festgelegte Kategorien.
Der Datensatz CIFAR-10 ist einer der Standarddatensätze im Bereich der Bildklassifizierung und ideal für unseren Einstieg. Man kann ihn mit einem „Hello World“ für Machine Learning vergleichen. TensorFlow bietet für den Datensatz bereits vorgefertigte Methoden für den Download und das Extrahieren der Daten.

CIFAR-10 besteht aus 60.000 Farbbildern mit einer Größe von 32 x 32 Pixeln und ist einer der Standarddatensätze im Bereich der Bildklassifizierung. (Screenshot: cs.toronto.edu)
CIFAR-10 besteht aus 60.000 Farbbildern mit einer Größe von 32 x 32 Pixeln. Die Herausforderung besteht darin, jedem dieser Bilder aus zehn möglichen Klassen die korrekte Klasse zuzuordnen.
In Python kann der Datensatz mithilfe der folgenden Befehle geladen werden:
import tensorflow as tf
cifar10 = tf.keras.datasets.cifar10
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
Die Variablen x_train und x_test enthalten die Bilder des Datensatzes als Numpy-Arrays, die Variablen y_train und y_test die korrekten Klassen, also die Labels, für die entsprechenden Bilder. Die Bilder in den Numpy-Arrays haben drei Dimensionen: Höhe, Breite und die Farbkanäle (RGB). Die Variable x_train enthält 50.000 Bilder, somit ergeben sich für die Größen der Dimensionen die Werte [50000, 32, 32, 3]. Die restlichen 10.000 Bilder befinden sich in x_test.
Wozu die Aufteilung eines Datensatzes in Trainingsbilder und Testbilder? Sie erlaubt es, eine Evaluierung des Trainingsfortschritts vorzunehmen. Würde man für die Evaluierung die gleichen Bilder nutzen, mit denen auch trainiert wurde, könnte man nicht unterscheiden, ob die Daten lediglich „auswendiggelernt“ wurden, oder ob –, wie gewünscht – eine Abstraktion der Merkmale einer Klasse stattgefunden hat. Beispielsweise, dass ein Auto vier Reifen und ein Motorrad zwei Reifen hat. Ohne die Fähigkeit einer Abstraktion der Merkmale kann das Trainingsergebnis nicht auf neue Bilder angewendet werden, sondern würde die erreichte Trefferquote nur beim bereits bekannten Bildfundus zeigen.
Die letzte Zeile des verwendeten Codes normalisiert die Pixelwerte der Bilder auf den Wertebereich [0, 1]. Die Rohdaten stellen die Farbwerte pro Kanal als ganze Zahlen zwischen 0 und 255 dar. Die Normalisierung erleichtert es dem neuronalen Netz, die benötigten Parameter zu erlernen, indem alle Werte in einem ähnlichen Wertebereich liegen.
Convolutional Neuronal Networks
In der Bildverarbeitung mit neuronalen Netzen haben sich Convolutional Neuronal Networks (CNNs) durchgesetzt. Diese werden oft in den ersten Schichten eines neuronalen Netzes verwendet, um Merkmale wie Kanten, Kreise oder andere Strukturen erfassen zu können. Der wichtigste Unterschied zu „klassischen“ neuronalen Netzen ist, dass sie einen Fokus schaffen: Sie betrachten räumlich benachbarte Regionen eines Bildes im Zusammenhang. Wie wir Menschen erkennen neuronale Netze Muster besser, wenn wir diese im Ganzen betrachten können und nicht zwischen verschiedenen Orten hin- und herspringen müssen. „Klassische“ neuronale Netze betrachten Daten dagegen immer als Vektor, der räumliche Zusammenhang geht daher verloren.
Es wird Zeit, unser Netz aufzuspannen. In TensorFlow kann mithilfe der Keras-API ein mehrschichtiges neuronales Netz definiert werden. In unserem Beispiel wird damit ein sequenzielles neuronales Netz aufgebaut. Die Ausgabe einer jeden Schicht dient dabei als Eingabe der nächsten Schicht. Die Netztopologie kann somit einfach von oben nach unten gelesen werden.
Um das Beispiel überschaubar zu halten, wurde ein sehr einfaches neuronales Netz gewählt. Es erreicht im Training zwar nicht die optimale Lösung, illustriert allerdings die Benutzung der TensorFlow-API:
1. model = tf.keras.models.Sequential([
2. tf.keras.layers.Conv2D(24, 3, activation='relu',
3. padding='same', input_shape=(32, 32, 3)),
4. tf.keras.layers.Flatten(),
5. tf.keras.layers.Dense(128, activation='relu'),
6. tf.keras.layers.Dense(10, activation='softmax')
7. ])
8. model.summary()
In diesem neuronalen Netz, auch Modell genannt, wird in der ersten Schicht die Dimensionierung der Eingaben mit dem Parameter input_shape festgelegt (Zeilen zwei und drei). Der CIFAR-10 Datensatz hat, wie zuvor erläutert, Bilder mit der Größe von 32 x 32 Pixeln und drei Farbkanäle. Als erste Schicht wird eine Convolution angewandt, welche auf dem Eingabebild eine Faltung mit 24 Filtern durchführt. Dadurch ergibt sich als Resultat der Zeile zwei eine Ausgabe der Dimensionierung 32 x 32 x 24.
Aus den 24.576 (32 x 32 x 24) Werten aus der Convolution wollen wir am Ende zehn Werte errechnen, welche unsere Klassen repräsentieren. Für die Transformation dieser Werte können „klassische“ neuronale Netze (Dense oder Fully-Connected genannt) verwendet werden. Zeile vier formt die dreidimensionale Ausgabe der Convolution in einen eindimensionalen Vektor um. Mit den Zeilen fünf und sechs werden aus den 24.576 Werten zunächst 128 und anschließend die gewünschten zehn Werte berechnet.
Der Aufbau des gesamten neuronalen Netzes ist damit definiert. Mit Zeile acht können Details zum neuronalen Netz ausgegeben werden. Die Ausgabe enthält die gerade konfigurierten Werte sowie die Anzahl der lernbaren Parameter. Die Anzahl der Parameter der einzelnen Schichten kann einen Eindruck ihrer Berechnungskomplexität vermitteln.
Durch die Definition des neuronalen Netzes ist es nun möglich, den Trainingsprozess zu konfigurieren und das Training zu starten. Der Code hierzu sieht wie folgt aus:
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
cp_callback = tf.keras.callbacks.ModelCheckpoint
('checkpoint.hdf5')
model.fit(x_train, y_train, epochs=15,
validation_data=(x_test, y_test),
callbacks=[cp_callback])Für die Konfiguration des Trainingsprozesses werden ein Optimierer und die zu verwendende Loss-Funktion benötigt. Der Optimierer legt fest, wie die Loss-Funktion beim Training optimiert wird. Ein guter Kandidat für einen Optimierer ist oft „Adam“. Adam verändert die Lernrate des Modells über den Trainingsverlauf automatisch. Außerdem kann er die Lernrate für jede Schicht einzeln anpassen und ermöglicht so meist einen besseren Trainingserfolg. Die Lernrate gibt an, wie schnell sich das neuronale Netz an neue Eingaben anpasst.
Die Loss- oder auch Kostenfunktion beschreibt, wie eine vorhergesagte Klassifizierung eines Bildes während des Trainings mit der eigentlichen Klassifizierung, dem Label, verglichen werden kann. Sie beschreibt damit den vom Netz gemachten Fehler. Der Optimierer versucht, diesen Fehler beim Training zu minimieren. Für die Klassifizierung wird sehr häufig die Kreuzentropie verwendet, ein Maß für die Qualität eines Modells in der Wahrscheinlichkeitsrechnung.
Viele Durchläufe für hohe Genauigkeit
Als Metrik, wie gut das trainierte Modell ist, soll die Genauigkeit der Erkennung ausgegeben werden. Ist der Trainingsprozess konfiguriert, kann das Training mit Fit gestartet werden. Wir übergeben die Trainings- sowie die Testdaten jeweils mit Bildern und korrekten Klassen und legen fest, wie häufig die Bilder vom Modell trainiert werden sollen. Ein Trainingsdurchlauf aller Bilder in einem Datensatz wird als Epoche bezeichnet. Für das gezeigte Beispiel wählen wir 15 Epochen. Das heißt, die 50.000 Bilder aus dem Trainingsdatensatz werden dem Modell 15-mal zum Training vorgelegt.
Um das Modell nach jeder Epoche zu speichern, muss beim Training ein Modelcheckpoint Callback übergeben werden. Callbacks dienen in Keras dazu, Aktionen vor und nach einzelnen Trainingsschritten und Epochen auszuführen. Im Falle des Modelcheckpoint Callbacks wird das aktuelle Modell gespeichert.
Mit nur 18 Zeilen Code können wir somit ein Training inklusive Evaluierung mit TensorFlow und Keras durchführen. Zusätzlich gibt uns Keras während des Trainings den aktuellen Fortschritt und die Ergebnisse der Evaluationen in der Kommandozeile aus. Hat man TensorFlow mit GPU-Unterstützung installiert, wird das Training direkt auf der GPU ausgeführt.
Um das gespeicherte Modell für eine Prediction anzuwenden, sind einige weitere Zeilen Code notwendig. Zunächst wird das Modell geladen und dann die Prediction ausgeführt. Um das Beispiel einfach zu halten, nutzen wir das erste Bild der Testmenge. Die Predict-Funktion erwartet eine vierdimensionale Eingabe, aus diesem Grund wird dem Bild in der vorangehenden Zeile Code eine erste Dimension zu den drei vorhandenen hinzugefügt.
import numpy as np
model = tf.keras.models.load_model("checkpoint.hdf5")
first_image = np.reshape(x_test[0], (1, 32, 32, 3))
prediction = model.predict(first_image)
print("Prediction: ", np.argmax(prediction),
" Expected: ", y_test[0])Alles im Blick: TensorBoard
Das aktuelle Modell ist noch recht einfach. Da die Arbeit mit neuronalen Netzen allerdings sehr komplex sein kann, sind Tools für einen guten Prozessüberblick hilfreich. Mit TensorBoard bietet TensorFlow ein Werkzeug an, um den Trainingsfortschritt, den Aufbau des neuronalen Netzes und weitere Werte zu visualisieren. Zusätzlich hilft TensorBoard bei der Optimierung und der Fehlersuche. Zur Integration von TensorBoard in unser Training muss zusätzlich ein TensorBoard Callback übergeben werden, der die Daten für eine spätere Visualisierung und Analyse speichert.
tb_callback = tf.keras.callbacks.TensorBoard
(log_dir="logs")
model.fit(x_train, y_train, epochs=15,
validation_data=(x_test, y_test),
callbacks=[cp_callback, tb_callback])Auch eine Liveüberwachung ist möglich. Bereits während des Trainings kann man TensorBoard mit dem Kommandozeilenbefehl tensorboard --logdir=logs ausführen. Zu beachten ist der konfigurierte Pfad, der relativ zum Ausführungsordner des Trainingsskripts ist. Ist TensorBoard gestartet, kann mit einem Browser zur angegebenen URL navigiert werden (standardmäßig http://localhost:6006).
Unter dem TensorBoard-Reiter „Scalars“ können die Kurven der Accuracy und des Losses sowohl für den Trainingsdatensatz als auch für den Testdatensatz betrachtet werden. Merkmal einer guten Bilderkennung ist, dass die Kurve für die Trainingsdaten bei der Accuracy gegen 1 und beim Loss gegen 0 strebt. Unter dem Reiter „Graphs“ lässt sich zudem der Aufbau des Modells anzeigen. Dies kann besonders bei komplexeren Modellen sehr hilfreich sein, um falsche Verdrahtungen aufzudecken.
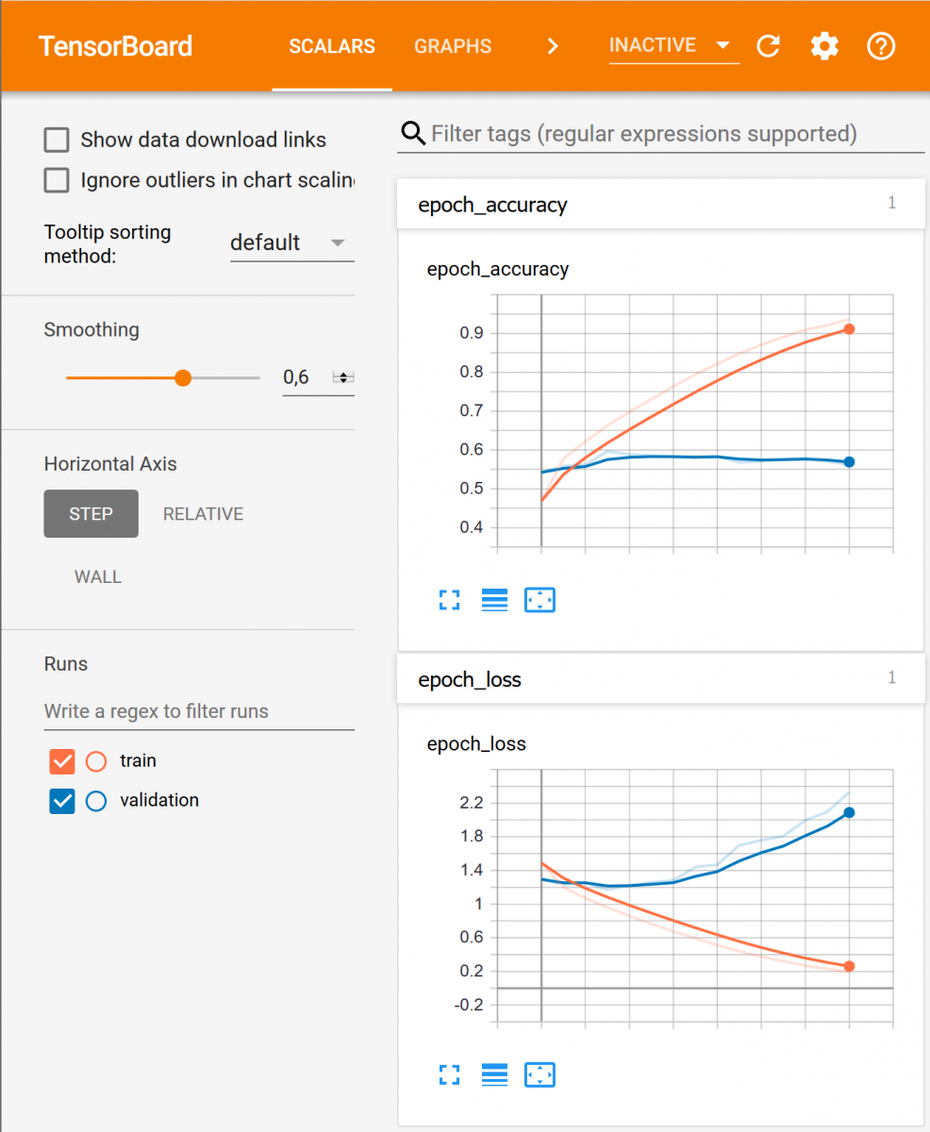
Mit TensorBoard bietet TensorFlow ein Werkzeug an, um den Trainingsfortschritt, den Aufbau des neuronalen Netzes und weitere Werte zu visualisieren. So können etwa die Kurven der Accuracy und des Losses sowohl für den Trainingsdatensatz als auch für den Testdatensatz betrachtet werden. (Screenshot: Tensorboard)
TensorBoard bietet noch weitere Möglichkeiten, Einsicht in die Modelle und das Training zu erlangen. Beispielsweise können Histogramme oder Bilder ausgegeben werden oder das Training kann ähnlich wie in einer IDE debuggt werden.
Zu viel gepaukt: Overfitting
Bei dem für das Beispiel gewählten Modell lässt sich gut erkennen, dass beim Training ein Overfitting stattgefunden hat (siehe Abbildung links). Overfitting zeigt sich im Trainingsverlauf dadurch, dass das Modell auf dem Trainingsdatensatz (orange) immer besser wird, auf dem Testdatensatz (blau) allerdings stagniert oder sich sogar verschlechtert.
Was bedeutet das? Man kann sich Overfitting wie „auswendiglernen“ vorstellen. Das Modell spezialisiert sich zwar auf die ihm gezeigten Trainingsbilder, erlernt aber keine abstrakte Beschreibung einer Klasse. Dies hat zur Folge, dass das Modell auf unbekannten Bildern ein schlechteres Ergebnis liefert.
Gegen Overfitting gibt es verschiedene Maßnahmen. So können mehr Daten helfen, die Varianz in den Trainingsdaten zu vergrößern, und damit das Auswendiglernen erschweren. Zusätzlich kann Dropout (zufälliges Ausnullen einiger Werte) das Modell dazu bringen, sich nicht auf einzelne Werte zu verlassen, sondern mehrere Merkmale für eine Klassifizierung in Betracht zu ziehen.
Fazit
Wir haben mit TensorFlow 2.0 und Keras erste Schritte bei der Entwicklung und dem Training neuronaler Netze unternommen. Mit wenigen Zeilen konnte ein einfaches Modell erstellt, trainiert und evaluiert werden. TensorBoard bietet eine einfache Möglichkeit, den Trainingsverlauf zu beobachten und zu analysieren. Das komplette Codebeispiel sowie ein Modell, welches eine bessere Genauigkeit erreicht, stellen wir auf GitHub bereit.
Jetzt ist ein guter Zeitpunkt, um sich die Themenfelder Machine Learning und Deep Learning zu erschließen: Die schlankere und einfachere API im neuen TensorFlow 2.0 bietet im Vergleich zur aktuellen TensorFlow-Version 1.13 geringere Einstiegshürden. Zur weiteren Vertiefung bieten sich Aspekte wie Eager Execution, Pipelines zur Datenverarbeitung und TensorFlow Lite für mobile Anwendungen an.
