
Digitale Sprachassistenten wie Siri, Alexa oder der Google Assistant sind mittlerweile allgegenwärtig – in Smartphones, Smartspeakern oder Fahrzeugen. Sie beantworten Fragen, egal, ob zum Wetter oder zum aktuellen Weltgeschehen, steuern Smarthome-Installationen, spielen Musik oder sorgen für Unterhaltung.
Aber wie funktioniert das eigentlich? Wie verstehen Sprachassistenten, was Nutzer von ihnen wollen? Dazu schauen wir uns im Folgenden mal etwas genauer an, was hinter den Kulissen eines Smartspeakers eigentlich passiert.
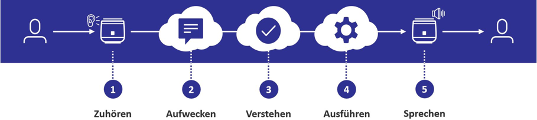
Die Sprachverarbeitungskette eines Sprachassistenten lässt sich in fünf verschiedene Teilschritte zerlegen:
(Grafik: mm1)
Zuhören
Die erste zentrale Komponente sind die Mikrofone. Smartspeaker brauchen Mikrofone, damit sie überhaupt hören können. Über die Mikrofone wird fortlaufend – wenn die Taste „Mikrofon aus“ nicht aktiviert ist – ein Audiosignal in den Speaker gegeben. Allerdings kann der Sprachassistent mit diesem Signal noch nichts anfangen, da es sich um ein analoges, also hörbares, Audiosignal handelt. Daher wird es als erstes in der Audioverarbeitung in ein digitales Signal umgewandelt. Hier wird das Signal so aufbereitet, dass etwa Störsignale herausgefiltert werden und die Stimme des Nutzers möglichst klar zu verstehen ist.

(Grafik: mm1)
Aufwecken
Dieses digitale und optimierte Audiosignal wird kontinuierlich an die nächste Komponente, den „Wake up Word“-Erkenner, weitergereicht. Ein Wake-up-Word (WuW) ist das Wort, mit dem ein Kunde den Sprachassistenten aufwecken kann – bekannt sind „Okay Google“, „Hey Siri“, „Alexa“ oder auch „Hallo Magenta“. Um zu verstehen, wie das funktioniert, müssen wir etwas tiefer in die Spracherkennung eintauchen. Generell wird unter Spracherkennung die Fähigkeit einer Maschine oder eines Programms verstanden, gesprochene Wörter und Sätze zu identifizieren und in maschinenlesbare Informationen zu übersetzen. Ein gesprochener Satz beziehungsweise Sprache allgemein besteht aus aneinandergereihten Tonsequenzen. Diese Tonsequenzen aus dem digitalen Audiosignal werden in Frequenzen zerlegt und dann in einem zeitlichen Verlauf, einem sogenannten Spektrogramm, dargestellt. In einem solchen Diagramm lassen sich die Schalleigenschaften von Sprachelementen wie etwa Konsonanten und Vokalen erkennen. Wenn man weiß, wie die Schalleigenschaften von einem bestimmten Wort, beispielsweise „Alexa“, aussehen, kann man sie relativ einfach im Spektrogramm des Audiosignals entdecken. Mittlerweile werden speziell dafür trainierte Algorithmen im WuW-Erkenner eingesetzt. Hat der im Spektrogramm des Audiosignals die Schalleigenschaften des spezifischen WuW erkannt, gibt er ein Signal ans System, das sagt: „Hey Sprachassistent, hier will jemand mit dir sprechen“ und er fängt an, die darauffolgende Sprachaufzeichnung in die Cloud zu schicken. In dem Moment signalisiert der Speaker genau das auch dem Kunden – meistens durch einen Ton oder eine LED-Animation.

(Grafik: mm1)
Verstehen
Die automatische Spracherkennung (oder auch ASR für Automatic Speech Recognition) wird meistens in der Cloud und nicht lokal auf den Speakern durchgeführt. Hier wird das gleiche Prinzip angewendet wie beim Erkennen des WuW, lediglich im größeren Stil. Im Spektrogramm werden Schalleigenschaften von Tonsequenzen analysiert, bis ein sinnvolles Wort und ein sinnvoller Satz entstehen. Das wird mittlerweile meist von Machine-Learning-Algorithmen bewerkstelligt, die sowohl akustische als auch linguistische Informationen in Sprache modellieren. Aus Sprache wird Text (häufig abgekürzt als STT – Speech To Text).
Im nächsten Schritt wird dieser Satz mithilfe eines NLU-Systems (Natural Language Understanding) in seine einzelnen semantischen und grammatikalischen Bestandteile zerlegt, damit Rückschlüsse über die Bedeutung der Aussage möglich werden.

(Grafik: mm1)
Ausführen
In Beispielsatz „Alexa, wie ist gerade das Wetter in Berlin“ ruft der Sprachassistent nun den Wetterskill auf und gibt ihm die bekannten Informationen „Intent: Wetter aktuell, Entität: Berlin“ mit. Dieser Skill spricht nun mit einem angeschlossenen Wetterdienst und beschafft so die gesuchten Informationen. Aus diesen Informationen wird im Skill eine passende Antwort formuliert.

(Grafik: mm1)
Sprechen
Diese Antwort liegt momentan noch im Textformat vor. Damit der Sprachassistent dem Nutzer antworten kann, muss der Text in Sprache umgewandelt werden. Der Sprachsynthesizer reiht im Prinzip Tonsequenzen mit den entsprechenden Schalleigenschaften für Vokale, Konsonanten oder ganze Wörter aneinander und generiert dadurch ein digitales Sprachsignal. Auch hier kommen Machine-Learning-Algorithmen zum Einsatz, die dem Synthesizer eine möglichst natürliche Aussprache beibringen. Dieses digitale Signal wird im letzten Schritt an die Lautsprecher des Speakers weitergegeben und somit wieder in ein hörbares Signal umgewandelt und der Nutzer bekommt die Antwort auf seine Frage.

(Grafik: mm1)
Und das ist im Wesentlichen, wie ein Sprachassistent menschliche Sprache versteht und darauf reagiert. Bessere Mikrofone und Algorithmen zur Audioverarbeitung, Fortschritte im Machine Learning und Deep Learning und die Verfügbarkeit von Trainingsdaten haben möglich gemacht, dass die Spracherkennungstechnologie mittlerweile zufriedenstellend nutzbar ist. Teilweise sind die Fehlerraten jedoch auch bei den Marktführern in der Spracherkennung noch hoch, da Wörter zum Beispiel bedingt durch Dialekte und Soziolekte unterschiedlich klingen können. Doch die Technologie entwickelt sich mit hoher Geschwindigkeit weiter, sodass hier in wenigen Monaten bis Jahren deutliche Verbesserungen zu erwarten sind.
