
1-Bit-Sprachmodelle sollen viele KI-Probleme lösen: Diese Vorteile bringen sie mit sich
")
Wie Ein-Bit-LLM die Welt der KI verändern können. (Bild: Kitinut Jinapuck/Shutterstock)
Künstliche Intelligenz steht vor einem großen Zukunftsproblem. Da die Modelle immer größer werden, steigen zeitgleich die Kosten für KI. Zudem wirkt sich KI immer stärker auf unsere Umwelt aus. Die Lösung könnten Ein-Bit-LLM sein, die deutlich kleiner, schneller und energieeffizienter sind.
Was unterscheidet 1-Bit-Sprachmodelle von anderen LLM?
Normalerweise speichern große Sprachmodelle ihre Parameter als 32- oder 16-Bit-Gleitkommazahlen. Das sorgt dafür, dass die Parameter präzise, aber bei Modellen mit drei Milliarden Parametern sehr speicherintensiv sind. Werden KI hingegen mit ungenaueren Parametern trainiert, leidet darunter die Präzision der Antworten. Doch wie Forscher:innen herausgefunden haben, können die Parameter gerundet und dadurch vereinfacht werden, ohne Performance zu verlieren.
Um solche Ein-Bit-Sprachmodell zu erzeugen, gibt es zwei Wege. Entweder nehmen Forscher:innen ein schon bestehendes Modell und vereinfachen die vorhandenen Parameter oder sie trainieren ein neues Sprachmodell mit den ungenaueren Parametern von Beginn an. Tatsächlich hat sich die erste Methode bei vielen Wissenschaftler:innen durchgesetzt, da dadurch keine neuen Trainingsdaten gesammelt werden müssen.
Das sogenannte Quantisieren komprimiert die Parameter und ersetzt etwa die komplexen Werte 0.2961, -0.0495 und 0.0413 stattdessen mit 1, -1 und 0. Die Parameterwerte nehmen dann nicht mehr jeweils 16 oder 8 Bit ein, sondern belaufen sich auf nur ein Bit. Obwohl die Ergebnisse im Detail ungenauer sind, ändert sich der Output der KI kaum.
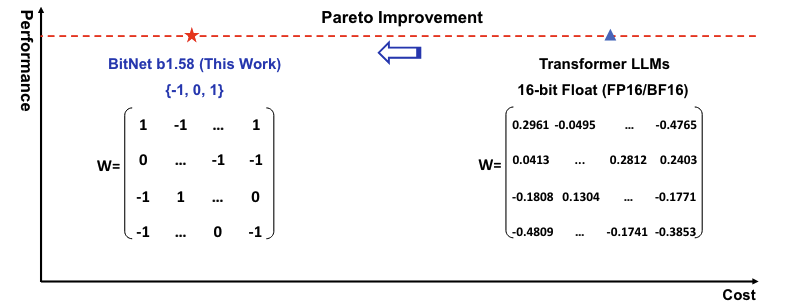
Obwohl die Parameter einfacher sind, kann die KI mit den komplexeren KI-Parametern mithalten. (Bild: Microsoft Research Asia)
Was sind die Vorteile von 1-Bit-LLM?
Ergebnisse der Ein-Bit-LLM lassen sich bereits im Paper The Era of 1-Bit LLMS: All Large Language Models are in 1.58 Bits von Microsoft Research Asia sehen. In einem Vergleich mit dem großen Sprachmodell LLama brauchte Bitnet b1.58 nur einen Bruchteil des Speichers und hatte deutlich niedrigere Latenzen, ohne bei der Performance zurückzufallen.
Ein-Bit-Sprachmodelle sind aber nicht nur kleiner und schneller als ihre großen KI-Verwandten. Im Vergleich zu aktuellen LLM, die vor allem durch leistungsstarke GPU betrieben werden, könnten Ein-Bit-Sprachmodelle auch auf kleineren CPU laufen. So hat Bitnet 1.58b in ersten Tests etwa 94 Prozent weniger GPU-Energie benötigt. Laut Expert:innen könnte es für solche Modelle sogar eines Tages eigene Hardware geben, die nur für den Betrieb von Ein-Bit-LLM gedacht ist.
Das würde auch langfristig dazu beitragen, dass künstliche Intelligenz umweltfreundlicher wird. Wenn KI-Modelle nicht mehr auf ressourcenhungriger Hardware laufen müssen, reduzieren sich dadurch Stromverbrauch und CO2-Fußabdruck der LLM. Für Nutzer:innen hätte das außerdem den Vorteil, dass Modelle mit der Leistung von ChatGPT auch auf Endgeräten ohne Internetverbindung möglich wären.

