
Deep Learning und Data-Science für Einsteiger

Viele Unternehmen arbeiten heute noch mit rudimentären KI-Systemen, die teilweise selbst entwickelt, teilweise hinzugekauft wurden. In Zukunft werden diese Systeme optimiert, durch bessere ersetzt oder gänzlich neu gedacht werden. Das erfordert eine gute Projektplanung. Bei einem KI-System mag der Algorithmus der wissenschaftlich interessantere Teil sein, in der Praxis geht es jedoch vor allem darum, das System in die IT-Infrastruktur und den Geschäftsprozess zu integrieren.
Das Verhalten des Systems muss außerdem vor, während und vor allem nach der Integration validiert werden. Das ist keine einfache Aufgabe, da wir es mit äußerst komplexen Systemen zu tun haben. Vor allem aber ist es keine Aufgabe, die technische KI-Experten – ob nun als Data-Scientist, Machine-Learning- oder Deep-Learning-Engineer bezeichnet – ganz alleine übernehmen können. Wer diese Tätigkeiten selbstsicher ausüben und die Verantwortungen für derartige Projekte übernehmen will, benötigt generelles Wissen über die Verfahrensweisen und Konzepte gängiger KI-Systeme. Und ab dem Anlauf der KI-Projekte müssen die Testergebnisse fachlich plausibilisiert werden.
Wer aus einer Führungs- oder Fachexpertise heraus in KI-Themen einsteigen will, muss vorher seine Hausaufgaben machen, seine Fähigkeiten auch beweisen und idealerweise sichtbar machen.
Künstliche Intelligenz, Machine Learning und Deep Learning
Maschinelles Lernen ist eine Sammlung von mathematischen Methoden der Mustererkennung. Dabei gibt es Verfahren, die ihren Ursprung in der Stochastik haben und mit Häufigkeiten des Auftretens – also Wahrscheinlichkeiten – bestimmter Ereignisse in den Daten arbeiten und darauf basierend Prognosen erstellen können. Sie sind auch dann leicht anzuwenden, wenn kategorische Daten untersucht werden sollen. Bedingte Wahrscheinlichkeiten und Entropie sind hierbei wichtige Konzepte.
In der Praxis eines Entwicklers treten jedoch häufig Probleme auf, wenn es entweder zu wenige Daten oder zu viele Dimensionen der Daten gibt. Deshalb ist die erfolgreiche Entwicklung von Algorithmen maschineller Lernverfahren das sogenannte Feature-Engineering. Als Features werden die Attribute (im Grunde sind das die Spalten einer Tabelle) aus einer Menge selektiert, die für die Lernverfahren sinnvoll erscheinen. Für diese Vorselektion bedient sich ein Data-Scientist wiederum statistischer Verfahren.
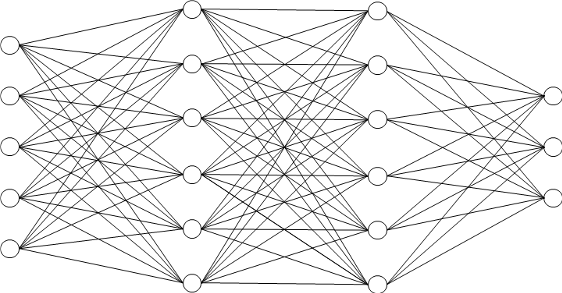
Eine Darstellung eines einfachen künstlichen neuronalen Netzes. Die fünf Neuronen (links) übermitteln die Eingangssignale, die über zwei Schichten von Neuronen Signale an drei Ausgangsneuronen (rechts) übertragen. Die zwei Schichten an Neuronen können dabei auch als Filter betrachtet werden. (Grafik: Benjamin Aunkofer)
Deep Learning (DL) ist eine Teildisziplin des maschinellen Lernens unter Einsatz von künstlichen neuronalen Netzen. Während die Ideen für klassisches maschinelles Lernen aus einer gewissen mathematischen Logik heraus entwickelt wurden, gibt es für künstliche neuronale Netze ein Vorbild aus der Natur: biologische neuronale Netze.
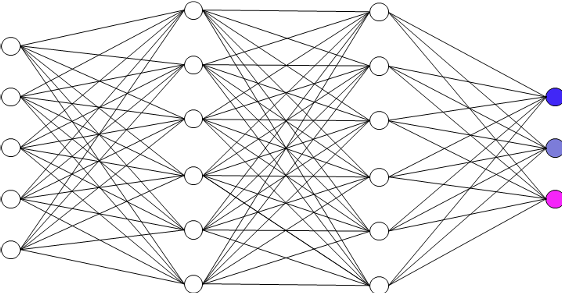
Den drei Ausgangs-Neuronen werden drei Klassen-Bedeutungen zugewiesen (etwa „Hund“, „Katze“ oder „Maus“). Die kann man sich vorstellen wie kleine Lämpchen, die jeweils dann leuchten, wenn pro Datensatz eine bestimmte Klasse gegeben ist. (Grafik: Benjamin Aunkofer)
In der Praxis sind KI-Systeme, die etwa in Robotern oder autonomen Fahrzeugen vorkommen (sollen), hybride Systeme, die neben den Lernverfahren auch mit festen Regeln ausgestattet sind. Man kann sie als die Instinkte des Systems betrachten: Auch Lebewesen lernen nicht nur über Neuronen, sondern haben angeborene Instinkte, die sich nicht – oder nur sehr schwer – brechen lassen.
Sind maschinelles Lernen und Deep Learning für Normalbürger zu verstehen?
Klassische Verfahren des maschinellen Lernens sind nicht besonders schwer zu erlernen. Der einzig notwendige Schritt ist es, sich ein Stück weit auf Mathematik einlassen zu können. Statistik spielt im Deep Learning nur eine untergeordnete Rolle, denn Deep Learning arbeitet algorithmisch mit Algebra und Optimierungsrechnung. Aber auch hier gilt – und nun brechen wir den Mythos –, dass man kein Mathe-Genie sein muss, um zumindest die bekanntesten Verfahren verstehen zu können.
Das Erlernen von Deep Learning ist im Grunde noch etwas einfacher, zumindest, wenn der Einsteiger auf die detaillierte Theorie zu verzichten bereit ist. Deep Learning umfasst zwar sehr komplexe Algorithmen, die über komplizierte Formeln erklärt werden können: Das gilt sowohl für die Grundlagen des Trainierens künstlicher neuronaler Netze als auch für spezielle Netzarchitekturen. Selbst erfahrene AI-Experten kommen schnell in Erklärungsnot, wenn sie bestimmte Architekturen wie etwa das rekurrente neuronale Netz oder den Autoencoder im Detail erklären sollen.
Einsteiger sollten sich davon aber nicht beirren lassen. Der Einstieg in die KI darf gerne über die Praxis erfolgen, bei der es darum geht, die Leistungsfähigkeit des Netzes über das reine Versuchen des Hinzufügens oder Löschens von Schichten an Neuronen im Netz zu verbessern.
Dieses Wissen reicht aus, um die Prinzipien, Stärken und Grenzen der KI verstehen zu können. Ein Data-Scientist oder Machine-Learning-Engineer jedoch muss weit tiefer einsteigen. Ein Algorithmus mag schnell und leicht trainiert sein – seine Prognose-Treffsicherheit aber von 94,3 auf 95,6 Prozent zu steigern, kann in echte Wissenschaft ausarten und sehr viel Hartnäckigkeit verlangen.
Theorie, Programmierung und Praxis
Für den Einstieg gilt: Die klassischen Verfahren des maschinellen Lernens können der erste Schritt in Richtung Deep Learning sein und lassen sich am besten in der Theorie erlernen. Einige Verfahren, wie beispielsweise der ID3-Algorithmus zum Aufbau von Entscheidungsbäumen, können mit einfachen Rechenbeispielen auf Papier gut nachvollzogen werden. Einsteiger können somit auch ohne Programmierkenntnisse maschinelle Lernverfahren verstehen. Dabei kann dieser Einstieg in die Theorie nach jeweiligen Vorlieben erfolgen: Einige der Algorithmen wie Naive Bayes und Entscheidungsbäume stammen konzeptionell aus der Statistik, andere hingegen von der Idee her aus der Algebra und Optimierungsrechnung, so zum Beispiel die Support Vector Machine.
Wem das generelle Verständnis nicht reicht und wer erste Programmierkenntnisse mitbringt, sollte sich in die Programmiersprache Python einarbeiten und mit der kostenlosen ML-Bibliothek Scikit-Learn Programmierbeispiele dazu nachvollziehen. Hier gibt es gute Tutorials im Internet sowie gute Bücher auf Englisch und auch auf Deutsch. Vor allem auf der Programmier-Ebene gibt es auch gute Online-Kurse, wie etwa von Udemy oder Dataquest.io.
Für den Einstieg in Deep Learning gibt es Online-Kurse, Tutorials und Bücher. Dabei ist es für Deep Learning gut möglich, die Theorie der künstlichen neuronalen Netze nur oberflächlich zu behandeln und möglichst schnell praktisch einzusteigen. Um die Programmiersprache Python und die Bibliotheken Tensorflow und Keras wird dabei auch kein Neueinsteiger herumkommen. Tensorflow ist eine von Google veröffentlichte (Open-Source-)Bibliothek für Deep Learning, die von der mitgelieferten Bibliothek Keras erweitert wird. Keras ist in Tensorflow enthalten und abstrahiert die Konzepte neuronaler Netze auf einer höheren Ebene, sodass über Bausteine (Schichten) künstliche neuronale Netze mit wenigen Code-Zeilen erstellt und ausgeführt werden können.
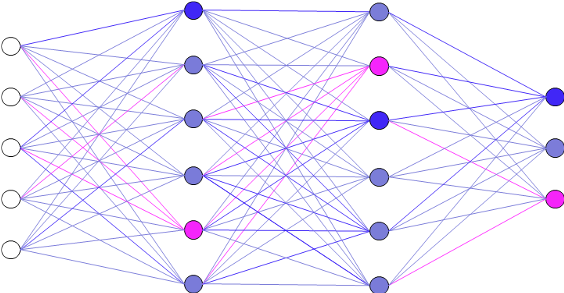
Über ein Training erstellt das künstliche neuronale Netz ein Modell, das die Eingabesignale mit den Ausgabesignalen ins Verhältnis setzt. Dabei nehmen die Verbindungen zwischen den Neuronen unterschiedliche Gewichtungen an, um für jeden Datensatz möglichst verlässlich die richtige Klasse zu bestimmen. (Grafik: Benjamin Aunkofer)
Damit ist die Erstellung von mehrschichtigen künstlichen neuronalen Netzen leicht möglich und für jedermann testbar. Lediglich größere Herausforderungen werden durch die Hardware limitiert. Wer Millionen von Bildern über Deep Learning klassifizieren will, kann dafür auf die Hardware und voreingestellte Services von den Cloud-Anbietern Microsoft, Amazon oder Google zurückgreifen. Testzugänge mit einmaligem Guthaben zur Nutzung der Ressourcen ermöglichen dabei den kostenfreien oder zumindest den kostengünstigen Einstieg.
Für einfache Beispiele von künstlichen neuronalen Netzen reicht die Hardware, die ein gängiges Notebook bietet, jedoch aus. Auf Gaming-Notebooks oder mobilen Workstations mit Nvidia-Grafikkarten können dabei sogar bereits anspruchsvollere Aufgaben bewältigt werden, denn Grafikprozessoren können im Vergleich zur CPU Fließkommazahlen deutlich schneller ausrechnen.
Hartnäckigkeit ist Grundvoraussetzung
Der Einstieg in Deep Learning erfordert sowohl den Einstieg und die Vertiefung in die Programmierung als auch in die mathematische Theorie des maschinellen Lernens. Hinzu kommen für besonders ambitionierte Tüftler die Herausforderungen mit den Programmierbibliotheken, Cloud-Diensten oder Treiberkonfiguration zur Nutzung von Grafikprozessoren. Das führt zum eigentlichen Grund, warum viele Einsteiger scheitern: Interessierte müssen viel Hartnäckigkeit und eine Neigung zum autodidaktischen Lernen mitbringen.
Ebenfalls interessant: Data Science – Ressourcen zum selber lernen
