
Deepseeks kleine Geschwister: So nutzt ihr die Mini-Ableger der KI lokal auf eurem Rechner

Das KI-Modell Deepseek R1 hat für einigen Wirbel gesorgt. Nicht nur, weil es effizienter als vergleichbare Modelle arbeitet, sondern auch, weil es das chinesische Startup unter einer Open-Source-Lizenz veröffentlicht hat. Damit kann theoretisch jeder das Modell nutzen. In der Praxis dürften allerdings nicht sehr viele Privatpersonen existieren, die das Modell in einer halbwegs vernünftigen Geschwindigkeit auf ihrer eigenen Hardware ausführen können.
Allerdings hat Deepseek zusammen mit dem R1-Modell auch eine Reihe kleinerer Modelle veröffentlicht. Laut Unternehmensangaben soll damit gezeigt werden, wie „Reasoning“, also die Fähigkeit des Modells, aus den gegebenen Informationen Schlussfolgerungen zu ziehen, auch auf kleinere Modelle übertragen werden kann.
Genaugenommen handelt es sich bei diesen kleineren Modellen nicht um Varianten von R1. Vielmehr hat sich Deepseek der sogenannten Destillation bedient. Im KI-Kontext versteht man darunter einen Vorgang, bei dem die Fähigkeiten eines größeren und komplexeren Modells auf ein einfacheres Modell übertragen werden.
Im Fall der kleinen Deepseek-Modelle wurde also R1 genutzt, um die Fähigkeiten auf verschieden große Modellvarianten von Metas Llama 3.1 und Alibabas auf Mathematikaufgaben optimiertes Qwen2.5-Math zu übertragen.
Die Methode hat aber natürlich ihre Grenzen. Ein Modell mit sieben Milliarden Parametern wird am Ende nicht dieselbe Qualität liefern können wie ein Modell mit mehr als 600 Milliarden Parametern. Hier gilt trotz aller Effizienzsteigerungen der letzten Zeit grundsätzlich immer noch: Viel hilft viel.

Mit Tools wie LM Studio könnt ihr die kleinen Deepseek-Modelle einfach lokal auf eurem Computer ausführen. (Screenshot: LM Studio / t3n)
So nutzt ihr die kleinen Deepseek-Modelle auf eurem Rechner
Es gibt verschiedene Methoden, um Sprachmodelle auf dem heimischen Rechner auszuführen. Ein beliebtes Werkzeug ist beispielsweise Ollama. Allerdings handelt es sich dabei um ein Kommandozeilenwerkzeug ohne eigene grafische Benutzeroberfläche. Für Entwickler:innen, die einmal von der KI erzeugte Daten direkt weiterverarbeiten wollen, ist Ollama zwar perfekt, wir wollen euch an der Stelle aber einen Weg zeigen, der für Menschen ohne Terminal-Erfahrung etwas einfacher ist.
Dazu nehmen wir das Programm LM Studio. Das ist kostenfrei für Macs mit Apple Silicon, Windows und Linux verfügbar. Nach der Installation fragt euch LM Studio sofort, welches Sprachmodell ihr herunterladen wollt.
Deepseek hat insgesamt sechs destillierte Modellvarianten veröffentlicht. Für die Größeren davon könnte eure Hardware aber unter Umständen nicht ausreichend stark sein. Praktischerweise zeigt euch LM Studio in dem Fall aber eine Warnung an.
Wir wollen es uns an der Stelle aber die auf mittleren Modellvarianten DeepSeek-R1-Distill-Qwen-7B und DeepSeek-R1-Distill-Llama-8B konzentrieren. Beide findet ihr direkt über die Modell-Suche in LM Studio, die ihr wiederum jederzeit über einen Klick auf das Lupen-Icon in der rechten Navigationsleiste aufrufen könnt.
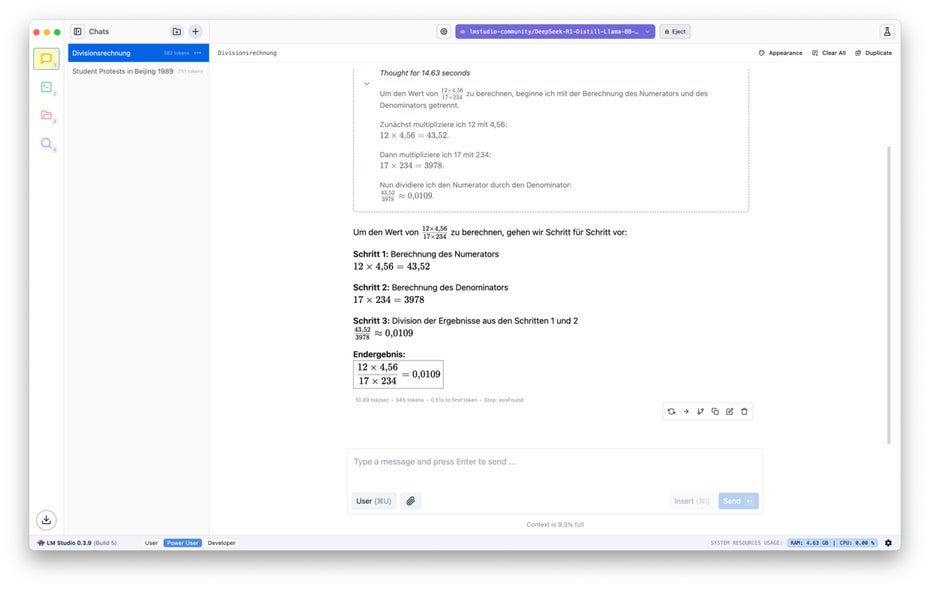
Moderner Taschenrechner: Mathematikaufgabe für die KI. (Screenshot: LM Studio / t3n)
Die kleinen Geschwister von Deepseek R1 ausprobiert
Es ist durchaus beeindruckend, wie die von uns ausprobierten Modelle mit überschaubarer CPU- und Speichernutzung auf einem Macbook Air mit M1-Chip ihre Reasoning-Fähigkeiten präsentieren und sich Schritt für Schritt zur eigentlichen Beantwortung des Prompts durcharbeiten.
Bei LM Studio wird dieser Prozess allerdings standardmäßig ausgeblendet. Um ihn zu sehen, klickt ihr entweder jedes Mal auf das Thoughts-Feld oder ihr klickt oben auf Appearance und aktiviert dort den Schieberegler mit der Aufschrift Expand reasoning blocks by default. Dann ist das entsprechende Feld automatisch ausgeklappt.
Während Website und App von Deepseek alles dafür tun, die staatlichen chinesischen Zensurregeln umzusetzen und von Pekings Führung unerwünschte Antworten zu unterdrücken, müsst ihr bei den selbstgehosteten Deepseek-Modellen davor keine Angst haben.

Sowohl DeepSeek-R1-Distill-Qwen-7B als auch DeepSeek-R1-Distill-Llama-8B beantworten beispielsweise Fragen zum Tian’anmen-Massaker grundsätzlich korrekt.
Unsere Mathematik- und Coding-Aufgaben erfüllen beide Modelle weitestgehend zuverlässig. Auch wenn an der Stelle klar sein muss, dass die Ergebnisse nicht an die Qualität großer Cloud-Modelle heranreichen.
Das zeigt sich auch beim Umgang mit unterschiedlichen Sprachen. Zwar könnt ihr grundsätzlich eure Prompts auch auf Deutsch formulieren, bei den Antworten mischt sich bisweilen aber auch mal Englisch ins Deutsche.
Bei der überschaubaren Größe der Modelle müssen weiterhin Abstriche in der Qualität gemacht werden. Das wird sich auch so schnell nicht ändern. Dennoch zeigen beide Modelle, dass auch in diesem Bereich weiter Fortschritte erzielt werden. Immerhin zieht das von ausprobierte DeepSeek-R1-Distill-Qwen-7B in einigen Mathebenchmarks an OpenAIs o1-mini vorbei.
