Google trainiert KI, zeitgleich zu sehen und zu hören

Wenn KI-Systeme beispielsweise gleichzeitig eine Stimme und ein Gesicht in einem Video erkennen sollen, werden dazu heutzutage zwei voneinander getrennte Machine-Learning-Modelle eingesetzt. Forscher:innen von Google, der Universität Cambridge und dem britischen Alan Turing Institute haben jetzt jedoch einen Weg entwickelt, wie ein einziges Modell gleich mehrere unterschiedliche Formen von Datensätzen untersucht. Das sogenannte Polyvit-System kann laut dem Paper der Wissenschaftler:innen bis zu neun Bild-, Video- und Audio-Erkennungen gleichzeitig durchführen.



„Durch Co-Training von Polyvit auf einer einzigen Modalität haben wir bei drei Video- und zwei Audiodatensätzen Spitzenergebnisse erzielt und dabei die Gesamtzahl der Parameter im Vergleich zu Single-Task-Modellen linear reduziert“, heißt es in dem Paper der Wissenschaftler:innen. Das wiederum soll mehrere Vorteile bieten.
Zum einen soll das System sehr effizient sein. Das ist vor allem dann wichtig, wenn die Software nicht in der Cloud, sondern auf Endgeräten mit begrenztem Speicher ausgeführt werden soll. Außerdem sei ein einzelnes Modell leichter mit Updates zu versorgen, heißt es von den Wissenschaftler:innen.
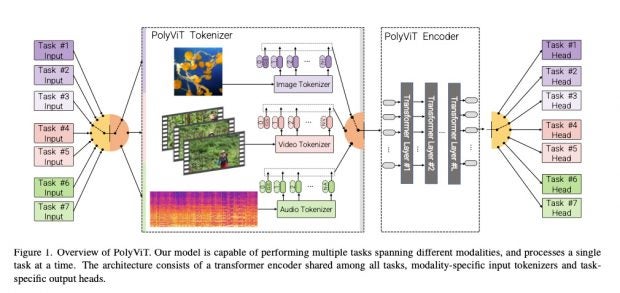
Grafische Darstellung des Polyvit-Systems. (Grafik: „PolyViT: Co-training Vision Transformers on Images, Videos and Audio“)
Das sind die nächsten Schritte für die Technik
Noch wurde das System nicht an wirklich großen Datensätzen getestet. Das wollen die Forscher:innen erst in einem nächsten Schritt nachholen. Außerdem sollen sich die verschiedenen Aufgaben des Systems zukünftig gegenseitig optimieren, um noch bessere Ergebnisse erzielen zu können.

Jetzt noch jemand von Boston und wir haben einen kompletten Roboter gebaut, der dann die Menschheit auslöscht. Naja, ob das jetzt so das Wahre ist.