
Hässlich geklaut bei t3n.de oder: Wie man Content-Diebstahl kreativ für sich nutzen kann

Während sich manche Content-Diebe wenigstens noch die Mühe machen, ihre Spuren zu verwischen, indem sie Texte minimal verändern oder Bilder austauschen, gibt es auch immer häufiger den Fall, dass unsere Artikel einfach maschinell, automatisiert und unverändert übernommen werden. Die betreffenden Seiten sind oft Content-Farmen, die unsere Inhalte für SEO-Zwecke nutzen wollen oder einfach „unbedarfte Anwender“, die es als „ok“ ansehen, mal eben Inhalte großer Websites zu kopieren und bei sich online zu stellen.
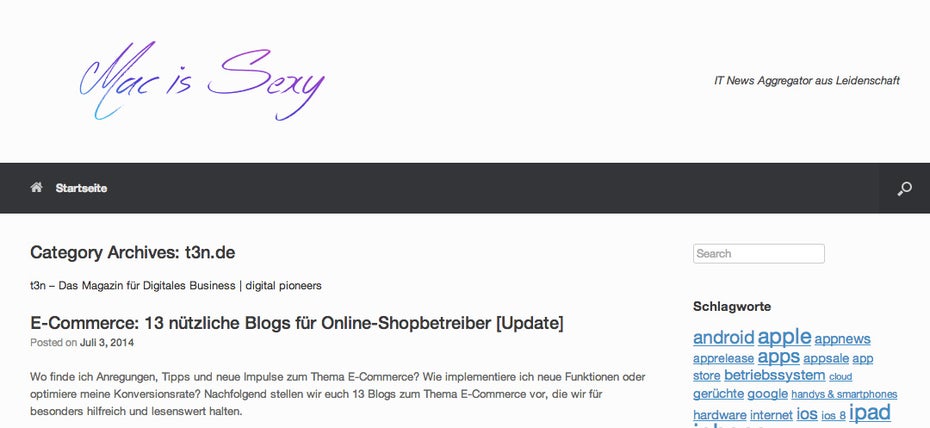
Mac is sexy: Eine von vielen Content-Scraping-Seiten, die unsere Inhalte kopieren. (Screenshot: mac-is.sexy)
Natürlich beobachten wir diese Fälle sehr genau und scannen das Netz regelmäßig nach neuen Vorfällen. In den meisten Fällen empfinden wir es allerdings eher als Overhead, rechtliche Schritte gegen die Betreiber einzuleiten. Solche Verfahren sind uns zu teuer und verschlingen zu viele Ressourcen.
Einfach akzeptieren wollen wir dieses Verhalten aber auch nicht. Abgesehen davon, dass wir jeden Klon-Website-Betreiber natürlich zunächst kontaktieren und ihn freundlich, aber bestimmt bitten, den Content-Klau einzustellen, haben wir uns jetzt noch eine kleine, technische Sofortmaßnahme ausgedacht.
Wir lassen unseren Webserver möglichst hässliche Animated GIFs ausliefern
Wenn Content-Diebe unsere Bilder auf ihren Seiten nur verlinken und nicht auf ihre eigenen Server kopieren, können wir mittels der Referer-Angabe im HTTP-Header herausfinden, von welcher URL ein HTTP-Request stammt. Kommt die Anfrage von einer uns bekannten Content-Farm, können wir über unseren nginx-Webserver alle Bilddateien automatisch durch eine andere Datei ersetzen. So lassen wir zukünftig alle Bilddatei-Anfragen von Seiten auf unserer internen Blacklist mit diesem Katzen-GIF-Diebstahl-Hinweis ersetzen. Das Ergebnis lässt sich in freier Wildbahn dann hier betrachten.

Content-Diebe kriegen von uns dieses animierte GIF ausgeliefert, wenn sie Bilder von unserem Server abfragen. (Bild: t3n/Cat-Content: omgcatsinspace.com)
Wie funktioniert das technisch?
Das Prinzip sich vor Hotlinking zu schützen, ist nichts Neues. Wir sind da mit t3n.de eher locker unterwegs, weil wir es nicht schlimm finden, wenn wir zum Beispiel in einem Newsletter direkt eingebunden werden oder ein Tool unsere Inhalte auf einer externen Seite rendert. Trotzdem kann man für bestimmte „referer“ (das ist ein HTTP-Header mit der „Aufruf-Domain“, den jeder gängige Browser mitschickt) bestimmte Aktionen starten. Interessant ist das besonders als schnelle „Sofort-Maßnahme“, wenn der Betreiber einer Website nicht gut zu ermitteln ist.
Für Bilder, die auf einer Seite auf den fiktiven Content-Klau-Domains „katzen-sind-toll.de“ oder „ich-klaue-content.de“ eingebettet werden, könnte man im nginx zum Beispiel folgende Regel definieren:
#nginx configuration
if ($http_referer ~* (katzen-sind-toll.de|ich-klaue-content.de)) {
rewrite ^ /images/anticontentklau.gif;
}
Anstelle des Inhalts wird dann das Animated GIF anticontentklau.gif ausgeliefert. Das kann man dann natürlich noch auf bestimmte Dateiendungen beschränken und so weiter. Natürlich gibt es auch hier aus Sicht des Content-Diebes wieder Möglichkeiten, unseren Mini-Diebstahlschutz zu umgehen, aber das Animated GIF dürfte schon hässlich genug sein, um eine gewisse Wirkung zu zeigen.
Wie seht ihr das? Ist unser Animated GIF hässlich genug? Wie geht ihr mit Content-Klau um?

Haha! Sehr geile Lösung! Finde, ihr macht das beste daraus.
Ihr hättet jetzt nur noch den Link auf mac-is sexy auf nofollow setzten sollen ;)
Ahh.. Danke! Richtig blind. Hab ich jetzt drin!
Ihr habt da ein paar Probleme mit eurer Serverkonfiguration… Wenn ich eine dieser „Content-Klau“ Webseiten besuche, werden die Katzenbilder in meinem Cache gespeichert und auf t3n werden auf dem jeweiligen Artikel auch die Katzenbilder angezeigt :x
Habe ich angepasst. Danke für den Hinweis!
Wieso sind rechtliche Schritte zu aufwendig? Screenshot machen und einem Anwalt übergeben und der Betreiber erhält (natürlich nur wenn man den Betreiber einfach identifizieren kann) eine Abmahnung die sich gewaschen hat.
Ist mir selber schon einmal passiert muss ich gestehen. Vor Jahren mit einem Foto, bei dem ich keine Bildrechte hatte. 10.000 Euro Abmahnung bei der schließlich dann 1500 zu zahlen waren.
Mir ist es aus Nichtwissen passiert, da finde ich, sollte man vl so kulant sein wie ihr. Aber bei bewussten Content-Klau ist das was anderes.
Außerdem ist das für euer Ranking auch nicht gut, Stichwort Duplicate Content…
Wir hatten bislang noch keine Probleme mit unseren Rankings. Der Trust der anderen Domains ist in der Regel unterirdisch, insofern ist das kein Problem.
„Zu aufwendig“ trifft es vielleicht nicht exakt, eher „nicht unser Stil“. Würde ich als letzte Maßnahme zwar nicht ausschließen, aber erst mal sprechen und versuchen das Thema auf dem kurzen Dienstweg zu regeln, finden wir deutlich sinnvoller als sofort abzumahnen. Hat auch in den allermeisten Fällen zum Erfolg geführt.
So einfach ist das nicht zumal die t3n Artikel zu 90% nicht selbst produzierte Inhalte sind und meist selbst nur kuratierte News oder direkt üersetzte von Quellen wie TC,Mashable und co.
Sofern du selbst kein aufwendig geschütztes Medium aka Video oder Bildmaterial ohne weitere Quellenangabe verlinkst oder kopiert anzeigts, bist du auch in keinem Fall belangbar.
Da kannste soviel screenshots machen wie du willst und bullshit Abmahnungen verschicken, was eh ein Witz ist, da DE eines der letzten Länder mit dieser Rechtsmöglichkeit ist.
Moin!
Hatte ich auch mal. War zwar „nur“ das Facebook-Icon, aber die Fremdreferrer haben meine Logfile-Auswertung immer versaut. Habe dann sämtliche Bildabrufe, die nicht von meiner Webseite kamen auf ein „Werbebanner“ umgeleitet – und blieb satte 2 Jahre unbemerkt!
Gute Idee ;-) Witzig allemal. Werde das eventuell auch mal für meine Seiten umsetzen. Darauf bin ich noch gar nicht gekommen. Man geht meistens davon aus, dass Leute sowas nicht machen würden.
Contentklau ist dreist und ich finde, Ihr solltet auch juristisch gegen Content-Farmen vorgehen. Es kann ja nicht sein, dass die immer weiter munter Profit daraus schlagen.
Wie wäre es wenn Ihr selbst auch einige Artikel mit diesem Katzenbild verseht? Wäre durchaus angebracht! Am besten dann bitte auch noch mit Quelle. Danke! ;)
Einfach konkrete Beispiele nennen, dann schaut sich das unsere Redaktion gerne an.
Das würde dann ja auch Seiten betreffen, von denen man lediglich eine Info-Grafik „übernimmt“ oder den Text übersetzt. Wer im Glashaus sitzt…
Hi,
das Problem ist, dass viele gar kein Unrechtsbewusstsein haben. Bei unserer Astrologie Seite wurden unsere Sternzeichen Beschreibungen über 200 Mal auf anderen Webseiten – meist private Blogs – veröffentlicht. Ein paar besonders dreiste haben alle Sternzeichen-Texte übernommen und Adsense Werbung dabei eingeblendet. Das große Problem: Bei den privaten Blogs findet man meistens kein Impressum bzw. irgendwelche Kontaktdaten. Dafür wird bei einer E-Mail an den Hosting Dienstleister meist der geklaute Beitrag / der Blog schnell gelöscht / gesperrt.
Es hat uns viel Zeit gekostet, alle Content Klauer anzuschreiben. Ein paar Abmahnungen haben wir auch verschickt (an die dreisten…). Aber es ist ein Wahnsinn, das bezahlt niemand!
Google hat teilweise den geklauten Content höher gerankt als unseren bei schicksal.com, was besonders bitter war.
Es gibt aber noch die Content Scraper, die gleich die komplette Webseite spiegeln und deren Ad Codes einblenden.
Wenn Ihr auch von solchen Scrapern betroffen seid, dann hab ich noch einen Tipp. Ich bin dahinter gekommen, dass dafür häufig die „AppEngine“ von Google verwendet wird. Die bauen dort eine „App“, die die komplette Website spiegelt.
Das kann man mit einer einfachen Rewrite Rule verhindern:
RewriteCond %{HTTP_USER_AGENT} ^AppEngine
RewriteRule ^.*$ – [F]
Wie kommt man drauf: Einen Artikel nehmen, einen Satz rauskopieren und ihn mit Anführungszeichen bei Google suchen.
Noch ein Tipp: Wir haben ein Javascript entwickelt, dass Copy & Paste abwandelt. Statt der ganze Text wird nur der erste Satz mit der aktuellen URL in die Zwischenablage kopiert. Ich bin noch nicht dazu gekommen, daraus eine Open Source Geschichte zu machen, werde ich aber noch tun, wenn ich mehr Zeit habe.
Bin auch für weiter Tipps dankbar!
lg,
Georg.
Dafür wird nicht notwendigerweise die API von google verwendet. Das wird seit Jahren mit RSS scraper gemacht.
PS: Die Katze, die Ihr da verwendet, die habt Ihr doch auch geklaut!!!!! ;-)
Das hats wohl gebracht :-)
Die Seite wird nun auf http://www.google.ru umgeleitet, nachdem der Webserver nur noch „Internal Server Error“ ausgeliefert hatte.
Hallo
wir hatten (und haben) auch mit dem Problem Content-Klau zu kämpfen.
Irgendwann hatten wir ein ähnliches JavaScript wie Georg in unsere Seiten integriert. Seitdem ist es schon mal weniger geworden.
Probiert mal einen Text auf http://www.aritso.net zu kopieren.
Nur kopieren, nicht klauen bitte. :-)
Hallo Andreas,
das Script was Ihr benutzt sieht sehr interessant aus, ist das Opensource?
Beste Grüße
Das Script ist eine jQuery-Bind, welches wir erstellt haben. Wir haben dazu kein Lizenzmodell festgelegt.
Ich habe nichts dagegen wenn jemand die Funktion verwendet.
Zu finden ist die Funktion in der Datei http://www.aritso.net/templates/aritso/javascript/scripts.js
Support kann ich dafür aber nicht bieten.
Hallo,
Content-Klau ist natürlich „böse“, aber wegen einigen Störern gleich alle Benutzer zu gängeln kann ja auch nicht der richtige Weg sein.
Auf eurer Seite geht es ja sogar so weit, dass ich mir z.B. noch nicht einmal die Kontaktdaten oder Telefonnummer in die Zwischenablage legen kann. Halte ich persönlich für sehr schlechten Stil und für ähnlich ärgerlich, wie das Umbiegen der rechten Maustaste.
Danke für Dein Feedback.
Wir haben nicht die rechte Maustaste belegt, sondern nur die Kopierenfunktion.
Das Kopieren der Kontaktdaten, oder anderer Inhalte, die evtl. kopiert werden sollen werde ich überdenken.
In der linken Seitenleiste wurde das z.B. berücksichtigt. Die Kontaktbox kann kopiert werden.
Hallo Andreas,
der Vergleich mit der rechten Maustaste ging nicht in Richtung eurer Website, sondern eher allgemein.
Der Hinweis auf das Kopieren der Adresse war nur ein x-beliebiges Beispiel für durchaus legitimes Kopieren in die Zwischenablage. Nicht jeder, der Inhalte kopiert, will sie auch gleich klauen.
Und — sorry — aber ich probiere doch auf der Website nicht lange herum, welche Adresse in welcher Infobox ich jetzt kopieren darf und welche nicht.
Mir geht es auch nicht speziell um deine Website, sondern diese Technik allgemein. Ich halte das doch für eher zweifelhaft.
Probier mal mit ctrl+a und dann ctrl+c … man kann trotzdem kopieren.
Irgendwelche Funktionen des Browsers/Betriebssystems zu brechen, ist einfach nur unprofessionell.
Falls jemand Euren Content abgreifen möchte, ich wüsste nicht wozu, würde das sicherlich nicht per Copy-Paste passieren.
Ich möchte euer gedrucktes Magazin abbestellen!
Da bist du hier leider an der falschen Adresse. Wende dich am besten an support@t3n.de.
Ist zwar nur die softe Variante und schreckt die Content-Farmer bestimmt nicht ab, clever nonetheless: http://www.tynt.com – allein schon für die Statistiken zu den Kopiervorgängen interessant…
Klasse, vielleicht hört ihr dann ja auch auf von TechCrunch und co. abzuschreiben und fangt an mal mehr eigenen Content zu schreiben.
Du meinst so wie in diesem Artikel auf den du gerade kommentierst? ;)
gekonnt auf Kritik reagiert – Chapeau!
schade, meine Ironic-Tags wurden kommentarlos geschluckt, bitte sinnvoll für meinen Kommentar verwenden ;o)
Nein, eher sowas:
https://t3n.de/news/10-css-properties-mehr-koennen-542226/
–> http://www.sitepoint.com/12-little-known-css-facts/
Naja, sie haben ja die Quelle genannt und sich die Mühe gemacht ihn zu übersetzten ;D
Euer Vorgehen finde ich richtig. Mir geht es auch gegen den Strich, dass einem irgendwelche Leute einfach den Content klauen. Nur weil sie nicht in der Lage sind eigene Inhalte zu erstellen und sich mal selbst ne Platte zu machen.
Was nun diese Vorwürfe gegen t3n angeht: irgendwoher müssen die Informationen ja kommen und die Jungs und Mädels von t3n schreiben nicht einfach ab ;) Mal davon abgesehen, gibt es hin und wieder mal einen Artikel, der einfach misslungen ist. Aber das gehört dazu. Jeder Goldgräber findet auch mal einen Steinklumpen.
Wir sehen das naturgemäß genauso, danke für den Kommentar. Für Journalisten und beispielsweise auch Nachrichtenagenturen gehört das Kuratieren relevanter News zum Kerngeschäft. Und zumindest wir sind der Meinung, dass wir eine sehr gelungene Mischung aus solchen Stücken und eigenen Geschichten hinkriegen.
Mit deaktiviertem JavaScript ist der Kopiervorgang erfolgreich.
Ich mag das Bild!
Ai ai ai… wie es aussieht zählt Feedly wohl auch zu den Dieben ;)
Wie kommst du darauf? Bei mir werden auf Feedly die richtigen Bilder angezeigt.
Schau mal bei Twitter! ;) LG
Gute Idee! Bei dem Beitrag wurde bewusst das gif eingebeaut. Bei anderen Artikeln ist des ned drin.
Das von Victor beschriebene Problem liegt an den Einstellungen des Caches. Dort zieht sein Browser sich aktuell das Katzen-GIF. Wir haben den Fehler aber schon vor ein paar Stunden behoben. Neue Nutzer sind also nicht betroffen.
Aber ein teasern und verlinken dürfte wohl vielleicht sogar eher gern gesehen sein oder? Grüße
Großartige Idee. Und was ich am besten finde ist die Tatsache, daß ihr den „Dieben“ einfach mal Schrott unterschiebt. Nee, am Besten ist es, dass ihr eben NICHT die Anwälte losrennen lasst. In Deutschland wird eh ständig jeder von jedem verklagt und ich habe als Blogger echt manchmal Angst, überhaupt noch was zu schreiben, was ich irgendwo anders gelesen habe.
Insofern: Respekt für eure total hässlichen GIFs und für die coole Art und Weise. Und an diejenigen, die hier mit den Anwälten drohen wollten. Ich glaube, dass so mancher Content-Dieb die CC-Lizenzen einfach nur falsch verstanden hat und das nicht wirklich böse gemeint hat. Denn ich glaube an das gute im Menschen.
Ich hätte nicht gedacht, dass es Webseiten gibt, die die Artikel wirklich in der Originalversion ohne eine Änderung übernehmen…Da ist das Katzenbild sicherlich die beste Lösung!
Finde es gut, dass ihr die Sache eher „locker“ angeht und nicht sofort den Rechtsweg geht. So bleiben die sauberen Blogger, die eure Beiträge als Quelle verwenden und, wie gesagt, ein Foto in den Newsletter einbauen, davon verschont. Bei einem 1:1 Klau wäre der Rechtsweg dennoch angebracht.
Schöne eigene Interpretation dieses alten aber erst kürzlich wieder populären Artikels http://www.portent.com/blog/random/stop-plagiarism-in-3-easy-steps.htm