Custom KI: Wie Unternehmen LLM in ihre Enterprise-Services integrieren
")
Quarkus ist ein JVM-basiertes Framework, das neue Ansätze für die Verarbeitung von Unternehmensdaten und die Interaktion mit Kunden ermöglicht. (Foto: GaudiLab/Shutterstock)
Integrieren Unternehmen Large Language Models (LLM) wie ChatGPT in ihre Enterprise-Services, können sie die Technologie auf neue Arten nutzen. Mitarbeitende können Sprachdaten verarbeiten und in bestehende Systeme integrieren, und Entwickler können komplexe Anwendungen schaffen. Dabei hilft ihnen etwa LangChain. Das Software-Framework wurde entwickelt, um die Fähigkeiten von LLM zu nutzen, zu erweitern und zu optimieren.
In Verbindung mit Quarkus, einem JVM-basierten Framework, dessen Stärke vor allem in der Umsetzung von Cloud-Native-Lösungen liegt, entstehen neue Ansätze für die Verarbeitung von Unternehmensdaten und die Interaktion mit Kunden.
LangChain mit Quarkus verbinden
Um LangChain mit Quarkus zu verbinden, muss zunächst ein neues Quarkus-Projekt gestartet werden. Mit wenigen Klicks wählen Entwickler das gewünschte Build-Tool – zum Beispiel Maven, Gradle oder Gradle mit Kotlin DSL –, die Java-Version und die zu verwendenden Erweiterungen aus.
Für das Beispiel mit LangChain werden die folgenden Erweiterungen benötigt:
io.quarkus:quarkus-resteasy-reactiveio.quarkiverse.langchain4j:quarkus-langchain4j-core:0.7.0io.quarkiverse.langchain4j:quarkus-langchain4j-openai:0.7.0
Mithilfe der REST-Easy-Erweiterung wird eine einfache API entwickelt, um den KI-Service zu nutzen. Wer statt OpenAIs ChatGPT-Modellen lieber Modelle von Hugging Face verwenden möchte, ersetzt die dritte Erweiterung durch
io.quarkiverse.langchain4j:quarkus-langchain4j-hugging-face:0.7.0Um mit Quarkus und LangChain ein LLM wie ChatGPT oder Modelle von Hugging Face zu nutzen, müssen zunächst ein AiService-Interface registriert und der OpenAI-API-Schlüssel konfiguriert werden.



Ein AiService ist hier ein Interface, das mit
@RegisterAiServicechatWithMailBot()
Zusätzlich kann dem LLM über die Annotation
@SystemMessageUm die OpenAI-API zu nutzen, muss in der Quarkus-
application.properties
LLM wie ChatGPT sind stateless, man kann mit ihnen also keine direkte Unterhaltung führen, weil sie immer nur die aktuelle Anfrage verarbeiten können. Um dennoch eine aufeinander aufbauende Unterhaltung zu ermöglichen, müssen der Gesprächsverlauf gespeichert und bei jeder neuen Anfrage alle alten Anfragen und Antworten wieder mitgeschickt werden. Das erhöht allerdings die Anzahl der Input-Tokens und damit die Kosten.
In Quarkus können Entwickler ein Bean definieren, das das Interface
ChatMemoryStoreInMemoryChatMemoryStoreUm die Unterhaltung eines Nutzers zu referenzieren, wird mithilfe der
@MemoryIdUm den
MailAiService
Zur Vereinfachung wird die ID der Unterhaltung über einen Query-Parameter übergeben. In einer echten Anwendung sollte diese ID über eine Authentifizierung validiert werden.
RAG-Einstellungen vornehmen
Eine Retrieval-Augmented-Generation (RAG)-Architektur kombiniert den Informationsabruf aus großen Datenbeständen mit der Fähigkeit zur Textgenerierung von LLM. Ziel dieser Architektur ist es, die Qualität und Relevanz der generierten Antworten zu verbessern, indem kontextbezogene Daten für eine Anfrage bereitgestellt werden.
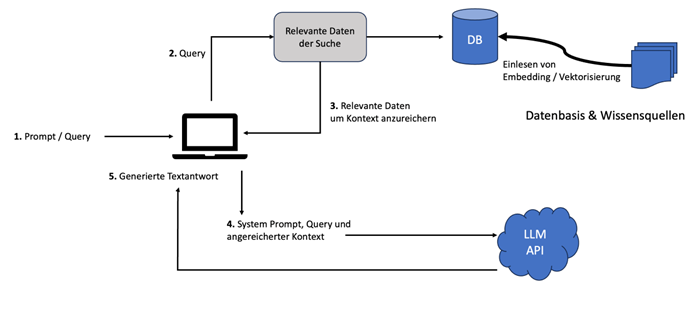
(Grafik: Andreas Eberle und Wolfgang Frank)
- Prompt/Query: Das RAG-System erhält einen Prompt mit einer Anfrage (Query). Ein Prompt ist eine Aufforderung oder ein Hinweis, den ein Benutzer gibt, um das System zu einer bestimmten Aktion oder Antwort zu veranlassen. Dabei werden häufig verschiedene Bestandteile des Prompts unterschieden:
a. Der System-Prompt ist eine spezielle Form, der vom RAG-System vorgegeben wird, um genauer auf die Anforderungen des ursprünglichen Prompts des Benutzers zu reagieren und die grundsätzlichen Regeln, Möglichkeiten und Verhaltensweisen des Systems zu beschreiben.
b. Der Kontext bezieht sich auf zusätzliche Informationen, die mit dem Prompt verbunden sind. Der Kontext wird durch die Suche nach relevanten Informationen aus einer Datenbank angereichert, was zu genaueren und kontextbezogenen Antworten führt.
c. Eine Query ist die spezifische Anfrage des Nutzers, die das RAG-System an seine Datenbank oder Wissensquellen richtet, um relevante Informationen zu sammeln. - Query: Mithilfe der Query wird nach passenden Informationen in einer oder mehreren Wissensquellen gesucht. Das ist der Retrieval-Teil der Architektur, bei dem das System versucht, Daten zu finden, die zur Beantwortung der Anfrage beitragen können. Hier werden oft Vektordatenbanken eingesetzt, die neben Textabschnitten auch deren Vektordarstellungen, sogenannte Embeddings, speichern. Ähnliche Inhalte haben darin nahe beieinander liegende Vektoren. Vektordatenbanken können schnell die nächsten Nachbarn eines Vektors finden und so ähnliche und damit relevante Informationen effizient identifizieren.
- Relevante Daten, um Kontext anzureichern: Die gefundenen Informationen werden verwendet, um den Kontext anzureichern.
- System-Prompt, Query und angereicherter Kontext: Der ursprüngliche System-Prompt, die Anfrage und der nun angereicherte Kontext werden zusammengeführt und an eine Large-Language-Model-API gesendet.
- Generierte Textantwort: Das LLM verarbeitet die eingehenden Daten und generiert unter Berücksichtigung des Kontextes eine Textantwort, die dem Benutzer zurückgeliefert wird.
Dazu kommen Datenbasis und Wissensquellen: Hier werden spezifische Informationen, die dem LLM typischerweise nicht bereits durch sein Training bekannt sind, gespeichert und effizient abfragbar gemacht. Diese Datenbanken enthalten im Enterprise-Umfeld meist aktuelle, unternehmensspezifische Daten.
Quarkus unterstützt mehrere Dokumentendatenbanken für RAG, zum Beispiel Chroma, Pinecone oder PgVector. Im Beispiel kommt Redis zum Einsatz. Dafür muss die Erweiterung
io.quarkiverse.langchain4j:quarkus-langchain4j-redis:0.7.0dev.langchain4j:langchain4j-document-parser-apache-pdfbox:0.25.0![]()
Die RAG-Einstellungen müssen in der application.properties-Datei ergänzt werden und stellen sicher, dass der im Entwicklungsmodus gestartete Redis-Container die Vektorsuche und eine ausreichende Warteschlange unterstützt. Die Dimension des verwendeten Embedding-Models wird aus der jeweiligen Dokumentation entnommen und ebenfalls eingetragen. Das Embedding-Model von OpenAI erzeugt Vektoren mit der Dimension 1536.
Mithilfe eines
EmbeddingStoreIngestorsEmbeddingModelRedisEmbeddingStoreDocumentSplitterFür das Beispiel werden die exportierten PDF der Quarkus-Dokumentation bei jedem Start aus einem Ordner ins Redis importiert.
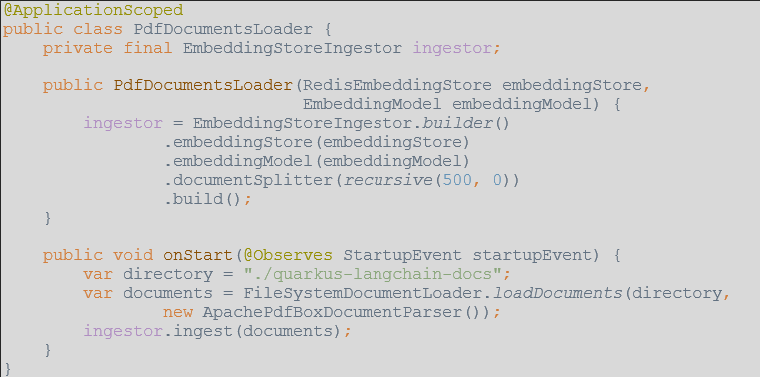
Damit Quarkus die relevanten Dokumente für eine Nutzeranfrage identifizieren kann, muss ein Bean definiert werden, das das Interface
Retriever<TextSegment>EmbeddingModelsRedisEmbeddingStoreEmbeddingStoreRetrieverEmbeddingStoreRetrieverDamit Quarkus den
DocumentsRetriever@RegisterAiServiceretriever@RegisterAiService(retriever = {DocumentsRetriever.class})
Agenten einbinden
Agenten im Kontext von LLM sind spezialisierte Programme oder Algorithmen, die autonom agieren und Aufgaben wie Datenabfrage, -verarbeitung und -analyse übernehmen. Sie erweitern und verbessern die Interaktion mit dem LLM, indem sie relevante Informationen in Echtzeit sammeln und vorverarbeiten und so die Genauigkeit und Anpassungsfähigkeit der Antworten erhöhen. Sie steigern die Funktionalität von LLM, indem sie Aufgaben automatisieren und den Informationsfluss zwischen dem LLM und seinen Datenquellen optimieren.
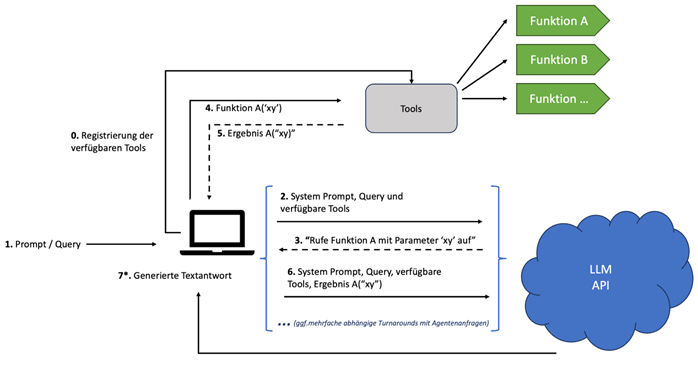
(Grafik: Andreas Eberle und Wolfgang Frank)
Der Ablauf einer Anfrage erfolgt typischerweise wie folgt:
- 0: Registrierung der verfügbaren Tools: Vor Beginn des Prozesses werden alle verfügbaren Tools und Funktionen im System registriert. So kann es auf diese Tools zugreifen.
- 1: Prompt/Query: Der Benutzer startet den Prozess, indem er einen Prompt eingibt.
- 2: System-Prompt, Query und verfügbare Tools: Das System sendet den System-Prompt, die Anfrage sowie die Liste der verfügbaren Tools, die zur Beantwortung der Anfrage verwendet werden können, an das LLM.
- 3: „Rufe Funktion A mit Parameter ‚xy‘ auf“: Basierend auf der Anfrage und den verfügbaren Tools kann das LLM entscheiden, eine spezifische Funktion mit einem bestimmten Parameter aufzurufen, und gibt diese Information als Antwort zurück.
- 4: Funktion A(‚xy‘): Das Agentensystem führt Funktion A mit dem Parameter ‚xy‘ aus.
- 5: Ergebnis A(‚xy‘): Das Ergebnis dieser Funktion wird produziert und steht zur weiteren Verwendung bereit.
- 6: System-Prompt, Query, verfügbare Tools, Ergebnis A(‚xy‘): Das System aktualisiert den Kontext mit dem Ergebnis der ausgeführten Funktion. Dabei handelt es sich um einen iterativen Prozess, bei dem abhängig von der Komplexität der Anfrage möglicherweise mehrere Runden von Agentenanfragen erforderlich sind, bevor das LLM die endgültige Antwort liefern kann.
- 7*: Generierte Textantwort: Schließlich generiert das LLM eine finale Textantwort.
Dieser Ansatz ermöglicht eine tiefe Integration von spezialisierten Tools und Agenten, um die Fähigkeiten des LLM zu erweitern und präzisere sowie kontextuell relevantere Antworten zu generieren.
Sobald in Quarkus eine öffentliche Methode einer Bean mit
@Tool@ToolWird etwa die Method
getContactForNameAddressBookService
Damit der
MailAiServiceAddressBookService@RegisterAiService@RegisterAiService(tools = {AddressBookService.class})Fazit
Die Kombination von LangChain mit Quarkus erleichtert die Integration von Large Language Models in Cloud-native Anwendungen und unterstützt die Anwendung von Retrieval Augmented Generation und Agentensystemen. Entwickler können ihre vorhandenen Kenntnisse im Cloud-Native und Enterprise Development nutzen, um LLMs effizient einzubinden, ohne auf spezialisierte Tools wie Python oder Jupiter Notebooks angewiesen zu sein.
Die Quarkus-Erweiterung für LangChain fördert die nahtlose Integration von KI-Funktionen in existierende Systeme und trägt zur Schaffung einer robusten Entwicklungsumgebung bei. Dadurch wird der Einsatz von LLMs in der Anwendungsentwicklung erleichtert, während bestehende Entwicklungsprozesse beibehalten werden können.
Das Repository zum Beispiel findet ihr auf GitHub.
