Generative KI: Warum Small Language Models manchmal besser sind
")
Je nach Anwendung ist größer nicht immer besser. (Grafik: Midjourney / t3n)
Auch wenn es so scheint, als würde ChatGPT wie von Zauberhand zu schreiben beginnen – die generative KI (GenAI) hinter dem Chatbot holt sich ihre Antworten aus großen Sprachmodellen, den Large Language Models (LLM). Vereinfacht gesagt ist damit das Internet gemeint. Alles – wirklich alles – was jemand veröffentlicht, kann theoretisch in die LLM aufgenommen und als Antwort auf eure Fragen ausgespuckt werden. Klar, dass das nicht ganz ungefährlich ist.
KI-Halluzinationen: Sicheres Auftreten bei totaler Ahnungslosigkeit
Open LLM stützen sich vor allem auf Wahrscheinlichkeitsberechnungen. Sie durchforsten riesige Datenquellen, um ein Modell zu erstellen, das die wahrscheinlichsten Daten zur Beantwortung einer Anfrage vorhersagt. Bei einem Chatbot sind das die Wörter und Sätze, die von der Maschine als am effektivsten angesehen werden.
Im riesigen Meer an Informationen und Optionen ist es kein Wunder, dass die KI oft falsch liegt. Tatsächlich gibt es viele Beispiele, in denen GenAI-Tools zwar auf eine Frage souverän und flüssig antworten, die Inhalte aber völlig aus der Luft gegriffen sind.
KI-Halluzinationen sind normal für LLM: Der Algorithmus versteht die Frage nicht und wird erfinderisch. Das ist so ziemlich die gleiche Strategie, die wir noch aus der Schule kennen, wenn der Lehrer plötzlich eine Frage stellte und wir die Antwort nicht wussten (oder gar nicht erst zugehört hatten).


Klein, aber fein: Small Language Model (SLM)
Schon Yoda wusste: Größe ist nicht alles. Lange galten SLM lediglich als Sprungbrett für ihre großen Brüder. Mittlerweile können jedoch auch die kleinen Sprachmodelle hinsichtlich der Performance gleichziehen – wenn sie sie nicht sogar übertreffen. Statt die GenAI mit dem kompletten Internet zu füttern, wird sie mit hochgradig kuratierten, strukturierten und domänenspezifischen Daten trainiert. Das schränkt eventuell die Bandbreite der Antworten ein, erhöht jedoch ihre Zuverlässigkeit.
Interessant ist das vor allem für KI-Projekte, die sich auf einen definierten Anwendungsbereich konzentrieren. Business-Nutzer wollen nämlich nicht unbedingt, dass eine KI ihnen mehr Informationen liefert. Wäre ich in der Pharmaforschung auf der Suche nach einem neuen Medikament, interessiere ich mich nur leidlich für die Arbeit eines Professors über den Marktwert von Eiscreme in der Antarktis. Was ich möchte, ist ein GenAI-Tool, das eine bestimmte „Sprache“ fließend spricht und von einem bestimmten Bereich – meinem Bereich – viel Ahnung hat.
Kontext statt Informationsflut
Ein großer Vorteil von SLM: In einem kleineren Modell lassen sich Daten leichter kontrollieren und validieren. Das lässt sich beispielsweise über sogenannte Knowledge-Graphen (Wissensgraphen) realisieren. Laut Turing-Institut organisieren Knowledge-Graphen Daten aus unterschiedlichen Quellen in einer Struktur und erfassen dabei Informationen über Entitäten und deren Verbindungen, die für einen bestimmten Bereich oder eine bestimmte Aufgabe relevant sind (zum Beispiel Personen, Orte oder Ereignisse).
Was erstmal abstrakt klingt, ist tatsächlich eine sehr intuitive Art, Daten zu speichern. Stellt euch ein Whiteboard vor: Daten werden als Kreise (Knoten), die Beziehungen zwischen den Daten als Linien (Kanten) dargestellt. Beide können Eigenschaften besitzen (Properties). Voilà, schon habt ihr einen Graphen. Beispiele für natürliche Graphen sind das U-Bahn-System einer Stadt, ein Familienstammbaum und wirklich jede Form von Netzwerk, in dem die Verbindungen zwischen den Daten genauso wichtig sind wie die Daten selbst.
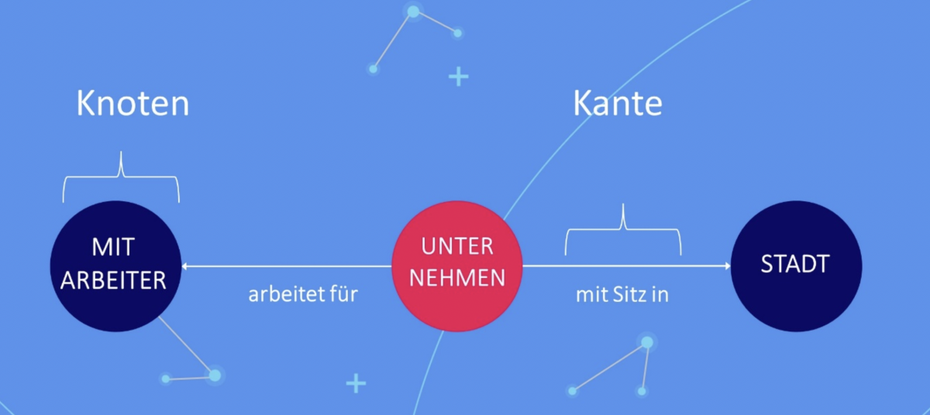
Wie auf dem Whiteboard: Datenmodell im Graphen aus Kanten und Knoten. (Quelle: Neo4j)
Knowledge-Graphen schaffen mit ihrem Fokus auf Beziehungen und Netzwerken einen Kontext. Jeder Datenpunkt lässt sich über die Kanten auf seine ursprüngliche Quelle zurückverfolgen. Jede Information bleibt nachvollziehbar und transparent. Jede Antwort lässt sich erklären und begründen. Damit können Knowledge-Graphen den Sprachmodellen notwendige Grenzen setzen und KI-Halluzinationen und Fehler reduzieren
Breite Adoption, kleiner CO2-Fußabdruck
Das KI-Training anhand von SML hat noch andere Vorteile. Aufgrund der Größe lassen sich die Sprachmodelle grundsätzlich schneller trainieren. Wie Forschungsberichte zeigen, beansprucht das Training dabei zudem weniger Rechenleistung.
Soll KI wirklich zum Allgemeingut werden, muss sie auf einer Vielzahl von Geräten ohne Performance-Verluste arbeiten. Dazu zählt auch kleine und ressourcenbeschränkte Hardware wie Smartphones und Mobilgeräte. SLM könnten also den Weg für eine stärkere Integration der KI in die Alltagstechnologie ebnen.
An die Rechenleistung schließt sich die wichtige Frage der Nachhaltigkeit an. Wie können wir zukünftig den CO2-Fußabdruck von KI reduzieren? Allein das Training des GPT-3-Modells, auf dem ChatGPT basiert, verbraucht nach Schätzungen von Wissenschaftlern bis zu 1.287 Megawattstunden an Strom. Bei SML-trainierten GenAI-Lösungen hingegen dürfte der Wasser- und Stromverbrauch um einiges niedriger ausfallen.
Datenschutz und Sicherheit
Spannend ist schließlich die Kombination von SML mit Federated Learning. Diese Trainingsmethode beschreibt ein Modell, das gleichzeitig auf mehreren Geräten und damit dezentral trainiert wird. Die Trainingsdaten bleiben also beispielsweise auf dem Smartphone und landen nicht irgendwo in einem externen Rechenzentrum.
Die dezentrale Datenspeicherung kennen wir in Deutschland unter anderem von der Corona-Warn-App. Auch hier blieben Informationen zum Standort, Bewegungsmuster und Testergebnis auf dem eigenen Handy. Ziel war es, die personenbezogenen und teils sensiblen Daten besser vor unbefugtem Zugriff und Datenmissbrauch zu schützen. Dieses Plus an Datenschutz und Sicherheit macht Federated Learning auch für GenAI interessant. Denn immerhin sollen die smarten Lösungen irgendwann auch in sicherheitskritischen Branchen zum Einsatz kommen, wo sie hohe Compliance-Vorgaben zu erfüllen haben.
Sicher, SLM können nicht den unerschöpflichen Pool an Antworten und Informationen bieten, den wir momentan von ChatGPT gewohnt sind. Was wir dafür jedoch gewinnen, sind zuverlässige und nachvollziehbare Antworten. Zudem erlauben die kleineren Modelle effizientere KI-Tools, sowohl was die Skalierung als auch die Rechenressourcen angeht.
