KI-Generator Imagen malt dir einen Corgi, der in einem Sushi-Haus wohnt
")
Wer dem Bildgenerator aufträgt, einen süßen Corgi zu malen, der in einem Sushi-Haus wohnt, könnte so ein Bild erhalten. (Bild: Google Imagen)
Google fordert Open AI heraus: Gegen den Text-Bild-Generator Dall-E 2 hat der Suchmaschinen-Multi nun die Software Imagen ins Rennen geschickt. Das KI-basierte Tool biete „einen noch nie dagewesenen Grad an Fotorealismus und ein tiefes Sprachverständnis“, verspricht der Hersteller. Um die beiden Konkurrenten vergleichen zu können, haben Google-Forscher:innen ein eigenes Benchmark-Tool herausgebracht. Dessen Ergebnisse sollen die Überlegenheit der Google-Software beweisen. Das Research-Team veröffentlichte sie in einer eigenen Studie.



Text-Encoder basiert auf mehreren Sprachmodellen
Die Software besteht prinzipiell aus einem Text-Encoder, der die sprachliche Anforderung übersetzt. Für die richtige Visualisierung ist ein hohes Sprachverständnis nötig, weshalb die Entwickler:innen hierfür maschinelles Lernen einsetzen. Als Grundlage dienen große Sprachmodelle wie Bert, T5 und Clip. Die Verfasser haben verschiedene Modelle kombiniert und „vorgelernt“. Sie kommen zu dem Ergebnis, dass ihre Methode den anderen voraus ist. Sie verbrauche zudem weniger Speicher, konvertiere schneller und besitze eine bessere Stichprobenqualität mit schnellerer Inferenz.

Bilderzeugung: Dall-E 2 analysiert und geschlagen
Die eingesetzten Diffusionsmodelle – also die eigentlichen Bildgeneratoren – seien genauer und diverser als die der Konkurrenz, schreiben die Google-Fachleute. Imagen erziele im Benchmark Coco Fid höhere Werte als die Software von Open AI. Dabei nehmen die Verfasser:innen zum einen Bezug auf die Leistung des Text-Encoders, der eine multimodale Einbettung von Clip verwendet. Man habe darlegen können, dass die vortrainierten Modelle, wie Imagen sie verwendet, eindeutige Vorteile besitzen. So habe das Konkurrenzprodukt häufiger Probleme in der Zuordnung von Adjektiven und Objekten. Zum anderen sei auch die Bilderzeugung über das neue dynamische Schwellenwertverfahren und kaskadierte Diffusionsmodelle besonders effektiv.
Nach eigenen Angaben schlägt der eigene Bildgenerator von Google alle anderen. (Tabelle: Google Research)
Neuer Benchmark: Drawbench
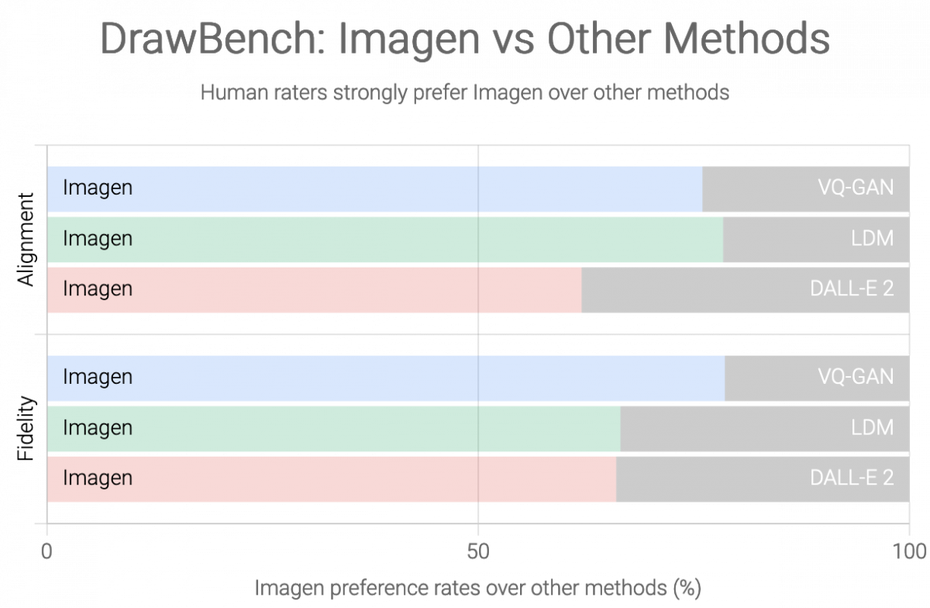
Doch das reichte dem Team nicht. Der Coco-Benchmark sei auf das Bewerten von statischen State-of-the-Art-Modellen trainiert und daher eigentlich nicht optimal geeignet. Es entwickelte deshalb „Drawbench“. Dieser Benchmark basiert auf den Aussagen menschlicher Bewerter. Die ermögliche tiefere Einblicke durch eine mehrdimensionale Evaluierung der Modelle etwa in Hinblick auf Kardinalität, räumliche Beziehungen sowie die Fähigkeit, komplexe Texteinbettungen einzuordnen – auch mit seltenen Wörtern. Die menschliche Bewertung habe diverse Vorteile gegenüber den Scorings anderer Systeme. Imagen schneidet auch im Drawbench besser ab als der Konkurrent aus dem Hause Open AI.

Bei den Tests soll der Dall-E-2-Generator immer mal wieder Dinge durcheinandergebracht haben. (Bilder: Google Research)
