Meta arbeitet an Super-Übersetzer: Das ist das MMS-Projekt
")
Meta hat seine Open-Source-Sprach-KI MMS vorgestellt. (Foto: Shutterstock / DANIEL CONSTANTE)
Meta hat ein KI-Sprachmodell vorgestellt, das den Namen Massively Multilingual Speech (MMS) trägt und damit bereits zum Ausdruck bringt, worin seine Stärken liegen sollen. Es ist jedenfalls kein ChatGPT-Klon.
MMS als Open Source freigegeben
Vielmehr kann MMS über 4.000 gesprochene Sprachen erkennen und Gesprochenes (Text-to-Speech) in über 1.100 Sprachen produzieren. Dabei bleibt Meta seiner bisherigen Linie treu und veröffentlicht das Sprachmodell als Open Source, „damit andere Forscher auf unserer Arbeit aufbauen können“, so das Unternehmen in einem Blogbeitrag.
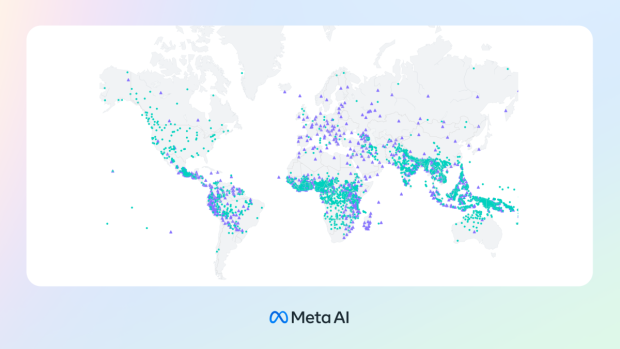
Metas MMS-KI soll über 4.000 Sprachen erkennen (dargestellt durch grüne Punkte) und 1.107 Sprachen transkribieren (lila Dreiecke) können. (Bild: Meta)
Laut Meta soll MMS vor allem „einen kleinen Beitrag zur Erhaltung der unglaublichen Sprachenvielfalt in der Welt leisten“. Nun ist es zunächst nur eine Frage des Aufwands, Spracherkennungs- und Text-to-Speech-Modelle wie MMS zu trainieren.
Je mehr Stunden an Audiotraining mit den dazugehörigen Transkriptionen eingespeist werden können, desto besser. Aber für Sprachen, die in den Industrienationen nicht weitverbreitet sind oder sogar in den nächsten Jahrzehnten auszusterben drohen, „gibt es diese Daten einfach nicht“, so Meta.

Ungewöhnliche Trainingstexte aus der Bibel und Co
Deshalb ging Meta ungewöhnliche Wege und nahm sich die Audioaufnahmen von übersetzten religiösen Texten vor: „Wir wendeten uns religiösen Texten wie der Bibel zu, die in viele verschiedene Sprachen übersetzt worden sind und deren Übersetzungen für die textbasierte Sprachübersetzungsforschung umfassend untersucht worden sind.“
Unter Einbeziehung von Aufnahmen aus der Bibel und ähnlichen Texten gelang es den KI-Expert:innen aus dem Hause Meta, die Anzahl der verfügbaren Sprachen des Modells auf über 4.000 zu erhöhen. Dabei soll im Ergebnis dennoch weder ein Fokus auf weltanschauliche Formulierungen noch auf männliche Sprecher herausgekommen sein, wie in Anbetracht des Quellmaterials möglicherweise befürchtet werden dürfte.
Besonderer Trainingsansatz beseitigt Fehlerquellen
Meta führt das darauf zurück, dass „wir einen konnektionistischen temporalen Klassifizierungsansatz (CTC) verwenden, der im Vergleich zu großen Sprachmodellen (LLM) oder Sequenz-zu-Sequenz-Modellen für die Spracherkennung wesentlich eingeschränkter ist.“
Konkret hat Meta sein MMS mit Whisper von OpenAI verglichen und dabei „festgestellt, dass Modelle, die auf den Daten von Massively Multilingual Speech trainiert wurden, die Hälfte der Wortfehlerrate erreichen“ und zudem „elfmal mehr Sprachen“ abdecken.
Meta will Sprachenvielfalt erhalten
Mit der Freigabe von MMS für die Open-Source-Forschung will Meta den Trend umkehren, dass die Technologie die Sprachen der Welt auf jene beschränkt, die am häufigsten von Big-Tech-Anwendungen unterstützt werden. Dabei handelt es sich um maximal 100.
Meta dazu: „Wir stellen uns eine Welt vor, in der die Technologie den gegenteiligen Effekt hat und die Menschen ermutigt, ihre Sprachen lebendig zu halten, da sie in ihrer bevorzugten Sprache auf Informationen zugreifen und Technologien nutzen können.“
