
Screaming Frog: So nutzt du das SEO-Tool optimal

Nutzer können Metadaten wie zum Beispiel die Meta-Description oder der Meta-Title extrahieren. Weiter gibt der Crawler auch Auskunft über die Vergabe des hreflang-Tags, die interne Linkstruktur (Page Depth Level), defekte Links und mehr. Diese Daten bereitet Screaming Frog übersichtlich auf, zudem lassen sie sich exportieren und in Excel weiterverarbeiten.
Mit der Version 4.0 wurden die Funktionen „Custom Extraction“ und „Custom Search“ eingeführt. Mit Hilfe von Custom Extracion lassen sich beliebige Elemente mit Hilfe von XPath, RegX und CSSPath aus dem Quellcode einer Webseite extrahieren. Das Gegenstück ist die Custom-Search-Funktion, die nicht extrahiert, sondern Elemente im Quellcode aufsucht und URLs ausgibt, die jene Elemente enthalten beziehungsweise nicht enthalten.
Mit der Einführung dieser beiden Funktionalitäten haben die Entwickler von Screaming Frog ein großes Spektrum an neuen Analysemöglichkeiten eröffnet. Im Folgenden werden einige Analysemöglichkeiten vorgestellt, die sich die Extraction-Funktion sowie die API-Anbindungen zunutze machen.
Identifikation von Seiten zur Snippet-Optimierung
Mit dem Release der Version 5.0 wurden erstmals API-Anbindungen in Screaming Frog integriert. Damit ist es möglich, sich Daten aus Google Analytics und der Google Search Console (ehemals Google Webmaster-Tools) URL-bezogen beim Crawling ausgeben zu lassen.
Im Fall der ersten Analyse beziehen wir Daten aus der Google Search Console. Die Idee hinter der Analyse ist, dass wir Unterseiten unserer Webseite finden, die in den Top 10 ranken, jedoch eine schlechte Click-Through-Rate (CTR) haben. Wenn wir jene Seite identifiziert haben, können wir uns die Suchergebnisse zu diesen URLs anschauen und überprüfen, welche Gründe für eine schlechte CTR sprechen und wo Veränderungen vorgenommen werden könnten.
1. Schritt: API-Verbindung herstellen
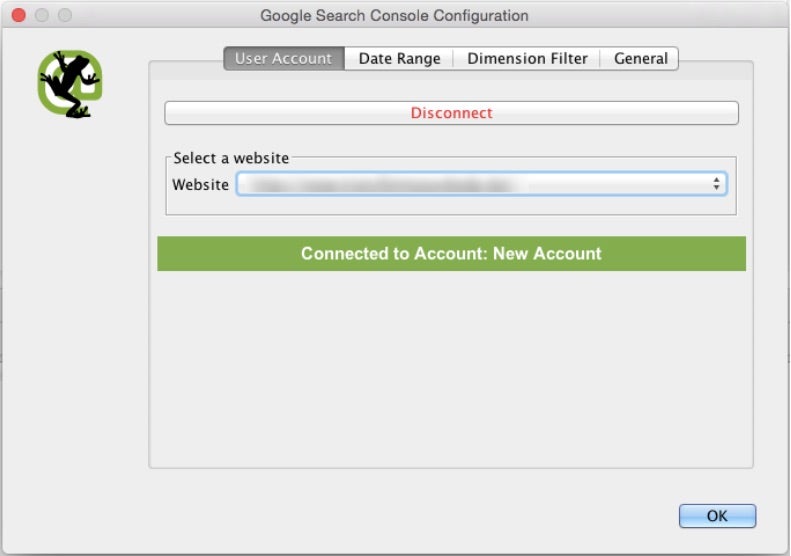
Im ersten Schritt muss eine Verbindung zwischen Screaming Frog und dem Google-Search-Console-Konto hergestellt werden. Dazu wählt man unter „Configuration“ im Menüpunkt „API-Access“ den Eintrag „Google Search Console“. Dort muss man lediglich den Schritten zur Verbindung des Kontos folgen und anschließend unter „Website“ die passende auswählen.
2. Schritt: Einstellungen der API-Abfrage
Wenn die Verbindung hergestellt ist und die passende Webseite ausgewählt wurde, können unter dem Reiter „Date-Range“ und „Dimension-Filter“ noch Einstellungen zum „Datenexport“ gemacht werden.
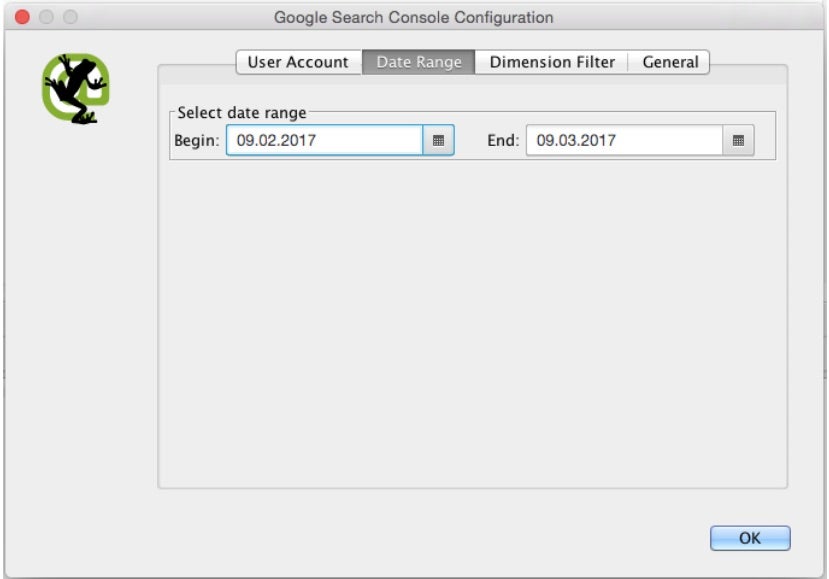
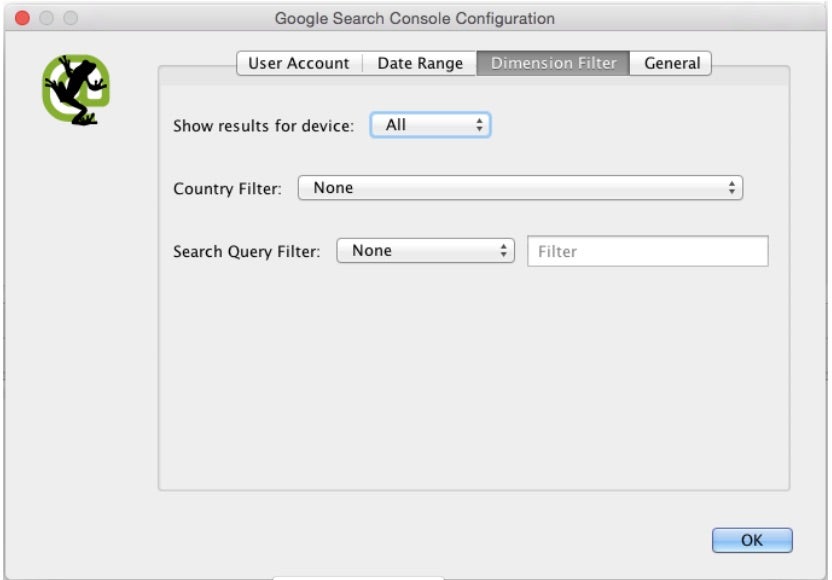
Unter „Date-Range“ bestimmt ihr, aus welchem Zeitraum die Daten stammen sollen. Wenn wir keine Analyse für einen gewissen Zeitraum machen wollen, wählt ihr dort den maximalen Zeitraum von 90 Tagen aus, um möglichst viele Daten zu erhalten. Unter „Dimension-Filter“ kann eingestellt werden, ob ihr nur aus bestimmten Ländern, für bestimmte Geräte oder bestimmte Suchbegriffe Daten beziehen möchtet.
3. Schritt: Crawl und Datenaufarbeitung
Als Ergebnis erhaltet ihr nach dem Crawl eine Excel-Tabelle (Export: Internal HTML) mit Klicks, Impressionen, CTR und der durchschnittlichen Position je URL. Um die Unterseiten zu identifizieren, die Kandidaten für Snippet-Optimierungen sind, filtert man nun die durchschnittliche Position nach kleiner gleich 10 und sortiert anschließend die CTR aufsteigend.
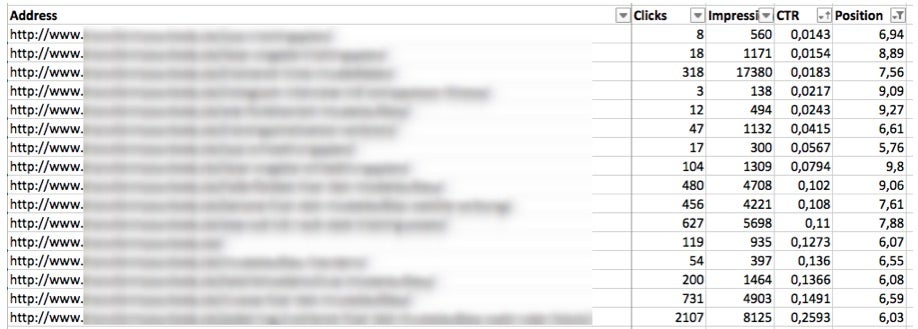
Bulk Google-Pagespeed-Check
Eine niedrige Ladezeit ist aus vielerlei Gründen wichtig, unter anderem für eine hohe Nutzerzufriedenheit und eine hohe Conversionrate. Daher soll die zweite Analyse dazu dienen, zu ermitteln, welche Unterseiten auf unserer Webseite eine unterdurchschnittliche Ladezeit aufweisen. Wenn wir diese Unterseite ermittelt haben, kann man individuell prüfen, welche Gründe für eine schlechte Ladezeit sprechen.
Bei dieser Analyse müssen wir wie in der ersten beschrieben eine API-Verbindung herstellen. Diesmal jedoch mit der Google-Analytics-API. Wenn die Verbindung zum Google-Analytics-Konto hergestellt wurde, müssen einige Einstellungen vorgenommen werden: Als allererstes muss die richtige Property und der richtige View sowie das Segment „All Users“ ausgewählt werden. Dies gilt nicht, wenn ihr zum Beispiel ausschließlich eine Analyse für Mobileuser durchführen möchtet.
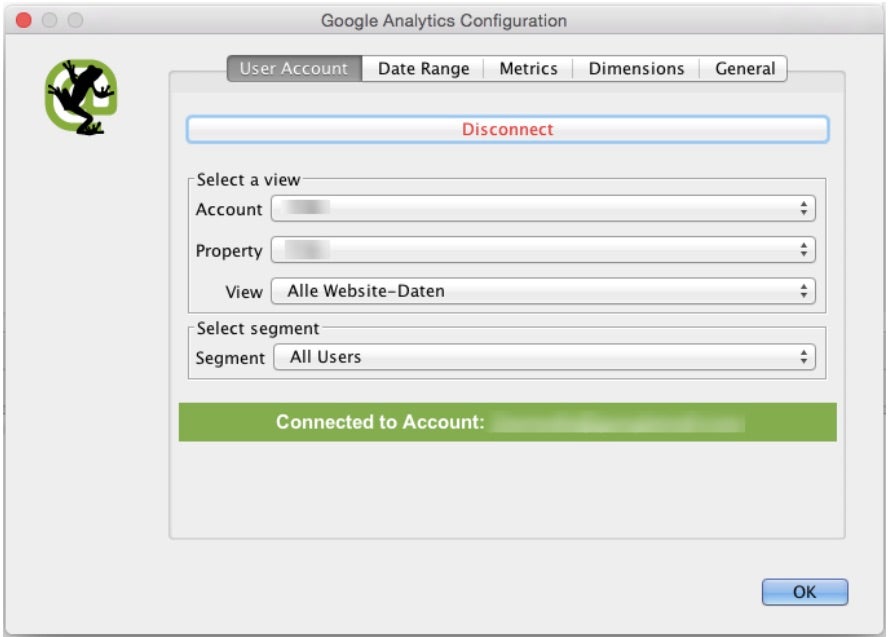
Im nächsten Schritt müssen die Metriken ausgewählt werden, die wir aus der API beim Crawling exportieren wollen. In unserem Fall möchten wir ausschließlich die durchschnittliche Ladezeit (ga:avgPageLoadTime) aus der API beziehen.
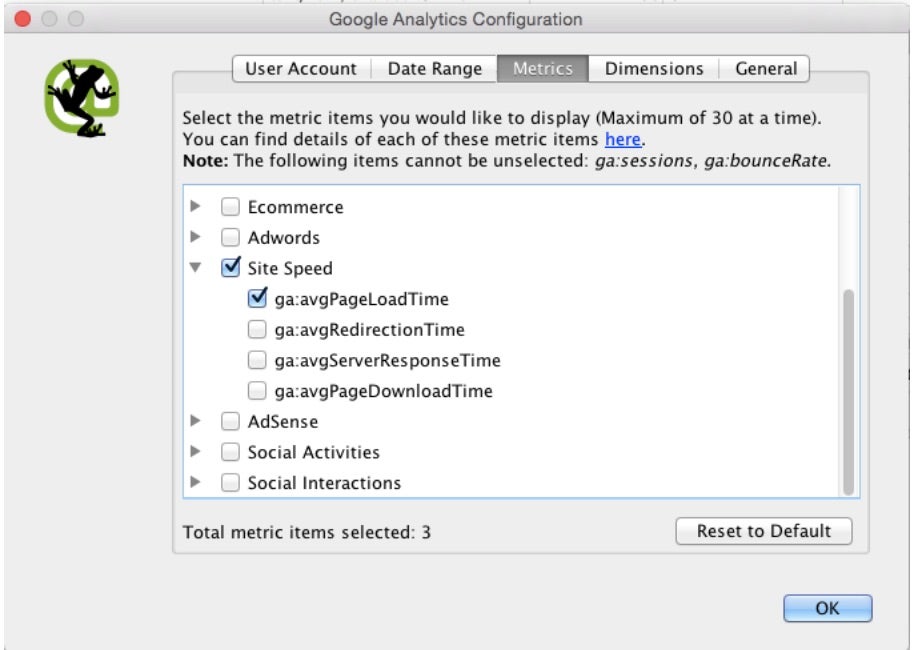
Tipp: Google berechnet standardmäßig die durchschnittliche Ladezeit aus lediglich einem Prozent der Besucher einer Unterseite. Daher solltet ihr die Samplingrate, also die Stichprobengröße, erhöhen.
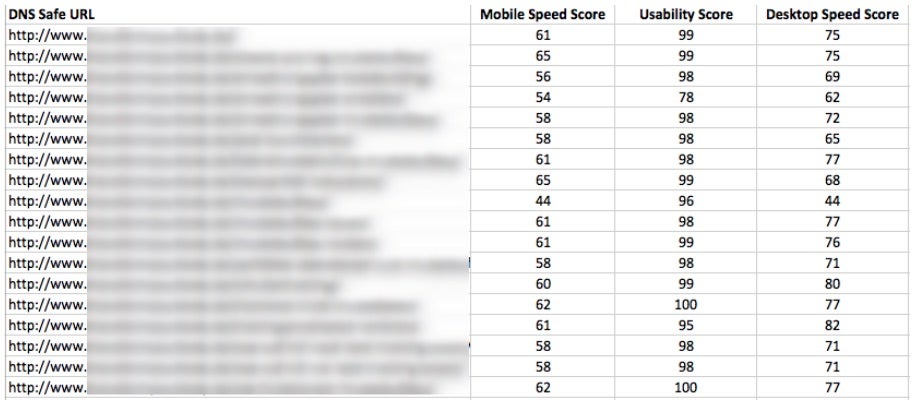
Nach dem Crawl bekommt ihr eine Liste mit den gecrawlten URLs, den dazugehörigen Sessions und der durchschnittlichen Ladezeit gemäß Google Analytics. Mit Hilfe von Excel könnt ihr eine durchschnittliche Ladezeit über alle Unterseiten hinweg berechnen, die Liste so filtern, dass nur URLs angezeigt werden, die die durchschnittliche Ladezeit überschreiten und abschließend diese URLs aufsteigend nach ihrer durchschnittlichen Ladezeit sortieren.
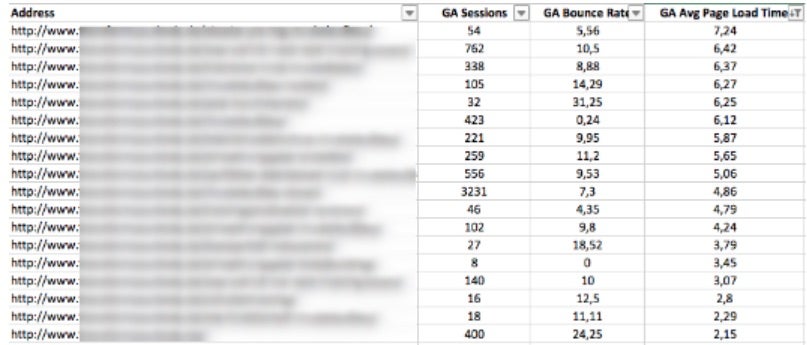
Da die Ladezeit lediglich auf einer Stichprobe basiert, könnt ihr mit Hilfe von URLProfiler (http://urlprofiler.com) und der Google-Page-Speed-API zu allen URLs die Scores und viele weitere Daten exportieren, um die Liste der zu prüfenden Seiten weiter einzugrenzen.
Linkauditing
Bei der Linkauditing-Analyse analysieren wir eine Liste an URLs, auf denen wir verlinkt sein müssten. Mit Hilfe der Methode lässt sich überprüfen, ob eine Verlinkung gesetzt ist, welcher Linktext verwendet wurde und ob der Link mit nofollow deklariert ist.
Beispielhaft könnte die Liste aus einer Linkaufbau-Kampagne stammen oder es könnte eine Liste mit URLs sein, auf denen der Markenname genannt wurde. Dann kann überprüft werden, ob lediglich eine Nennung erfolgt ist oder ob auch verlinkt wurde, um anschließend ein Outreaching nach Links durchzuführen.
Um die Analyse durchführen zu können, muss zunächst der „Mode“ in Screaming Frog auf „List“ umgestellt werden. Anschließend kann man über den Upload-Button die URLs hochladen. Als nächstes wählt ihr unter „Configuration“ im Menüpunkt „Custom“ den Eintrag „Extraction“, um die Extrahierungsfunktion zu konfigurieren. In diesem Fall müssen drei Exctrator per XPath definiert werden. Der erste Extractor extrahiert den href, der zweite den Linktext und der dritte den rel eines Links.
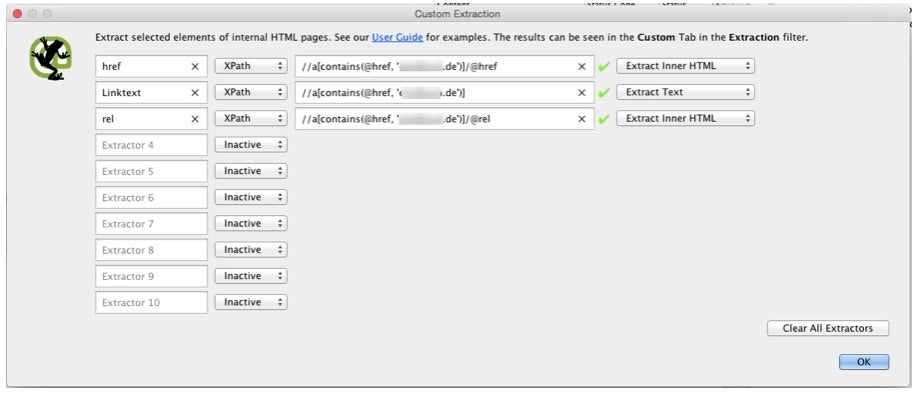
XPath zum Kopieren:
href: //a[contains(@href, 'domain.tld')]/@href
Linktext: //a[contains(@href, 'domain.tld')]
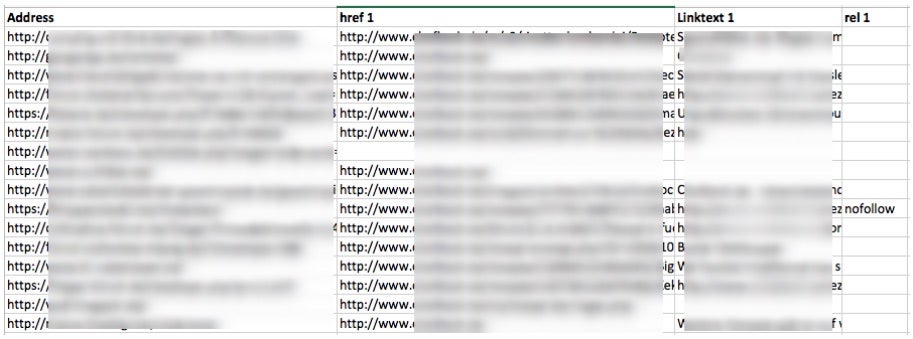
rel: //a[contains(@href, 'domain.tld')]/@relAls Ergebnis erhaltet ihr nach dem Crawl eine Liste mit der jeweiligen URL, dem Link, dem Linktext und dem dazugehörigen rel-Attribut, falls eins vergeben wurde.
Schema.org-Einbindungen per JSON-LD überprüfen
Die Integration von strukturierte Daten in Form von Schema.org-Einbindungen sind mittlerweile in vielen Branchen gang und gäbe. Die Einbindung kann per RDFa, Microdata oder JSON-LD erfolgen. Bei dieser Analyse befassen wir uns mit der Extraktion von Schema.org-Einbindungen, um diese zum Beispiel auf Fehler oder Ergänzungspotenziale zu prüfen.
Wir extrahieren mit Hilfe der „Custom-Extraction“-Funktion den Inhalt zwischen dem JSON-LD-<script></script>-Bereich. Dazu benutzen wir folgenden Regex-Ausdruck:
<script type="application/ld+json">(.*?)</script>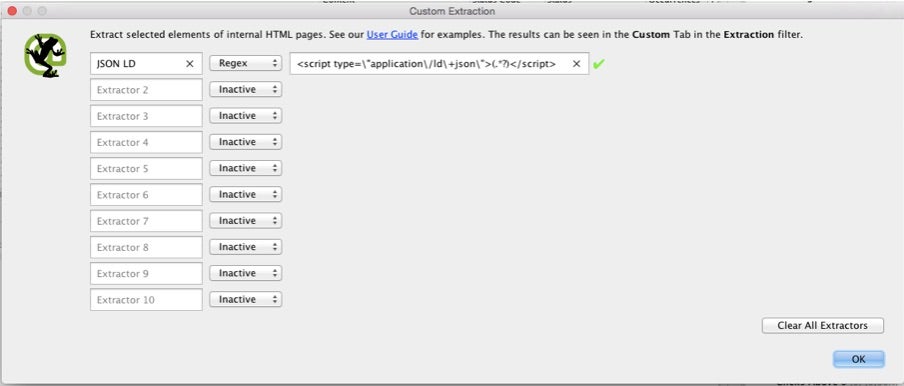
Nach dem Crawl erhalten wir eine Liste, die wie folgt aussieht:
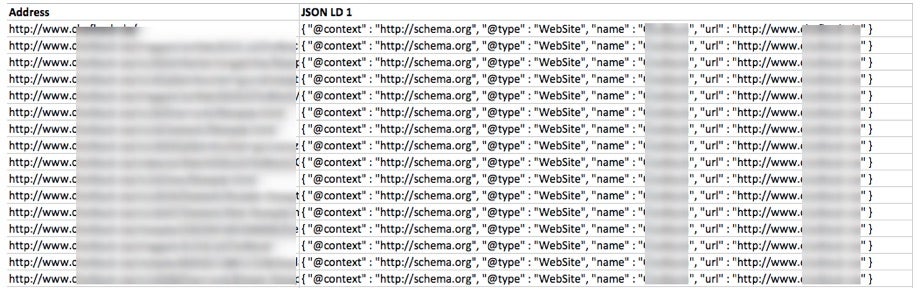
Mithilfe von Excel kann man zur besseren Überprüfung die einzelnen Schema.org-Typen filtern und die jeweiligen Elemente einzelnen Spalten zuordnen.
Open-Graph-Meta-Tags extrahieren
Die Open-Graph-Meta-Tags sind dafür verantwortlich, wie Beiträge in sozialen Netzwerken aussehen, zum Beispiel Facebook-Posts und Twitter-Cards. Dabei kann man über die Open-Graph-Meta-Tags unter anderem einen individuellen Titel, eine individuelle Beschreibung sowie ein Bild, eine URL und einen Typ festlegen.
Auf vielen historisch gewachsenen Webseiten sind entweder gar keine Open-Graph-Meta-Tags verbaut oder sie sind nicht gepflegt. Mit Hilfe von Screaming Frog könnt ihr die gesetzten Tags pro URL extrahieren, um diese zum Beispiel anschließend einer Qualitätsprüfung zu unterziehen.
XPath zum Kopieren:
//meta[starts-with(@property, 'og:title')]/@content
//meta[starts-with(@property, 'og:description')]/@content
//meta[starts-with(@property, 'og:type')]/@content
//meta[starts-with(@property, 'og:image')]/@contentNach dem Crawl bekommt ihr eine Liste mit den Open-Graph-Meta-Tags zu jeder URL.
Die fünf Analysen sind nur ein kleiner Einblick in die Funktionsvielfalt von Screaming Frog. Die Anleitungen sollen zum einen dazu dienen, die Analysen für den eigenen Gebrauch zu adaptieren, aber sie sollen auch als Inspiration dienen, die „Extraction“- sowie „Search“-Funktion in Kombination mit den API-Anbindungen für eigene Anwendungsfälle zu nutzen.
Ebenfalls spannend:
- 9 Praxistipps für Screaming Frog: So nutzt du alle Vorteile des SEO-Tools
- Die 15 besten SEO-Tools, die bis heute nur die Profis kannten
- 15 Dinge, die Webdesigner über SEO wissen sollten

Interessantes Tool, kannte ich bisher noch nicht. Es gibt auf der Seite eine Free-Version, die allerdings einige der hier genannten Features nicht unterstützt. Werde es trotzdem mal testen, danke für den Tipp.
ich benutze regelmäßig screaming frog. Die Funktionen sind so umfangreich. Ich bin sehr begeistert. In sekunden sind Probleme analysiert und gelistet.
Danke für die Erklärung neuer Funktionen. Ich werde sofort umsetzen.