Diese typischen JavaScript-Fehler sollten SEO vermeiden
")
(Bild: Trismegist san/Shutterstock)
Aber egal, wie schön deine Website aussieht – wenn Google sie aufgrund von JavaScript-Fehlern nicht richtig lesen oder indexieren kann, verpasst du viele potenzielle neue Besucher.
Wie geht Google mit JavaScript um?
Um zu verstehen, wie sich JavaScript auf SEO auswirkt, müssen wir verstehen, was genau passiert, wenn der Google-Bot eine Website mit JavaScript-Inhalten crawlt: Zunächst durchsucht der Google-Bot die URL Seite für Seite. Der Crawler sendet eine GET-Request an den Server und der Server sendet dann das HTML-Dokument zurück. Das geschieht meist unter Verwendung eines mobilen Benutzeragenten. Anschließend entscheidet Google, welche Ressourcen zum Rendern des Hauptinhalts der Seite erforderlich sind. Normalerweise bedeutet das, dass nur der statische HTML-Code gecrawlt wird.
Und wie sieht es mit JavaScript aus? Aufgrund verschiedener Faktoren kann die Ausführung und das Rendering von JavaScript-Code oftmals länger dauern. Es ist nicht einmal garantiert, dass JavaScript-Inhalte in den Suchergebnissen erscheinen. Zumindest nicht direkt nach der Veröffentlichung der Inhalte.
Ebenfalls interessant: JavaScript: Node.js 16 unterstützt jetzt Apples M1-Chips
Warum ist das so?
Google kennt inzwischen ungefähr 130 Billionen Dokumente, die im Web verfügbar sind. Das Rendering von JavaScript bei so einem Umfang kann sehr teuer werden. Die Rechenleistung, die zum Herunterladen, Parsen und Ausführen von JavaScript in großen Mengen erforderlich ist, ist enorm. Die Websites, die viel JavaScript beinhalten, stellen Google vor größere Herausforderungen als Websites mit reinem HTML. Bevor die JavaScript-Inhalte indexiert werden, führt Google das JavaScript aus. Hier kommt der Renderer zum Einsatz.
Manchmal werden Inhalte indexiert, bevor sie gerendert sind. Google nimmt in solchen Fällen zunächst die initial vom Server gelieferten Inhalte in den Index auf und aktualisiert sie, wenn genügend Kapazitäten zum Rendern verfügbar sind. Man spricht dabei auch von der zweiten Welle der Indexierung:
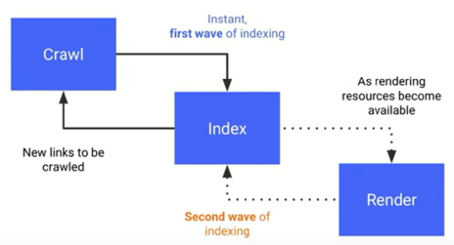
(Quelle: https://www.youtube.com/watch?v=PFwUbgvpdaQ)
Zwischen dem ersten und zweiten Besuch können aber auch mal ein paar Tage bis Wochen liegen. Deshalb kann es bei Inhalten, die von JavaScript zum Rendern abhängig sind, zu Verzögerungen beim Crawlen und Indizieren durch Google kommen.
Wenn der Google-Bot jetzt JavaScript technisch ausführen kann, warum sind dann viele immer noch besorgt über Indizierungsprobleme? Die kurze Antwort lautet „Crawl-Budget“. Google kann nicht alle URL einer Website durchsuchen, da auch die größte Suchmaschine der Welt keine unbegrenzten Ressourcen besitzt. Das Crawl-Budget ist die maximale Anzahl an Seiten, die von einer Internetseite durchsucht werden.
Auch interessant: Diese Programmiersprachen solltet ihr 2021 unbedingt lernen
Wir wissen bereits, dass Google die spätere Ausführung von JavaScript verzögert, um das Crawl-Budget zu sparen. Obwohl die Verzögerung zwischen dem Crawlen und dem Rendern verringert wurde, gibt es keine Garantie dafür, dass Google den in der Warteschlange der Web-Rendering-Services anstehenden JavaScript-Code tatsächlich ausführt.
Typische JavaScript-Fehler auf Websites
Die meisten Probleme mit JavaScript und Suchmaschinenoptimierung treten durch fehlerhafte Implementierungen auf.
Typisch JavaScript Fehler sind …
- Fehlerhafte Links: a href und img src – damit der Google-Bot weitere Seiten finden und indexieren kann, benötigt er interne und externe Links, denen er folgen kann. Diese Links sollten mit dem href- oder dem src-Attribut versehen sein. Verlinkungen per JavaScript sind nicht zu empfehlen, wenn diese so aufgebaut sind wie in den folgenden Beispielen.
- Wie du Links nicht auf der Website einbinden solltest:
- a onclick=”goTo(‘page’)”> (Hier fehlt das href-Attribut.)
- <a href=”javascript:goTo(‘page’)”></a> (Der Link fehlt hier gänzlich.)
- <a href=”javascript:void(0)”> </a> (Auch hier fehlt der Link.)
- <span onclick=”goTo(‘page’)”></span> (Hier handelt es sich um ein falsches HTML-Element.)
- Zugang für alle Bots schaffen: Es gibt Suchmaschinen, die nicht so fortgeschritten in JavaScript-SEO sind wie Google. Damit alle Bots mit deinen JavaScript-Inhalten umgehen können, ist es empfehlenswert, Titel und Meta-Angaben in den HTML-Code zu setzen.
- Kein JS über robots.txt sperren: Achte darauf, dass deine JavaScript-Inhalte auch vom Google-Bot gecrawlt werden dürfen. Hierfür dürfen die Inhalte nicht in der robots.txt ausgeschlossen werden. Der einfachste Weg, um dem Google-Bot das Crawlen der Inhalte zu erlauben, ist es, den folgenden Befehl in deiner robots.txt hinzuzufügen.
User-Agent: Googlebot
Allow: .js
Allow: .css
- Indexierbare URL: Jede Website benötigt einzigartige und unterscheidbare URL, damit die Seiten überhaupt indexiert werden. Ein pushState, wie er bei JavaScript ausgeführt wird, erzeugt jedoch noch keine URL. Deshalb benötigt deine JavaScript-Seite auch ein eigenes Webdokument, das einen Statuscode 200 als Serverantwort auf eine Client- oder Botanfrage ausgeben kann. Jedes mit JavaScript dargestellte Produkt oder jede mit JavaScript realisierte Kategorie auf deiner Website muss deshalb mit einer serverseitigen URL ausgestattet sein, damit deine Seite indexiert werden kann.
- Doppelter Inhalt: Mit JavaScript kann es mehrere URL für den gleichen Inhalt geben, was zu Problemen mit doppelten Inhalten führt. Das kann durch Großschreibung, ID, Parameter mit ID und Ähnliches verursacht werden. Diese URL können also alle existieren:
domain.com/Abc
domain.com/abc
domain.com/123
domain.com/?id=123
Die Lösung ist einfach: Wähle eine Version, die indiziert werden soll, und setze Canonical Tags.
Tools zur Überprüfung von JavaScript
Google Search Console – das URL-Prüfungstool
Ein nützliches Tool für JavaScript-SEO ist das URL-Prüfungstool der Google Search Console. Hier wird in einem Livetest ein Screenshot der gerenderten Seite erstellt. So kannst du sehen, wie der Google-Bot die JavaScript-Inhalte auf deiner Website darstellen würde.
Diesen Screenshot solltest du im Hinblick auf folgende Fragen anschauen:
- Ist mein Hauptinhalt sichtbar?
- Kann Google auf Bereiche wie „Ähnliche Artikel“ oder andere interne Verlinkungen zugreifen?
- Kann Google andere wichtige Elemente der Website sehen?
View Rendered Source Chrome Extension
Für alle Chrome-Nutzer gibt es diese nützliche Erweiterung. Das Tool zeigt dir, wie der Browser eine Seite rendert und nicht nur, was der Server sendet. Hier siehst du den Unterschied zwischen dem Quellcode und dem gerenderten HTML-Code. Es gibt dir einen Überblick darüber, was JavaScript auf deiner Seite ändert:
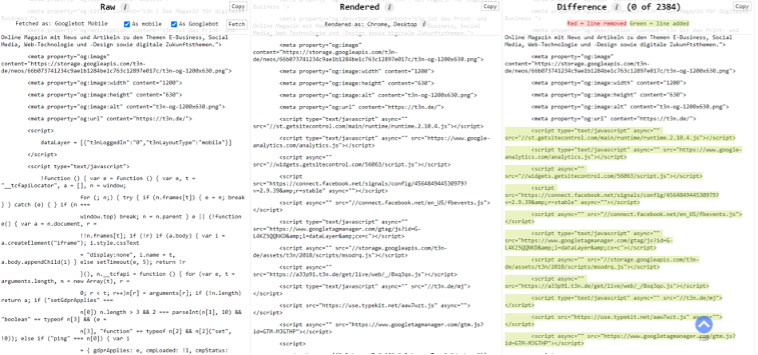
(Screenshot: t3n/Florian Beqiri)
JavaScript Rendering Check
Eine weiteres Online-Tool ist der JavaScript Rendering Check von Searchviu. Das JavaScript-Debugging-Tool ist sehr benutzerfreundlich, da du den Code nicht selbst überprüfen musst. Es prüft die wichtigsten Elemente im Quellcode der Seite für dich und vergleicht sie mit den gleichen Elementen im gerenderten HTML – hier solltest du darauf achten, die mobile Version zu prüfen.
Fazit
JavaScript ist ein Werkzeug, das mit Bedacht eingesetzt werden sollte, aber nichts, wovor sich Websitebetreiber fürchten müssen. Wer versteht, wie sich JavaScript auf Websites auswirken kann und wie man mit JavaScript-SEO besser umgehen kann, kann die Programmiersprache ohne Probleme oder Einbußen im Ranking auf Websites einsetzen.

Ein äußerst wichtiges Thema, welches oft nicht genug beachtet wird.
Vielen Dank für diesen hilfreichen Beitrag!
LG aus der Schweiz
Hi, ich würden die „falsch“ implementierten Verlinkungen nicht als Fehler bezeichnen. Die Voraussetzung für einen Fehler an dieser Stelle ist ja erst dann gegeben, wenn die Seite seoseitig glänzen soll. Und das sollen mitnichten alle Seiten dieser Welt ;-)