Serverless Computing: Deswegen sind Server nicht die Zukunft

Wenn von Cloud-Computing die Rede ist, denken viele vor allem an Software as a Service (SaaS) oder Infrastructure as a Service (IaaS). Das sind in der Tat die wichtigsten Cloud-Segmente, in denen die größten Investitionen getätigt und auch die größten Umsätze erwirtschaftet werden. Doch die dritte Säule des Cloud-Computing, Platform as a Service (PaaS), gewinnt in letzter Zeit immer weiter an Bedeutung. PaaS bietet Softwareentwicklern leistungsstarke Anwendungsplattformen, die virtuelle Server-Instanzen, Datenbanksysteme, Storage-Dienste sowie professionelle Deployment-, Management- und Entwickler-Tools umfassen. Gleichzeitig punkten sie mit flexiblen und transparenten Kosten sowie theoretisch unbegrenzten Skalierungsmöglichkeiten. Durch den Einsatz einer PaaS-Lösung wie etwa Googles App Engine, Heroku oder Jelastic können sich Softwareentwickler besser auf die individuelle Business-Logik ihrer Anwendungen konzentrieren. Denn die vielen, oft komplexen Aufgaben, die mit dem Betrieb einer sicheren, hochverfügbaren und schnell skalierbaren Serverinfrastruktur zusammenhängen, werden von der PaaS-Lösung automatisiert übernommen.
Server-Anwendungen ohne Server
„Serverless Computing“ beziehungsweise „Serverless Infrastructure“ geht noch einen Schritt weiter: Hier wird auf den direkten Einsatz von Servern komplett verzichtet. Dieses innovative IT-Betriebskonzept versetzt Developer in die Lage, Cloud-Anwendungen und -Services erstellen und ausführen zu können, ohne sich um Server und deren Verwaltung kümmern zu müssen. Während sich bei PaaS-Lösungen die Serveradministration und -Skalierung automatisieren lassen, wird bei Serverless Computing die Server-Schicht vollkommen abstrahiert. Dabei wird der Code selbstverständlich weiterhin auf einem bestimmten Anwendungsserver im Hintergrund ausgeführt – doch der Entwickler kommt damit niemals in Berührung. Ob Windows oder Linux, Tomcat, JBoss, Apache, Nginx oder Node.js eingesetzt wird, kann ihm vollkommen egal sein.
Bei serverlosen Infrastrukturen laden Entwickler neben ihrem Code auch eventbasierte Funktionen einfach hoch. Letztere werden beim Eintreten bestimmter vordefinierter Ereignisse ausgeführt – Stichwort „Event-driven Computing“. Funktionen können je nach eingesetzter Serverless-Plattform in verschiedenen Programmiersprachen wie Javascript, PHP oder Java geschrieben werden und definieren, wie auf ein bestimmtes Ereignis reagiert werden soll. So kann auch auf plattformabhängige Services zugegriffen werden. Die Funktionen werden als zustandslose, voneinander unabhängige Transaktionen ausgeführt. Die Infrastruktur-Ressourcen, die für die Datenverarbeitung erforderlich sind, stellt die Plattform automatisch bereit. Entscheidend dabei: Kunden zahlen nur für die Ressourcen, die während der Ausführung ihrer Funktionen verbraucht wurden. Das macht das Pricing noch flexibler als bei PaaS- oder IaaS-Lösungen.
Serverless Computing in der Praxis
Die Anwendungsfälle für serverlose Infrastrukturen sind vielfältig. Entwickler können diese zum Beispiel verwenden, um Funktionen oder Cronjobs als Reaktion auf bestimmte Trigger auszuführen, etwa nach Änderungen an Daten, am Systemstatus oder aufgrund von Benutzeraktionen. So kann man beispielsweise Miniaturbilder automatisiert erstellen, nachdem eine Bilddatei hochgeladen wurde, Videos transkodieren oder Dokumente indizieren. Inzwischen werden in der Praxis aber auch ganze Backend-Systeme auf Basis einer serverlosen Cloud-Infrastruktur aufgebaut, die Desktop- und Mobile-Clients bedienen sowie API-Anfragen von Online-Services von Drittanbietern verarbeiten können.
Warum Serverless Computing die Zukunft ist
Das klingt alles sehr positiv – Serverless Computing hat aber nichtsdestotrotz auch Nachteile. Denn was auf der einen Seite ein großer Vorteil sein kann, nämlich mit dem Server nicht in Kontakt zu kommen, bedeutet auf der anderen Seite aber einen Kontrollverlust. So können beispielsweise keine beliebigen Änderungen an dem Datenbank- oder Betriebssystem vorgenommen werden.
Da jedoch viele Services und Funktionen des im Hintergrund laufenden Servers vom Anbieter abhängig sind, müssten für einen Wechsel der Plattform vor allem die eventbasierten Funktionen neu implementiert werden. Doch stellt man den Aufwand und die Kosten eines möglichen Umzugs, der wohl eher selten vorkommt, dem des Betreiben und Verwalten eines größeren Teils des Server-Systems gegenüber, rechtfertigt dies wohl kaum den Verzicht auf Serverless Computing. Zumal es inzwischen sogar ein Framework gibt, mit dem sich auch dieser Teil abstrahieren lässt. Das erleichtert einen Umzug natürlich immens. Das Framework unterstützt alle gängigen Cloud-Plattformen wie etwa AWS, Google Cloud Platform oder Microsoft Azure.
Dem Nachteil des Kontrollverlustes stehen außerdem viele Vorteile gegenüber:
- Automatisierte Skalierung und Verwaltung der Kapazitäten
- Kostenabrechnung erfolgt über die Nutzung der Ressourcen
- Neue Ressourcen können schnell bereitgestellt werden, und zwar genau dann, wenn sie benötigt werden
- Der Sourcecode steht im Vordergrund und die Verwaltung der Server-Infrastruktur übernimmt die Cloud-Plattform
Mit Letzterem wird eins deutlich: Unternehmen, die auf Serverless Computing setzen, können sich voll und ganz auf die Anwendungsentwicklung konzentrieren. Dadurch könnte auch das klassische Berufsfeld des Server-Admins beziehungsweise ein Teil des IT-Bereichs in solchen Unternehmen wegfallen. Benötigt werden diese dann nur noch beim Cloud-Anbieter. Das alles spart Geld und Zeit – noch mehr als bei den anderen Cloud-Computing-Konzepten IaaS oder PaaS.
Die wichtigsten Anbieter für Serverless Computing
Zu den wichtigsten Vertretern für Serverless Computing zählen wenig überraschend die führenden Cloud-Provider. Das sind vor allem Microsoft mit Azure-Functions, Google mit Cloud-Functions, IBM mit OpenWhisk und allen voran Amazon, das mit Lambda die erste Serverless-Computing-Lösung auf den Markt brachte.
AWS Lambda von Amazon
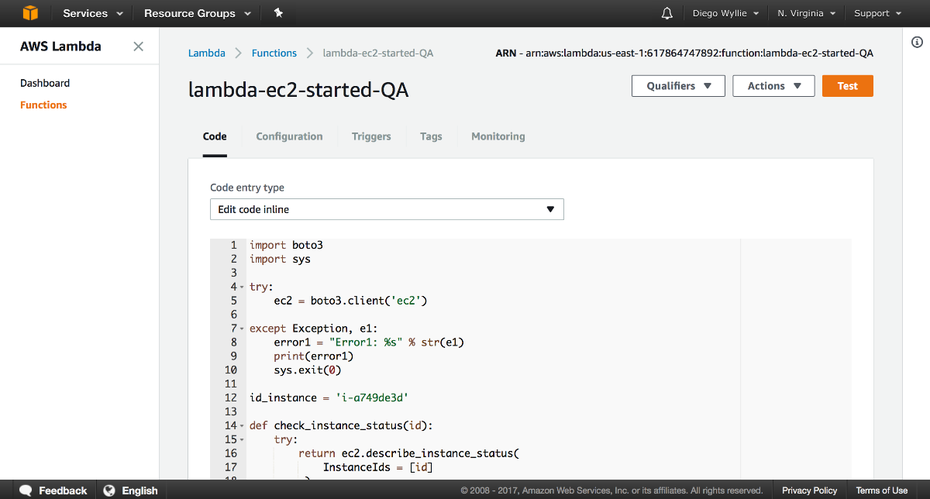
AWS Lambda (Screenshot: Amazon)
AWS Lambda führt Code automatisch auf einer hochverfügbaren Datenverarbeitungsinfrastruktur aus und erledigt die gesamte Administration der Datenverarbeitungsressourcen, einschließlich Server- und Betriebssystemwartung, Kapazitätsbereitstellung und automatischer Skalierung sowie Code- und Sicherheitspatch-Bereitstellung. Entwickler erstellen Lambda-Funktionen im AWS-Dashboard und können diese so einrichten, dass sie automatisch von anderen AWS-Diensten wie S3, DynamoDB oder CloudWatch ausgelöst werden oder von einer beliebigen Web- oder Mobile-App. Praktisch dabei: Mit AWS Step Functions lassen sich komplexere Prozesse durch Koordinieren mehrerer Lambda-Funktionen abbilden. Was die Kosten angeht: Es wird entsprechend der Anzahl der ausgeführten Requests und der Zeit abgerechnet, während der Code ausgeführt wird. Amazon bietet ein kostenloses Kontingent für Lambda, das eine Million Requests und 400.000 GB/s Datenverarbeitungszeit pro Monat umfasst.
Google Cloud Functions

Auch Google bietet mit Cloud-Functions eine Lösung für Serverless Computing an. (Screenshot: t3n.de/Google)
Seit 2016 bietet Google mit Cloud-Functions seine eigene Version von Serverless Computing. Das System hat zwar eine logische Verbindungsschicht, die es Entwicklern ermöglicht, Code zum Verbinden und Erweitern von Google-Cloud-Services zu schreiben. Doch das Angebot richtet sich vor allem an Entwickler, die APIs und Microservices aus einfachen, lose gekoppelten Funktionen erstellen möchten. Dieses neue Lösungsparadigma stellt eines der zentralen Konzepte im Serverless-Computing-Modell dar und fördert die Agilität von Software-Teams, da sie kleine, unabhängige Funktionseinheiten bereitstellen können, die speziell für eine bestimmte Aufgabe ausgelegt sind. Ähnlich wie bei Lambda kann es sich dabei um ereignisgesteuerte oder direkt über HTTP aufgerufene Funktionen handeln. Im Gegensatz zu Amazon hat sich Google allerdings für Javascript als einzige Programmiersprache für die Erstellung von serverlosen Anwendungen entschieden. Diese werden in einer herkömmlichen Node.js-Laufzeitumgebung ausgeführt.
Microsoft Azure Functions
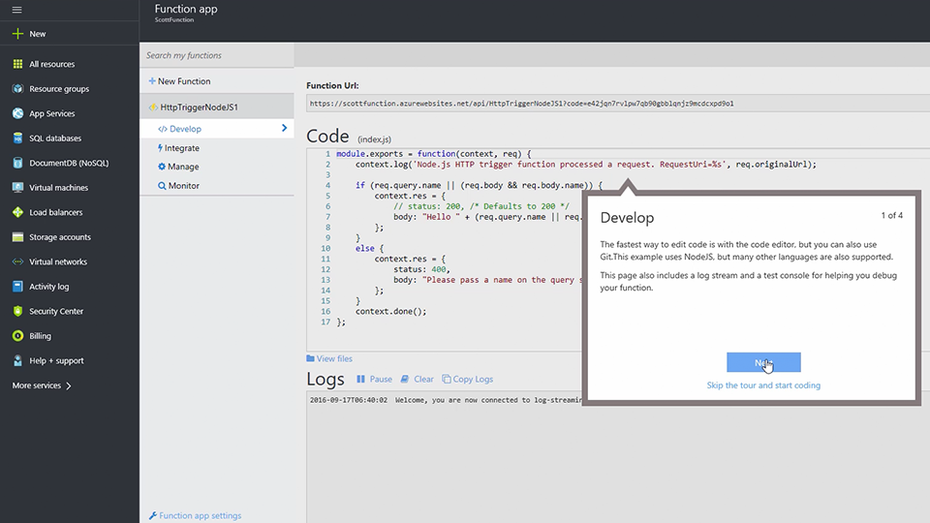
Das Dashboard von Microsoft Azure Functions. (Screenshot: Microsoft)
Wer sich über die Infrastruktur oder die Bereitstellung von Servern keine Gedanken mehr machen möchte, sollte auch einen Blick auf Azure-Functions werfen. Microsoft hat sein Serverless-Computing-Produkt im Jahr 2016 in sein Cloud-Portfolio aufgenommen. Sowohl was die Funktionalität als auch das Pricing angeht, gibt es zwischen Google, Amazon und Microsoft wenige Unterschiede. Die Redmonder punkten jedoch mit einer größeren Auswahl an Programmiersprachen und adressieren somit ein breiteres Publikum als Google. Azure-Functions lassen sich in Javascript, C# oder F# und mit verschiedenen Skripterstellungsoptionen wie Python, PHP, Bash, Batch und PowerShell erstellen. Praktisch dabei: Anwender können auch vorkompilierten Code hochladen und ausführen, den sie mit ihrem bevorzugten Entwicklungstool erstellt haben. Dies zeigt, dass sich Microsoft besonders bemüht, den Einstieg in die Serverless-Computing-Welt so einfach wie möglich zu machen.
Fazit
Serverless Computing stellt eine weitere Abstraktionsschicht bei der Entwicklung von Backend-Systemen dar, bei der traditionelle Konzepte wie Anwendungsserver oder Laufzeitumgebungen vollkommen verschwinden – ganz nach dem Motto „Run code, not servers“. Dadurch können sich Unternehmen die komplexe Administration der Server-Infrastruktur, die für die Ausführung ihrer Anwendungen erforderlich ist, ersparen. Außerdem sparen sie auch Geld. Denn das Pricing ist noch flexibler, als bei den IaaS- und PaaS-Angeboten: Man zahlt nur dann, wenn der Code tatsächlich ausgeführt wird. Dank dieser Zeit- und Kostenersparnisse können sich Entwickler stärker auf ihre eigentliche Arbeit konzentrieren und bessere Software entwickeln.

The trend of mobility is also being pushed by this uprise of serverless computing. Having the access to the information and apps from any device is what will every organization wants. Reducing the cost of server maintenance will be one priority.
Es sind natürlich auch bei Serverless Server im Spiel. Die Aussage „Hier wird auf den direkten Einsatz von Servern komplett verzichtet“ ist falsch und führt zumindest bei mir dazu, dass ich das Lesen des Artikels an der Stelle abbreche.