
„Wie teuer sind die 2 Bier?“: Wie gut Apples KI-Modell MM1 aus Bildern Schlüsse zieht
Apples erstes leistungsfähiges Large Language Modell MM1 soll in einige Belangen auf einem Niveau mit Gemini und ChatGPT sein. (Bild: Picture Alliance, dpa)
Generative KI soll laut Apple-Chef Tim Cook ein „integraler Bestandteil“ der Produkte werden und noch in diesem Jahr in ersten Geräten Einzug halten. Sie soll sogar die Art und Weise verändern, wie wir mit dem iPhone umgehen.
In den letzten Monaten hat Apple bereits zahlreiche KI-Tools angekündigt und Forschungsergebnisse veröffentlicht, die stark auf On-Device-Berechnungen abzielen. Die Veröffentlichung der Forschung an MM1 zeigt, dass Apple nicht unbedingt auf die Hilfe von Google Gemini oder OpenAI’s ChatGPT angewiesen ist, wie kürzlich berichtet wurde.
MM1 soll sich mit GPT-4 messen können
Denn Apple hat mit MM1 ein multimodales KI-Modell entwickelt, das durch umfangreiches Training mit Bild- und Textdaten eine hohe Leistungsfähigkeit erreicht haben soll. Dass Apple viel Geld in das Training seiner KI-Modelle investiert, ist seit einiger Zeit bekannt. Im September 2023 hieß es, der Konzern investiere täglich Millionen von US-Dollar in Forschung und Training.
Laut Forschungsbericht ist MM1 das erste multimodale KI-Modell von Apple, das in einigen Tests mit OpenAIs GPT-4-Vision und Googles Gemini konkurrieren kann. Wie die Modelle der Konkurrenten basiert MM1 auf einer so genannten Transformer-Architektur.
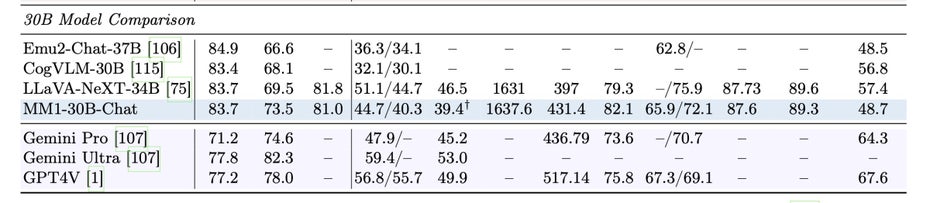
MM1 schneidet im Benchmark-Vergleich mit ChatGPT4 und Gemini gut ab. (Screenshot: B. McKinzie et al.)
Trainiert wurde das LLM laut Apple mit einer Mischung aus Bild-Text-Paaren, Dokumenten mit Text und Bildern sowie reinen Textdaten. Das Forscherteam fand unter anderem heraus, dass der Bildkodierer (also gewissermaßen die Bilderkennung) zusammen mit der Bildauflösung und der Anzahl der Bildtoken einen signifikanten Einfluss auf das Ergebnis hat, während das Design des „Vision-Language-Connectors von vergleichsweise vernachlässigbarer Bedeutung“ ist.
MM1 stark in komplexeren Szenarien
Mithilfe der Skalierung der „Rezept“-Kombination konnten die Apple-Forscher:innen „eine Familie von multimodalen Modellen mit bis zu 30 Milliarden Parametern“ erschaffen. Durch das Zusammenspiel von „dichten Modellen“ sowie „Mixture-of-Experts (MoE)-Varianten“ und „nach überwachtem Feintuning“ lieferte MM1 laut den Forscher:innen „eine konkurrenzfähige Leistung in einer Reihe von etablierten multimodalen Benchmarks“.
Durch ein „umfangreiches Pre-Training“ verfüge MM1 über ein verbessertes kontextbezogenes Lernen und Multi-Image-Reasoning, das eine Denkkette mit wenigen Schritten ermögliche.
Auch in komplexeren Szenarien spiele MM1 seine Stärken aus. Es könne Informationen aus mehreren Bildern kombinieren, um komplexe Fragen zu beantworten oder Schlussfolgerungen zu ziehen, die sich aus einem einzelnen Bild nicht ableiten lassen. In einem der Beispiele kombiniert die KI ein Foto mit zwei Bierflaschen und der Speisekarte. Anhand dieser Informationen kann MM1 berechnen, wie viel man für die beiden Flaschen bezahlen muss.

Apples MM1 kann dem Forschungspapier zufolge den Inhalt mehrerer Bilder kombinieren. So soll die KI zum Beispiel den Preis von zwei Flaschen Bier auf dem Tisch mithilfe der Speisekarte ermitteln können. (Screenshot: B. McKinzie et al.)
Der Artikel erklärt weiter, dass MM1 in der Lage sein soll, aus dem Kontext zu lernen und Probleme in mehreren Schritten zu lösen. Es sieht so aus, als ob das Modell sich „erinnern“ kann, was kurz zuvor besprochen wurde, und entsprechend reagiert.
Klarheit über Apples KI-Strategie erst im Sommer
Noch ist MM1 bei Apple unter Verschluss, sodass wir uns vorerst auf die Ergebnisse des Forschungsberichts verlassen müssen. In welcher Form das Multimodal Large Language Model zukünftig in Produkten eingesetzt wird, ist ebenfalls unklar. Es ist jedoch absehbar, dass der Konzern im Rahmen der World-Wide-Developers-Conference, kurz WWDC, die voraussichtlich Anfang Juni stattfinden wird, seine KI-Strategie kommunizieren wird.
Berichten zufolge wird Apple das nächste große Softwareupdate für das iPhone in Form von iOS 18 massiv mit KI füllen. Aber auch macOS 15 und andere OS-Plattformen werden nicht leer ausgehen. Da die iPhones nach wie vor Apples große Cash-Cow sind, wird sich der KI-Fokus tendenziell auf diese Gerätekategorie konzentrieren. Es ist indes durchaus möglich, dass Apple einige der kommenden KI-Funktionen dem iPhone 16 Pro exklusiv vorbehält.
